 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-induced multiscale losses and efficient multirate gradient descent schemes
Feb 06, 2024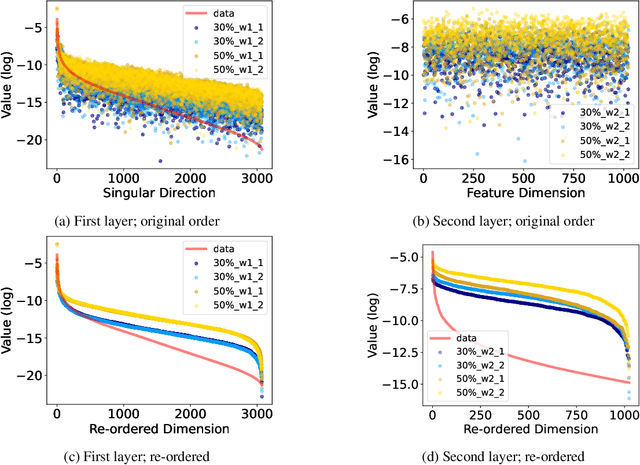
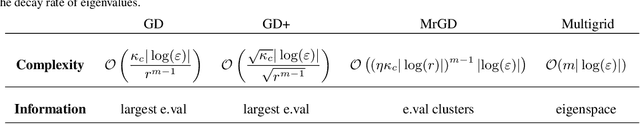
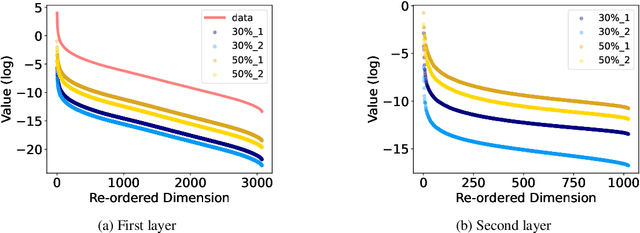
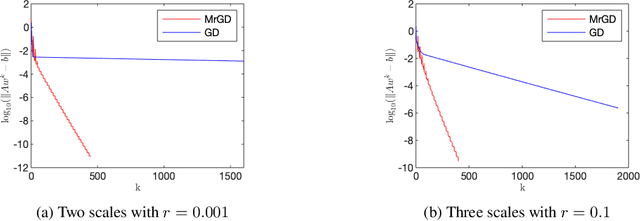
This paper investigates the impact of multiscale data on machine learning algorithms, particularly in the context of deep learning. A dataset is multiscale if its distribution shows large variations in scale across different directions. This paper reveals multiscale structures in the loss landscape, including its gradients and Hessians inherited from the data. Correspondingly, it introduces a novel gradient descent approach, drawing inspiration from multiscale algorithms used in scientific computing. This approach seeks to transcend empirical learning rate selection, offering a more systematic, data-informed strategy to enhance training efficiency, especially in the later stages.
Point Deformable Network with Enhanced Normal Embedding for Point Cloud Analysis
Dec 20, 2023



Recently MLP-based methods have shown strong performance in point cloud analysis. Simple MLP architectures are able to learn geometric features in local point groups yet fail to model long-range dependencies directly. In this paper, we propose Point Deformable Network (PDNet), a concise MLP-based network that can capture long-range relations with strong representation ability. Specifically, we put forward Point Deformable Aggregation Module (PDAM) to improve representation capability in both long-range dependency and adaptive aggregation among points. For each query point, PDAM aggregates information from deformable reference points rather than points in limited local areas. The deformable reference points are generated data-dependent, and we initialize them according to the input point positions. Additional offsets and modulation scalars are learned on the whole point features, which shift the deformable reference points to the regions of interest. We also suggest estimating the normal vector for point clouds and applying Enhanced Normal Embedding (ENE) to the geometric extractors to improve the representation ability of single-point. Extensive experiments and ablation studies on various benchmarks demonstrate the effectiveness and superiority of our PDNet.
