 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-aware Triplet loss in Domain Generalization
Mar 01, 2023



Despite much progress being made in the field of object recognition with the advances of deep learning, there are still several factors negatively affecting the performance of deep learning models. Domain shift is one of these factors and is caused by discrepancies in the distributions of the testing and training data. In this paper, we focus on the problem of compact feature clustering in domain generalization to help optimize the embedding space from multi-domain data. We design a domainaware triplet loss for domain generalization to help the model to not only cluster similar semantic features, but also to disperse features arising from the domain. Unlike previous methods focusing on distribution alignment, our algorithm is designed to disperse domain information in the embedding space. The basic idea is motivated based on the assumption that embedding features can be clustered based on domain information, which is mathematically and empirically supported in this paper. In addition, during our exploration of feature clustering in domain generalization, we note that factors affecting the convergence of metric learning loss in domain generalization are more important than the pre-defined domains. To solve this issue, we utilize two methods to normalize the embedding space, reducing the internal covariate shift of the embedding features. The ablation study demonstrates the effectiveness of our algorithm. Moreover, the experiments on the benchmark datasets, including PACS, VLCS and Office-Home, show that our method outperforms related methods focusing on domain discrepancy. In particular, our results on RegnetY-16 are significantly better than state-of-the-art methods on the benchmark datasets. Our code will be released at https://github.com/workerbcd/DCT
End to End Generative Meta Curriculum Learning For Medical Data Augmentation
Dec 20, 2022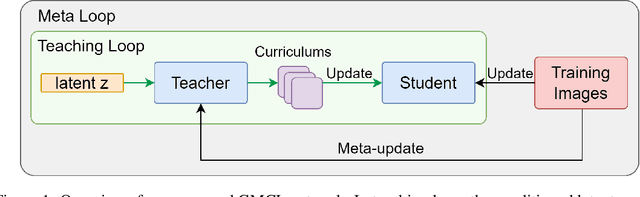
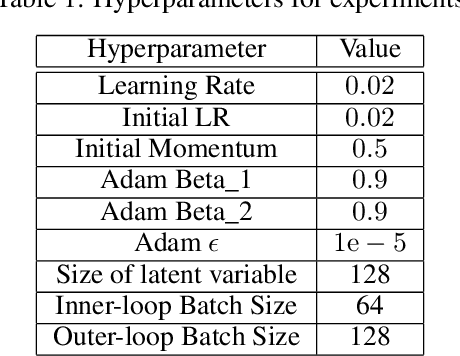
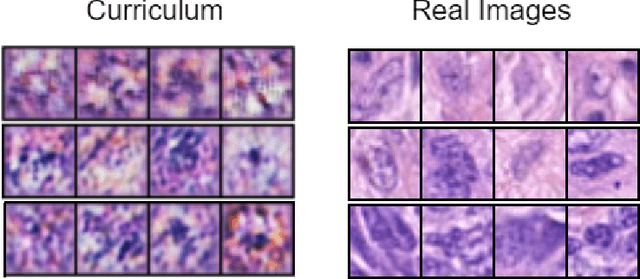
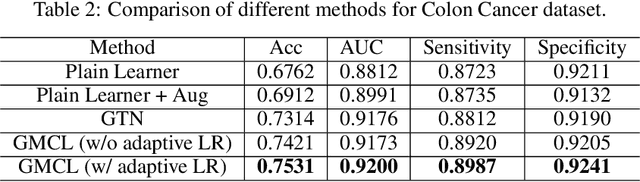
Current medical image synthetic augmentation techniques rely on intensive use of generative adversarial networks (GANs). However, the nature of GAN architecture leads to heavy computational resources to produce synthetic images and the augmentation process requires multiple stages to complete. To address these challenges, we introduce a novel generative meta curriculum learning method that trains the task-specific model (student) end-to-end with only one additional teacher model. The teacher learns to generate curriculum to feed into the student model for data augmentation and guides the student to improve performance in a meta-learning style. In contrast to the generator and discriminator in GAN, which compete with each other, the teacher and student collaborate to improve the student's performance on the target tasks. Extensive experiments on the histopathology datasets show that leveraging our framework results in significant and consistent improvements in classification performance.
Conditioned Generative Transformers for Histopathology Image Synthetic Augmentation
Dec 20, 2022



