 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Class-Incremental Learning from an Open-Set Perspective
Jul 30, 2022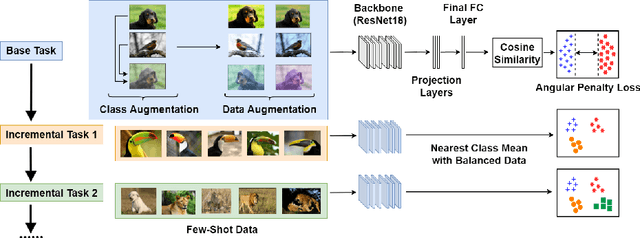
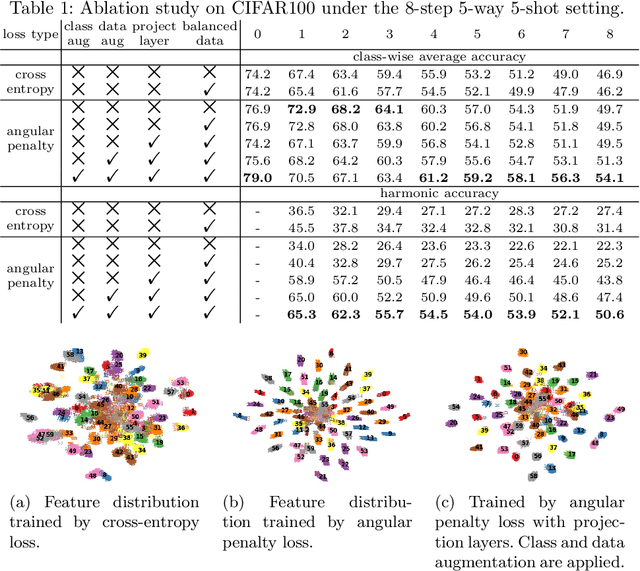
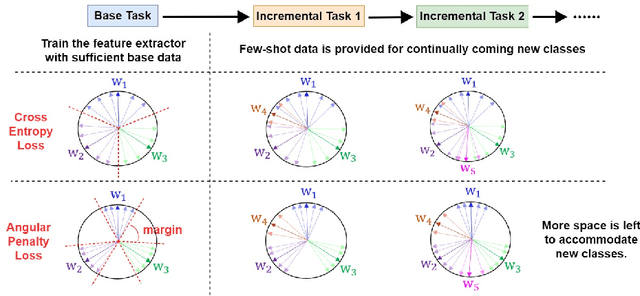
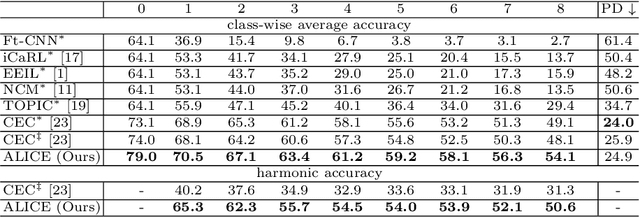
The continual appearance of new objects in the visual world poses considerable challenges for current deep learning methods in real-world deployments. The challenge of new task learning is often exacerbated by the scarcity of data for the new categories due to rarity or cost. Here we explore the important task of Few-Shot Class-Incremental Learning (FSCIL) and its extreme data scarcity condition of one-shot. An ideal FSCIL model needs to perform well on all classes, regardless of their presentation order or paucity of data. It also needs to be robust to open-set real-world conditions and be easily adapted to the new tasks that always arise in the field. In this paper, we first reevaluate the current task setting and propose a more comprehensive and practical setting for the FSCIL task. Then, inspired by the similarity of the goals for FSCIL and modern face recognition systems, we propose our method -- Augmented Angular Loss Incremental Classification or ALICE. In ALICE, instead of the commonly used cross-entropy loss, we propose to use the angular penalty loss to obtain well-clustered features. As the obtained features not only need to be compactly clustered but also diverse enough to maintain generalization for future incremental classes, we further discuss how class augmentation, data augmentation, and data balancing affect classification performance. Experiments on benchmark datasets, including CIFAR100, miniImageNet, and CUB200, demonstrate the improved performance of ALICE over the state-of-the-art FSCIL methods.