Automated Measurement of Pericoronary Adipose Tissue Attenuation and Volume in CT Angiography
Nov 22, 2023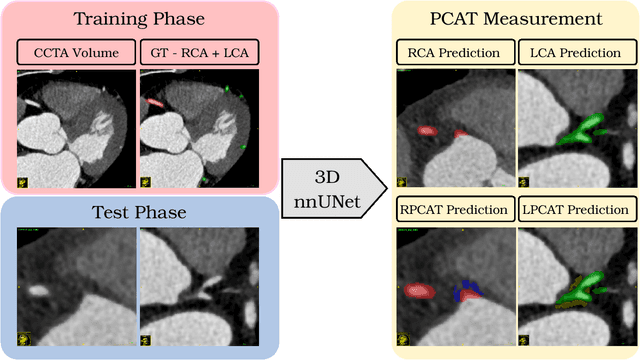
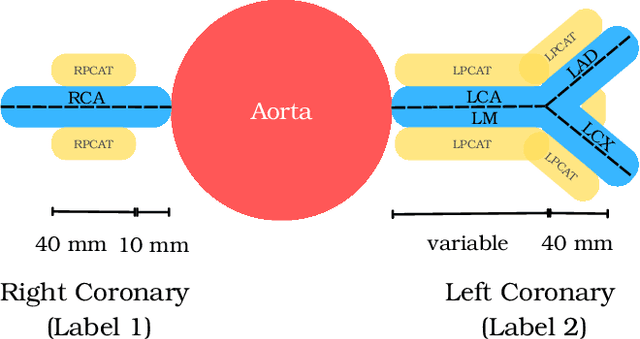


Pericoronary adipose tissue (PCAT) is the deposition of fat in the vicinity of the coronary arteries. It is an indicator of coronary inflammation and associated with coronary artery disease. Non-invasive coronary CT angiography (CCTA) is presently used to obtain measures of the thickness, volume, and attenuation of fat deposition. However, prior works solely focus on measuring PCAT using semi-automated approaches at the right coronary artery (RCA) over the left coronary artery (LCA). In this pilot work, we developed a fully automated approach for the measurement of PCAT mean attenuation and volume in the region around both coronary arteries. First, we used a large subset of patients from the public ImageCAS dataset (n = 735) to train a 3D full resolution nnUNet to segment LCA and RCA. Then, we automatically measured PCAT in the surrounding arterial regions. We evaluated our method on a held-out test set of patients (n = 183) from the same dataset. A mean Dice score of 83% and PCAT attenuation of -73.81 $\pm$ 12.69 HU was calculated for the RCA, while a mean Dice score of 81% and PCAT attenuation of -77.51 $\pm$ 7.94 HU was computed for the LCA. To the best of our knowledge, we are the first to develop a fully automated method to measure PCAT attenuation and volume at both the RCA and LCA. Our work underscores how automated PCAT measurement holds promise as a biomarker for identification of inflammation and cardiac disease.