Deep learning networks have demonstrated state-of-the-art performance on medical image analysis tasks. However, the majority of the works rely heavily on abundantly labeled data, which necessitates extensive involvement of domain experts. Vision transformer (ViT) based generative adversarial networks (GANs) recently demonstrated superior potential in general image synthesis, yet are less explored for histopathology images. In this paper, we address these challenges by proposing a pure ViT-based conditional GAN model for histopathology image synthetic augmentation. To alleviate training instability and improve generation robustness, we first introduce a conditioned class projection method to facilitate class separation. We then implement a multi-loss weighing function to dynamically balance the losses between classification tasks. We further propose a selective augmentation mechanism to actively choose the appropriate generated images and bring additional performance improvements. Extensive experiments on the histopathology datasets show that leveraging our synthetic augmentation framework results in significant and consistent improvements in classification performance.
FaceCook: Face Generation Based on Linear Scaling Factors
Sep 08, 2021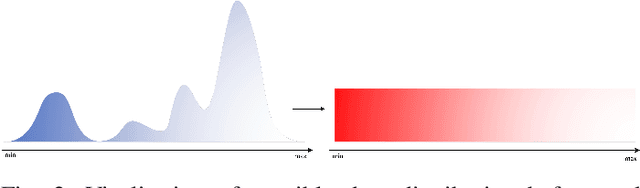
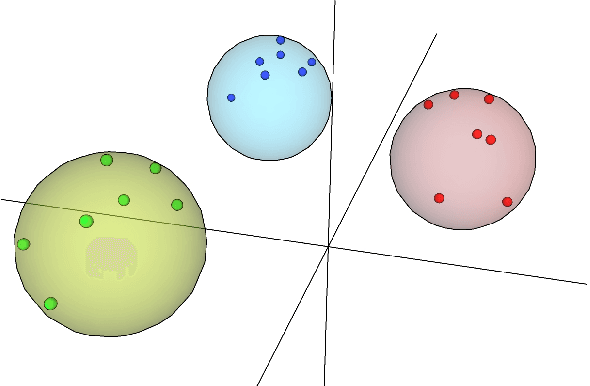
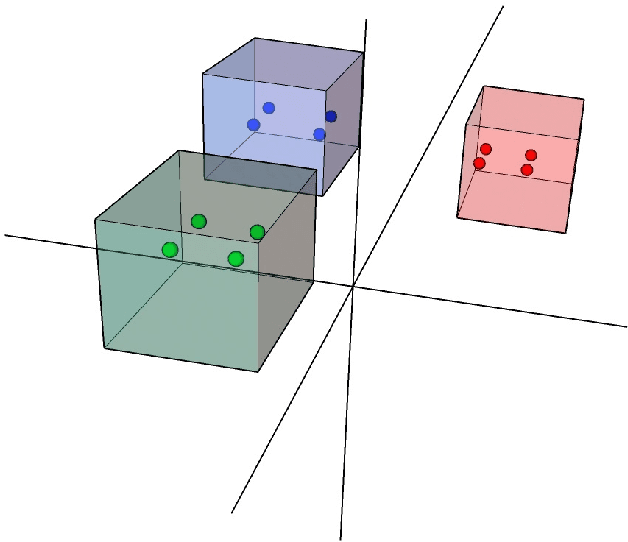

With the excellent disentanglement properties of state-of-the-art generative models, image editing has been the dominant approach to control the attributes of synthesised face images. However, these edited results often suffer from artifacts or incorrect feature rendering, especially when there is a large discrepancy between the image to be edited and the desired feature set. Therefore, we propose a new approach to mapping the latent vectors of the generative model to the scaling factors through solving a set of multivariate linear equations. The coefficients of the equations are the eigenvectors of the weight parameters of the pre-trained model, which form the basis of a hyper coordinate system. The qualitative and quantitative results both show that the proposed method outperforms the baseline in terms of image diversity. In addition, the method is much more time-efficient because you can obtain synthesised images with desirable features directly from the latent vectors, rather than the former process of editing randomly generated images requiring many processing steps.
Faces à la Carte: Text-to-Face Generation via Attribute Disentanglement
Jun 13, 2020
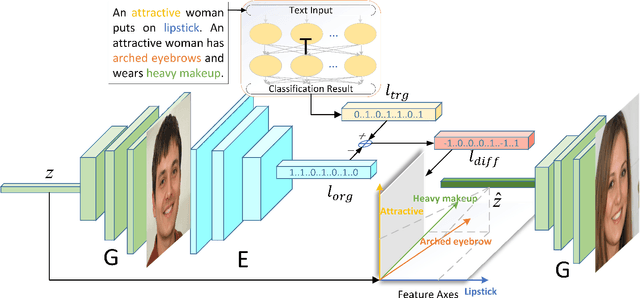