FaceCook: Face Generation Based on Linear Scaling Factors
Sep 08, 2021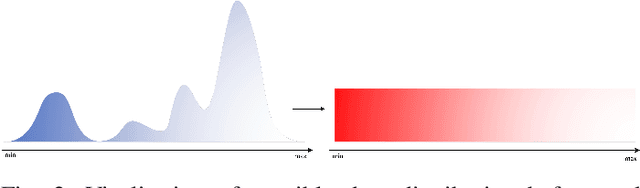

With the excellent disentanglement properties of state-of-the-art generative models, image editing has been the dominant approach to control the attributes of synthesised face images. However, these edited results often suffer from artifacts or incorrect feature rendering, especially when there is a large discrepancy between the image to be edited and the desired feature set. Therefore, we propose a new approach to mapping the latent vectors of the generative model to the scaling factors through solving a set of multivariate linear equations. The coefficients of the equations are the eigenvectors of the weight parameters of the pre-trained model, which form the basis of a hyper coordinate system. The qualitative and quantitative results both show that the proposed method outperforms the baseline in terms of image diversity. In addition, the method is much more time-efficient because you can obtain synthesised images with desirable features directly from the latent vectors, rather than the former process of editing randomly generated images requiring many processing steps.
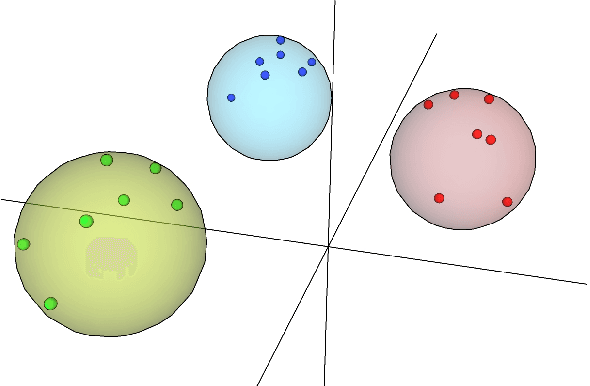
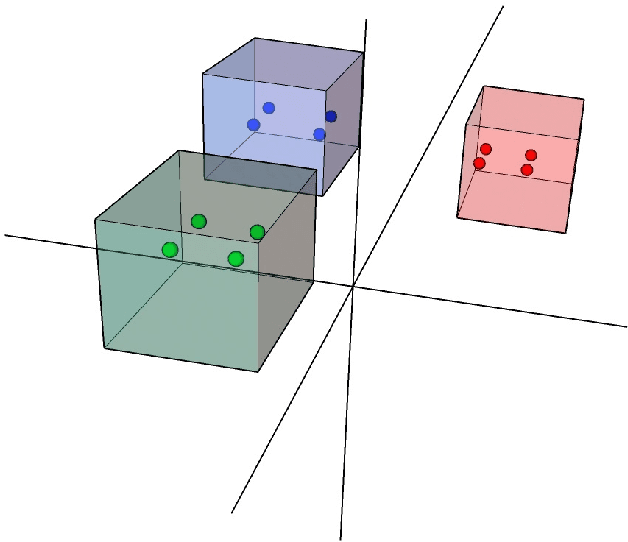
DIODE: Dilatable Incremental Object Detection
Aug 12, 2021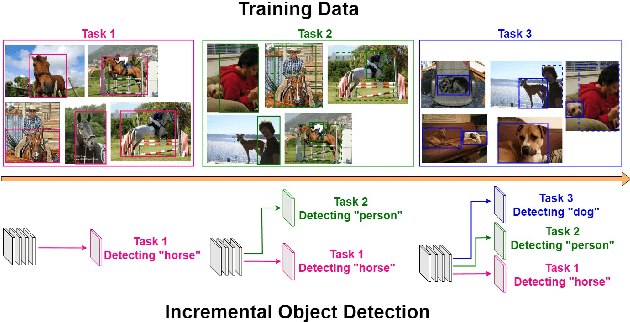
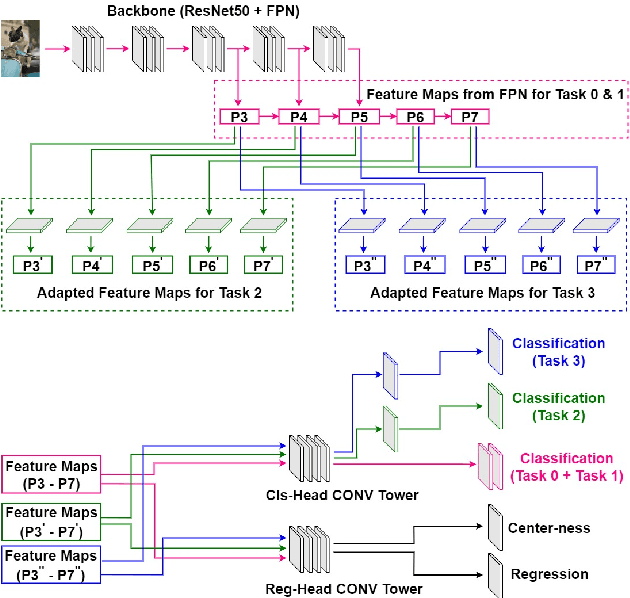
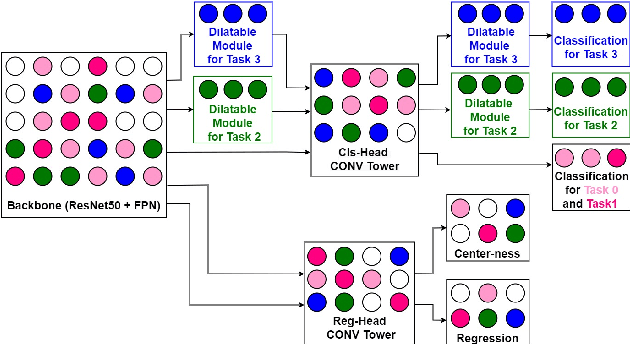
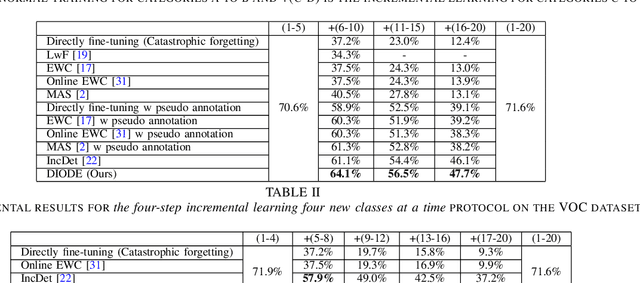
To accommodate rapid changes in the real world, the cognition system of humans is capable of continually learning concepts. On the contrary, conventional deep learning models lack this capability of preserving previously learned knowledge. When a neural network is fine-tuned to learn new tasks, its performance on previously trained tasks will significantly deteriorate. Many recent works on incremental object detection tackle this problem by introducing advanced regularization. Although these methods have shown promising results, the benefits are often short-lived after the first incremental step. Under multi-step incremental learning, the trade-off