Gradient constrained sharpness-aware prompt learning for vision-language models
Sep 20, 2023
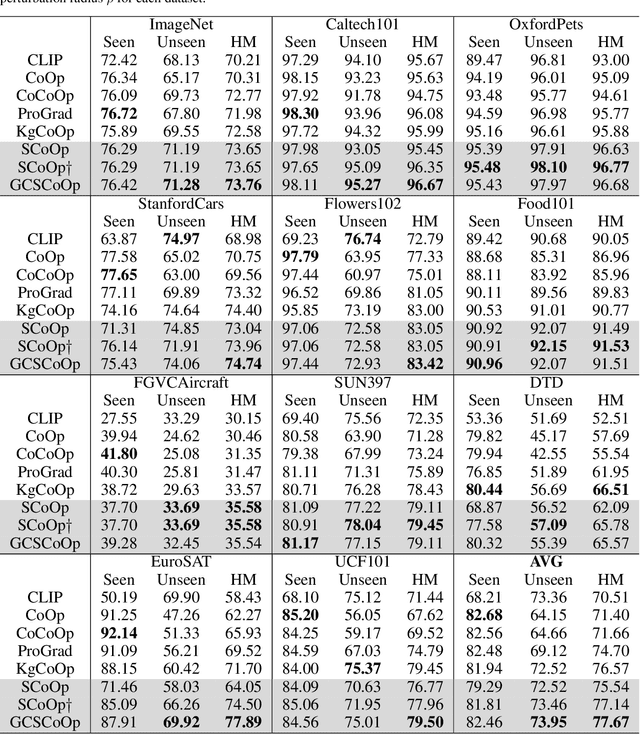
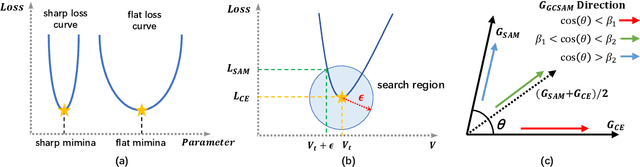
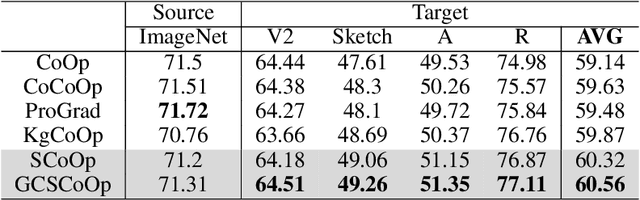
This paper targets a novel trade-off problem in generalizable prompt learning for vision-language models (VLM), i.e., improving the performance on unseen classes while maintaining the performance on seen classes. Comparing with existing generalizable methods that neglect the seen classes degradation, the setting of this problem is more strict and fits more closely with practical applications. To solve this problem, we start from the optimization perspective, and leverage the relationship between loss landscape geometry and model generalization ability. By analyzing the loss landscapes of the state-of-the-art method and vanilla Sharpness-aware Minimization (SAM) based method, we conclude that the trade-off performance correlates to both loss value and loss sharpness, while each of them is indispensable. However, we find the optimizing gradient of existing methods cannot maintain high relevance to both loss value and loss sharpness during optimization, which severely affects their trade-off performance. To this end, we propose a novel SAM-based method for prompt learning, denoted as Gradient Constrained Sharpness-aware Context Optimization (GCSCoOp), to dynamically constrain the optimizing gradient, thus achieving above two-fold optimization objective simultaneously. Extensive experiments verify the effectiveness of GCSCoOp in the trade-off problem.
Expert Uncertainty and Severity Aware Chest X-Ray Classification by Multi-Relationship Graph Learning
Sep 06, 2023Patients undergoing chest X-rays (CXR) often endure multiple lung diseases. When evaluating a patient's condition, due to the complex pathologies, subtle texture changes of different lung lesions in images, and patient condition differences, radiologists may make uncertain even when they have experienced long-term clinical training and professional guidance, which makes much noise in extracting disease labels based on CXR reports. In this paper, we re-extract disease labels from CXR reports to make them more realistic by considering disease severity and uncertainty in classification. Our contributions are as follows: 1. We re-extracted the disease labels with severity and uncertainty by a rule-based approach with keywords discussed with clinical experts. 2. To further improve the explainability of chest X-ray diagnosis, we designed a multi-relationship graph learning method with an expert uncertainty-aware loss function. 3. Our multi-relationship graph learning method can also interpret the disease classification results. Our experimental results show that models considering disease severity and uncertainty outperform previous state-of-the-art methods.