Text-to-Face (TTF) synthesis is a challenging task with great potential for diverse computer vision applications. Compared to Text-to-Image (TTI) synthesis tasks, the textual description of faces can be much more complicated and detailed due to the variety of facial attributes and the parsing of high dimensional abstract natural language. In this paper, we propose a Text-to-Face model that not only produces images in high resolution (1024x1024) with text-to-image consistency, but also outputs multiple diverse faces to cover a wide range of unspecified facial features in a natural way. By fine-tuning the multi-label classifier and image encoder, our model obtains the vectors and image embeddings which are used to transform the input noise vector sampled from the normal distribution. Afterwards, the transformed noise vector is fed into a pre-trained high-resolution image generator to produce a set of faces with the desired facial attributes. We refer to our model as TTF-HD. Experimental results show that TTF-HD generates high-quality faces with state-of-the-art performance.
SOS: Selective Objective Switch for Rapid Immunofluorescence Whole Slide Image Classification
Mar 11, 2020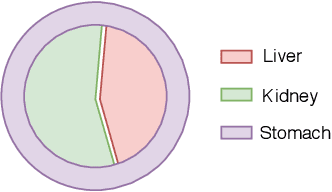
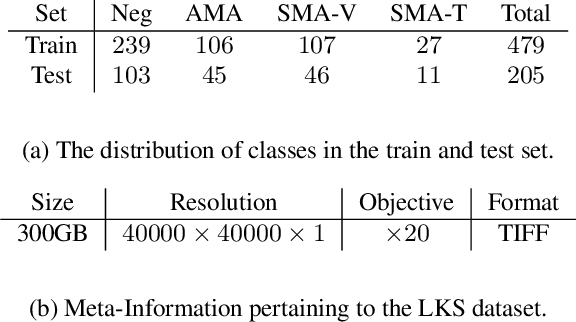
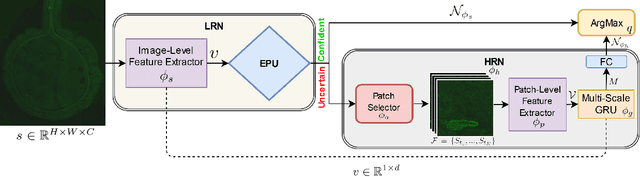
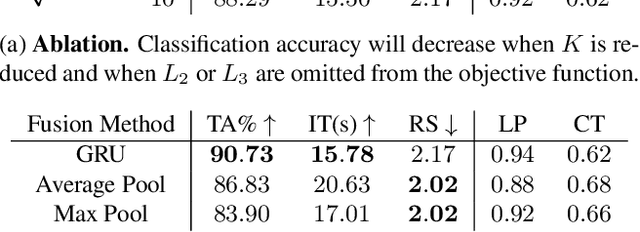
The difficulty of processing gigapixel whole slide images (WSIs) in clinical microscopy has been a long-standing barrier to implementing computer aided diagnostic systems. Since modern computing resources are unable to perform computations at this extremely large scale, current state of the art methods utilize patch-based processing to preserve the resolution of WSIs. However, these methods are often resource intensive and make significant compromises on processing time. In this paper, we demonstrate that conventional patch-based processing is redundant for certain WSI classification tasks where high resolution is only required in a minority of cases. This reflects what is observed in clinical practice; where a pathologist may screen slides using a low power objective and only switch to a high power in cases where they are uncertain about their findings. To eliminate these redundancies, we propose a method for the selective use of high resolution processing based on the confidence of predictions on downscaled WSIs --- we call this the Selective Objective Switch (SOS). Our method is validated on a novel dataset of 684 Liver-Kidney-Stomach immunofluorescence WSIs routinely used in the investigation of autoimmune liver disease. By limiting high resolution processing to cases which cannot be classified confidently at low resolution, we maintain the accuracy of patch-level analysis whilst reducing the inference time by a factor of 7.74.
Deep inspection: an electrical distribution pole parts study via deep neural networks
Jul 16, 2019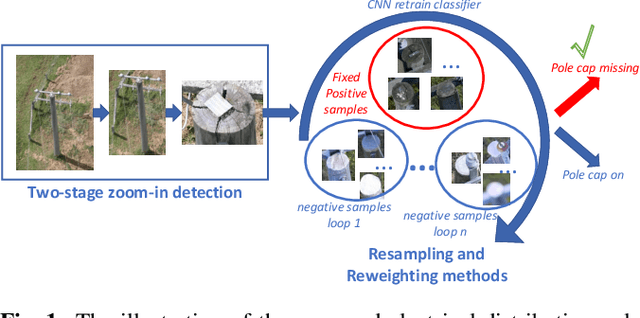