between old knowledge preserving and new task learning becomes progressively more severe. Thus, the performance of regularization-based incremental object detectors gradually decays for subsequent learning steps. In this paper, we aim to alleviate this performance decay on multi-step incremental detection tasks by proposing a dilatable incremental object detector (DIODE). For the task-shared parameters, our method adaptively penalizes the changes of important weights for previous tasks. At the same time, the structure of the model is dilated or expanded by a limited number of task-specific parameters to promote new task learning. Extensive experiments on PASCAL VOC and COCO datasets demonstrate substantial improvements over the state-of-the-art methods. Notably, compared with the state-of-the-art methods, our method achieves up to 6.0% performance improvement by increasing the number of parameters by just 1.2% for each newly learned task.
Faces à la Carte: Text-to-Face Generation via Attribute Disentanglement
Jun 13, 2020
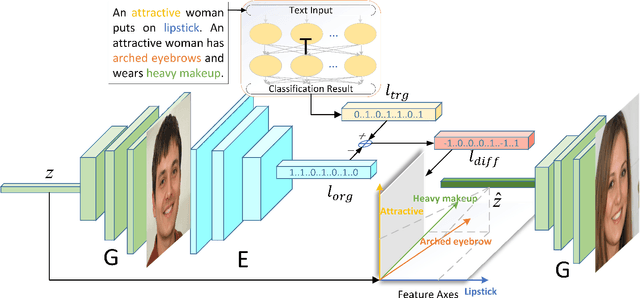


Text-to-Face (TTF) synthesis is a challenging task with great potential for diverse computer vision applications. Compared to Text-to-Image (TTI) synthesis tasks, the textual description of faces can be much more complicated and detailed due to the variety of facial attributes and the parsing of high dimensional abstract natural language. In this paper, we propose a Text-to-Face model that not only produces images in high resolution (1024x1024) with text-to-image consistency, but also outputs multiple diverse faces to cover a wide range of unspecified facial features in a natural way. By fine-tuning the multi-label classifier and image encoder, our model obtains the vectors and image embeddings which are used to transform the input noise vector sampled from the normal distribution. Afterwards, the transformed noise vector is fed into a pre-trained high-resolution image generator to produce a set of faces with the desired facial attributes. We refer to our model as TTF-HD. Experimental results show that TTF-HD generates high-quality faces with state-of-the-art performance.