Linear Regression on Manifold Structured Data: the Impact of Extrinsic Geometry on Solutions
Jul 22, 2023



In this paper, we study linear regression applied to data structured on a manifold. We assume that the data manifold is smooth and is embedded in a Euclidean space, and our objective is to reveal the impact of the data manifold's extrinsic geometry on the regression. Specifically, we analyze the impact of the manifold's curvatures (or higher order nonlinearity in the parameterization when the curvatures are locally zero) on the uniqueness of the regression solution. Our findings suggest that the corresponding linear regression does not have a unique solution when the embedded submanifold is flat in some dimensions. Otherwise, the manifold's curvature (or higher order nonlinearity in the embedding) may contribute significantly, particularly in the solution associated with the normal directions of the manifold. Our findings thus reveal the role of data manifold geometry in ensuring the stability of regression models for out-of-distribution inferences.
Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Jul 22, 2023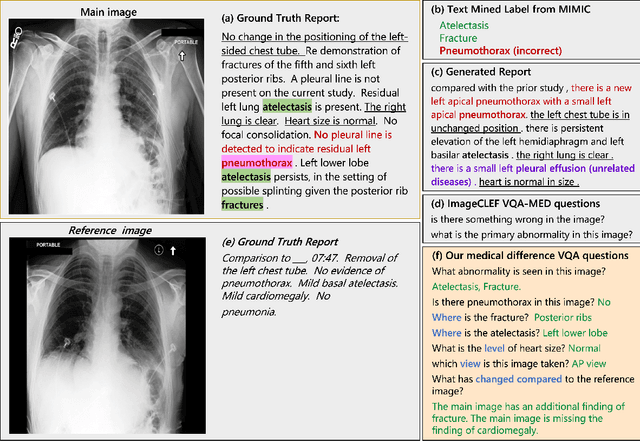

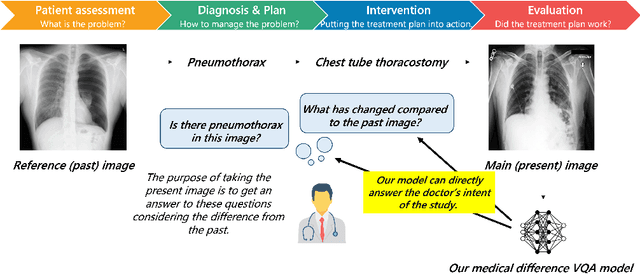
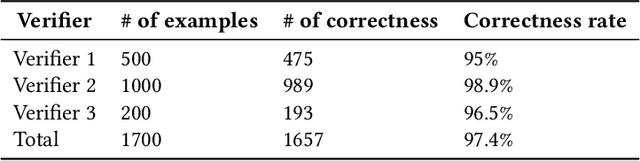
To contribute to automating the medical vision-language model, we propose a novel Chest-Xray Difference Visual Question Answering (VQA) task. Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them. This is consistent with the radiologist's diagnosis practice that compares the current image with the reference before concluding the report. We collect a new dataset, namely MIMIC-Diff-VQA, including 700,703 QA pairs from 164,324 pairs of main and reference images. Compared to existing medical VQA datasets, our questions are tailored to the Assessment-Diagnosis-Intervention-Evaluation treatment procedure used by clinical professionals. Meanwhile, we also propose a novel expert knowledge-aware graph representation learning model to address this task. The proposed baseline model leverages expert knowledge such as anatomical structure prior, semantic, and spatial knowledge to construct a multi-relationship graph, representing the image differences between two images for the image difference VQA task. The dataset and code can be found at https://github.com/Holipori/MIMIC-Diff-VQA. We believe this work would further push forward the medical vision language model.