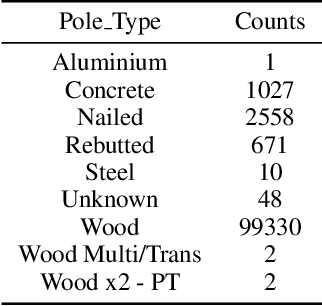

Electrical distribution poles are important assets in electricity supply. These poles need to be maintained in good condition to ensure they protect community safety, maintain reliability of supply, and meet legislative obligations. However, maintaining such a large volumes of assets is an expensive and challenging task. To address this, recent approaches utilise imagery data captured from helicopter and/or drone inspections. Whilst reducing the cost for manual inspection, manual analysis on each image is still required. As such, several image-based automated inspection systems have been proposed. In this paper, we target two major challenges: tiny object detection and extremely imbalanced datasets, which currently hinder the wide deployment of the automatic inspection. We propose a novel two-stage zoom-in detection method to gradually focus on the object of interest. To address the imbalanced dataset problem, we propose the resampling as well as reweighting schemes to iteratively adapt the model to the large intra-class variation of major class and balance the contributions to the loss from each class. Finally, we integrate these components together and devise a novel automatic inspection framework. Extensive experiments demonstrate that our proposed approaches are effective and can boost the performance compared to the baseline methods.
Joint Recognition and Segmentation of Actions via Probabilistic Integration of Spatio-Temporal Fisher Vectors
Oct 04, 2016


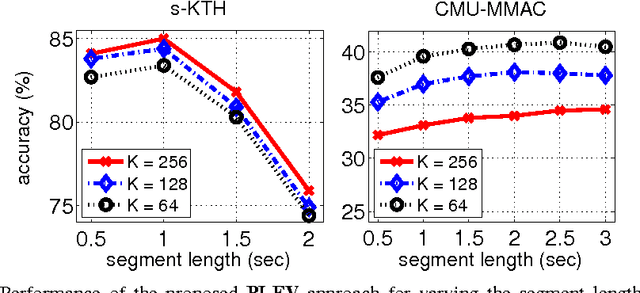
We propose a hierarchical approach to multi-action recognition that performs joint classification and segmentation. A given video (containing several consecutive actions) is processed via a sequence of overlapping temporal windows. Each frame in a temporal window is represented through selective low-level spatio-temporal features which efficiently capture relevant local dynamics. Features from each window are represented as a Fisher vector, which captures first and second order statistics. Instead of directly classifying each Fisher vector, it is converted into a vector of class probabilities. The final classification decision for each frame is then obtained by integrating the class probabilities at the frame level, which exploits the overlapping of the temporal windows. Experiments were performed on two datasets: s-KTH (a stitched version of the KTH dataset to simulate multi-actions), and the challenging CMU-MMAC dataset. On s-KTH, the proposed approach achieves an accuracy of 85.0%, significantly outperforming two recent approaches based on GMMs and HMMs which obtained 78.3% and 71.2%, respectively. On CMU-MMAC, the proposed approach achieves an accuracy of 40.9%, outperforming the GMM and HMM approaches which obtained 33.7% and 38.4%, respectively. Furthermore, the proposed system is on average 40 times faster than the GMM based approach.
Comparative Evaluation of Action Recognition Methods via Riemannian Manifolds, Fisher Vectors and GMMs: Ideal and Challenging Conditions
Oct 04, 2016
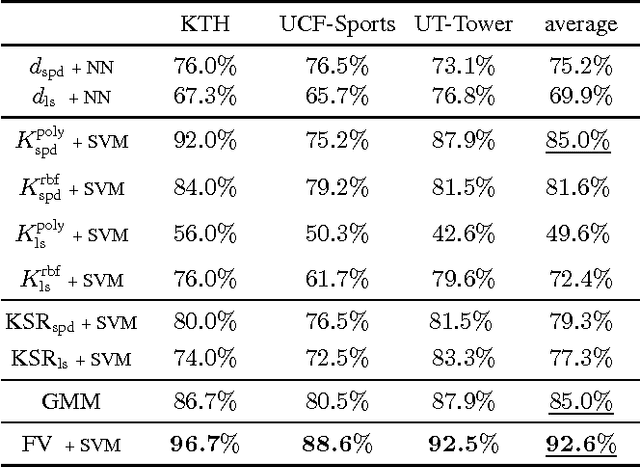