Unified Multi-View Orthonormal Non-Negative Graph Based Clustering Framework
Nov 03, 2022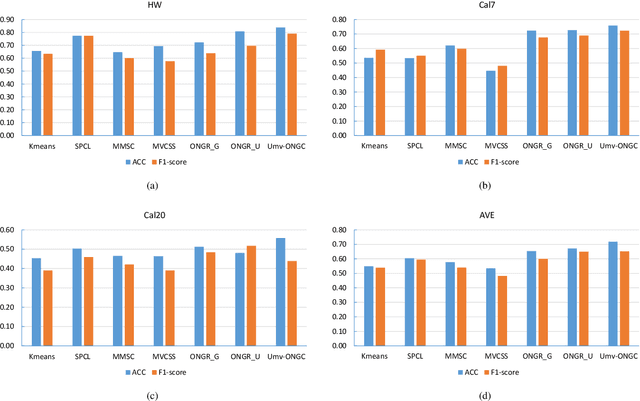
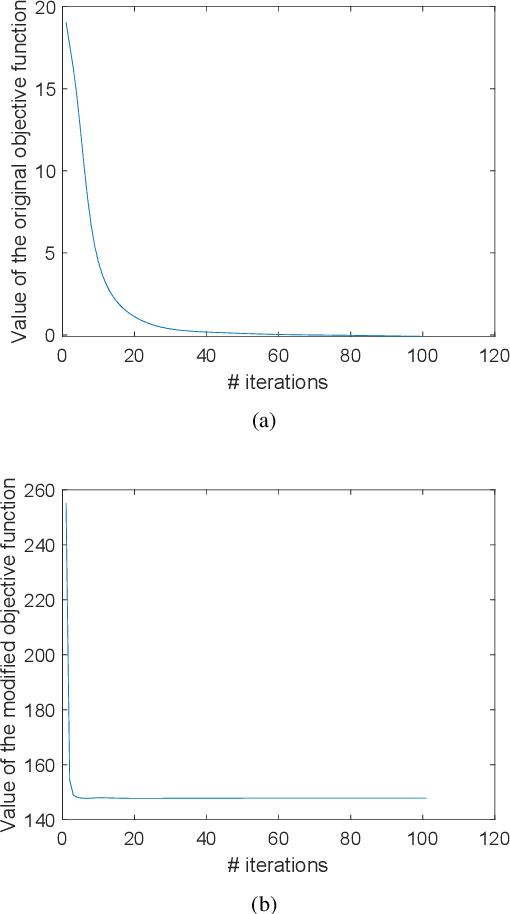
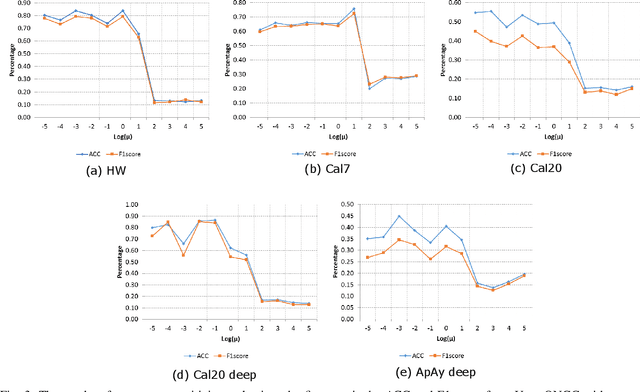
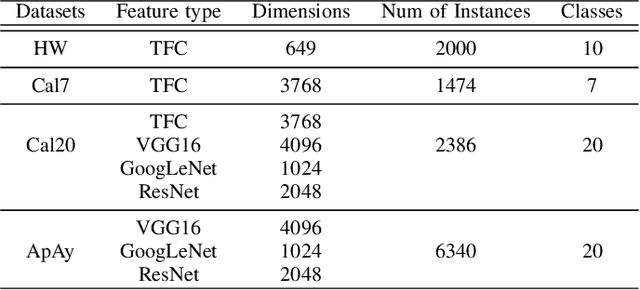
Spectral clustering is an effective methodology for unsupervised learning. Most traditional spectral clustering algorithms involve a separate two-step procedure and apply the transformed new representations for the final clustering results. Recently, much progress has been made to utilize the non-negative feature property in real-world data and to jointly learn the representation and clustering results. However, to our knowledge, no previous work considers a unified model that incorporates the important multi-view information with those properties, which severely limits the performance of existing methods. In this paper, we formulate a novel clustering model, which exploits the non-negative feature property and, more importantly, incorporates the multi-view information into a unified joint learning framework: the unified multi-view orthonormal non-negative graph based clustering framework (Umv-ONGC). Then, we derive an effective three-stage iterative solution for the proposed model and provide analytic solutions for the three sub-problems from the three stages. We also explore, for the first time, the multi-model non-negative graph-based approach to clustering data based on deep features. Extensive experiments on three benchmark data sets demonstrate the effectiveness of the proposed method.
Memory Efficient Temporal & Visual Graph Model for Unsupervised Video Domain Adaptation
Aug 13, 2022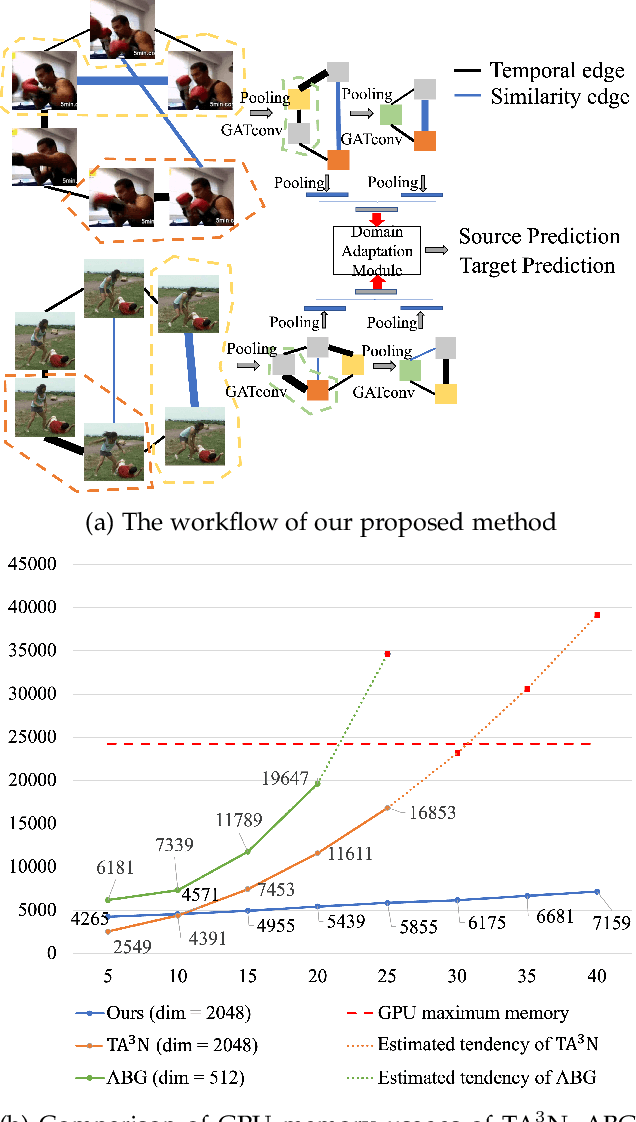
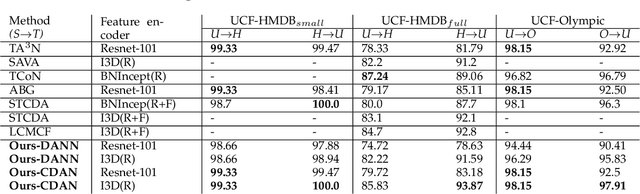
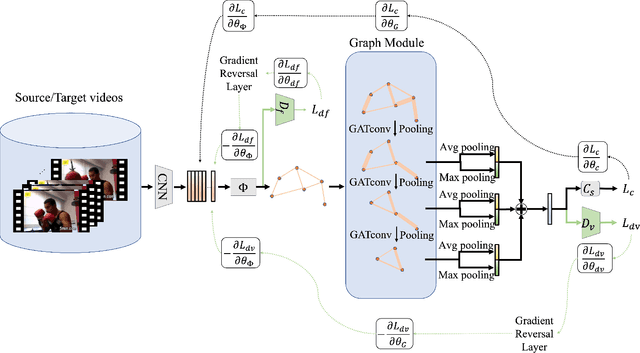
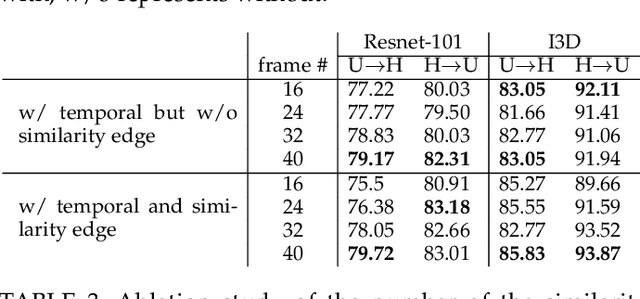
Existing video domain adaption (DA) methods need to store all temporal combinations of video frames or pair the source and target videos, which are memory cost expensive and can't scale up to long videos. To address these limitations, we propose a memory-efficient graph-based video DA approach as follows. At first our method models each source or target video by a graph: nodes represent video frames and edges represent the temporal or visual similarity relationship between frames. We use a graph attention network to learn the weight of individual frames and simultaneously align the source and target video into a domain-invariant graph feature space. Instead of storing a large number of sub-videos, our method only constructs