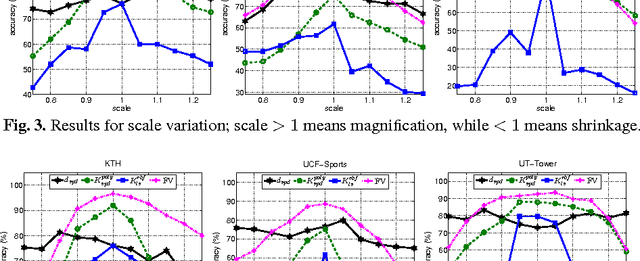
We present a comparative evaluation of various techniques for action recognition while keeping as many variables as possible controlled. We employ two categories of Riemannian manifolds: symmetric positive definite matrices and linear subspaces. For both categories we use their corresponding nearest neighbour classifiers, kernels, and recent kernelised sparse representations. We compare against traditional action recognition techniques based on Gaussian mixture models and Fisher vectors (FVs). We evaluate these action recognition techniques under ideal conditions, as well as their sensitivity in more challenging conditions (variations in scale and translation). Despite recent advancements for handling manifolds, manifold based techniques obtain the lowest performance and their kernel representations are more unstable in the presence of challenging conditions. The FV approach obtains the highest accuracy under ideal conditions. Moreover, FV best deals with moderate scale and translation changes.
Towards Miss Universe Automatic Prediction: The Evening Gown Competition
Sep 12, 2016

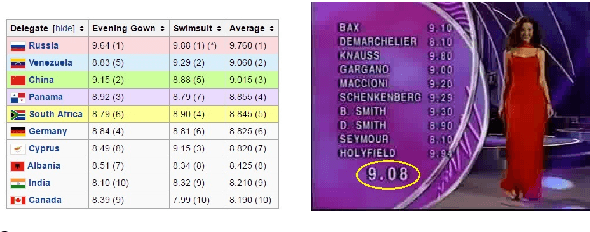
Can we predict the winner of Miss Universe after watching how they stride down the catwalk during the evening gown competition? Fashion gurus say they can! In our work, we study this question from the perspective of computer vision. In particular, we want to understand whether existing computer vision approaches can be used to automatically extract the qualities exhibited by the Miss Universe winners during their catwalk. This study can pave the way towards new vision-based applications for the fashion industry. To this end, we propose a novel video dataset, called the Miss Universe dataset, comprising 10 years of the evening gown competition selected between 1996-2010. We further propose two ranking-related problems: (1) Miss Universe Listwise Ranking and (2) Miss Universe Pairwise Ranking. In addition, we also develop an approach that simultaneously addresses the two proposed problems. To describe the videos we employ the recently proposed Stacked Fisher Vectors in conjunction with robust local spatio-temporal features. From our evaluation we found that although the addressed problems are extremely challenging, the proposed system is able to rank the winner in the top 3 best predicted scores for 5 out of 10 Miss Universe competitions.