one graph with a graph attention mechanism for one video, reducing the memory cost substantially. The extensive experiments show that, compared with the state-of-art methods, we achieved superior performance while reducing the memory cost significantly.
Nearest Neighbor Sampling of Point Sets using Random Rays
Nov 29, 2019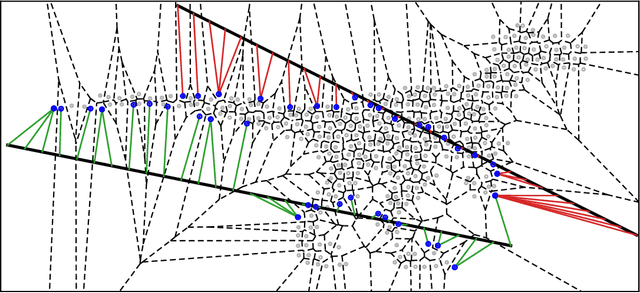

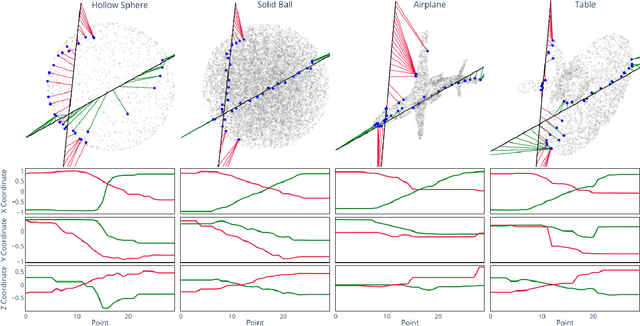
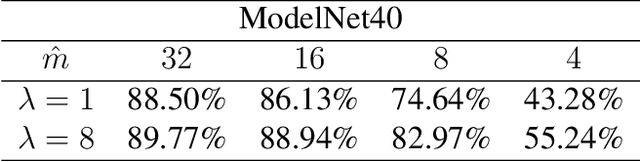
We propose a new framework for the sampling, compression, and analysis of distributions of point sets and other geometric objects embedded in Euclidean spaces. A set of randomly selected rays are projected onto their closest points in the data set, forming the ray signature. From the signature, statistical information about the data set, as well as certain geometrical information, can be extracted, independent of the ray set. We present promising results from "RayNN", a neural network for the classification of point clouds based on ray signatures.