 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Operator Towards Edge Deployability and Portability for Sparse-to-Dense, Real-Time Virtual Sensing on Irregular Grids
Apr 02, 2026Accurate sensing of spatially distributed physical fields typically requires dense instrumentation, which is often infeasible in real-world systems due to cost, accessibility, and environmental constraints. Physics-based solvers address this through direct numerical integration of governing equations, but their computational latency and power requirements preclude real-time use in resource-constrained monitoring and control systems. Here we introduce VIRSO (Virtual Irregular Real-Time Sparse Operator), a graph-based neural operator for sparse-to-dense reconstruction on irregular geometries, and a variable-connectivity algorithm, Variable KNN (V-KNN), for mesh-informed graph construction. Unlike prior neural operators that treat hardware deployability as secondary, VIRSO reframes inference as measurement: the combination of both spectral and spatial analysis provides accurate reconstruction without the high latency and power consumption of previous graph-based methodologies with poor scalability, presenting VIRSO as a potential candidate for edge-constrained, real-time virtual sensing. We evaluate VIRSO on three nuclear thermal-hydraulic benchmarks of increasing geometric and multiphysics complexity, across reconstruction ratios from 47:1 to 156:1. VIRSO achieves mean relative $L_2$ errors below 1%, outperforming other benchmark operators while using fewer parameters. The full 10-layer configuration reduces the energy-delay product (EDP) from ${\approx}206$ J$\cdot$ms for the graph operator baseline to $10.1$ J$\cdot$ms on an NVIDIA H200. Implemented on an NVIDIA Jetson Orin Nano, all configurations of VIRSO provide sub-10 W power consumption and sub-second latency. These results establish the edge-feasibility and hardware-portability of VIRSO and present compute-aware operator learning as a new paradigm for real-time sensing in inaccessible and resource-constrained environments.
Adversarial Vulnerabilities in Neural Operator Digital Twins: Gradient-Free Attacks on Nuclear Thermal-Hydraulic Surrogates
Mar 23, 2026Operator learning models are rapidly emerging as the predictive core of digital twins for nuclear and energy systems, promising real-time field reconstruction from sparse sensor measurements. Yet their robustness to adversarial perturbations remains uncharacterized, a critical gap for deployment in safety-critical systems. Here we show that neural operators are acutely vulnerable to extremely sparse (fewer than 1% of inputs), physically plausible perturbations that exploit their sensitivity to boundary conditions. Using gradient-free differential evolution across four operator architectures, we demonstrate that minimal modifications trigger catastrophic prediction failures, increasing relative $L_2$ error from $\sim$1.5% (validated accuracy) to 37-63% while remaining completely undetectable by standard validation metrics. Notably, 100% of successful single-point attacks pass z-score anomaly detection. We introduce the effective perturbation dimension $d_{\text{eff}}$, a Jacobian-based diagnostic that, together with sensitivity magnitude, yields a two-factor vulnerability model explaining why architectures with extreme sensitivity concentration (POD-DeepONet, $d_{\text{eff}} \approx 1$) are not necessarily the most exploitable, since low-rank output projections cap maximum error, while moderate concentration with sufficient amplification (S-DeepONet, $d_{\text{eff}} \approx 4$) produces the highest attack success. Gradient-free search outperforms gradient-based alternatives (PGD) on architectures with gradient pathologies, while random perturbations of equal magnitude achieve near-zero success rates, confirming that the discovered vulnerabilities are structural. Our findings expose a previously overlooked attack surface in operator learning models and establish that these models require robustness guarantees beyond standard validation before deployment.
Med-CoReasoner: Reducing Language Disparities in Medical Reasoning via Language-Informed Co-Reasoning
Jan 13, 2026While reasoning-enhanced large language models perform strongly on English medical tasks, a persistent multilingual gap remains, with substantially weaker reasoning in local languages, limiting equitable global medical deployment. To bridge this gap, we introduce Med-CoReasoner, a language-informed co-reasoning framework that elicits parallel English and local-language reasoning, abstracts them into structured concepts, and integrates local clinical knowledge into an English logical scaffold via concept-level alignment and retrieval. This design combines the structural robustness of English reasoning with the practice-grounded expertise encoded in local languages. To evaluate multilingual medical reasoning beyond multiple-choice settings, we construct MultiMed-X, a benchmark covering seven languages with expert-annotated long-form question answering and natural language inference tasks, comprising 350 instances per language. Experiments across three benchmarks show that Med-CoReasoner improves multilingual reasoning performance by an average of 5%, with particularly substantial gains in low-resource languages. Moreover, model distillation and expert evaluation analysis further confirm that Med-CoReasoner produces clinically sound and culturally grounded reasoning traces.
Agentic Physical AI toward a Domain-Specific Foundation Model for Nuclear Reactor Control
Dec 29, 2025The prevailing paradigm in AI for physical systems, scaling general-purpose foundation models toward universal multimodal reasoning, confronts a fundamental barrier at the control interface. Recent benchmarks show that even frontier vision-language models achieve only 50-53% accuracy on basic quantitative physics tasks, behaving as approximate guessers that preserve semantic plausibility while violating physical constraints. This input unfaithfulness is not a scaling deficiency but a structural limitation. Perception-centric architectures optimize parameter-space imitation, whereas safety-critical control demands outcome-space guarantees over executed actions. Here, we present a fundamentally different pathway toward domain-specific foundation models by introducing compact language models operating as Agentic Physical AI, in which policy optimization is driven by physics-based validation rather than perceptual inference. We train a 360-million-parameter model on synthetic reactor control scenarios, scaling the dataset from 10^3 to 10^5 examples. This induces a sharp phase transition absent in general-purpose models. Small-scale systems exhibit high-variance imitation with catastrophic tail risk, while large-scale models undergo variance collapse exceeding 500x reduction, stabilizing execution-level behavior. Despite balanced exposure to four actuation families, the model autonomously rejects approximately 70% of the training distribution and concentrates 95% of runtime execution on a single-bank strategy. Learned representations transfer across distinct physics and continuous input modalities without architectural modification.
Virtual Sensing to Enable Real-Time Monitoring of Inaccessible Locations \& Unmeasurable Parameters
Nov 28, 2024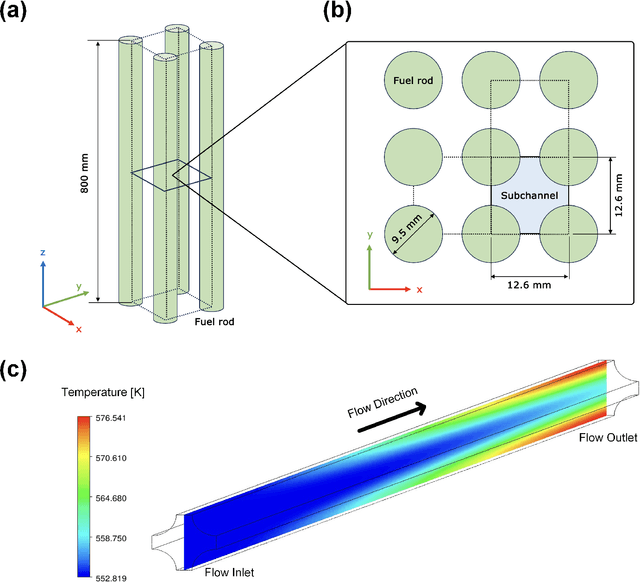

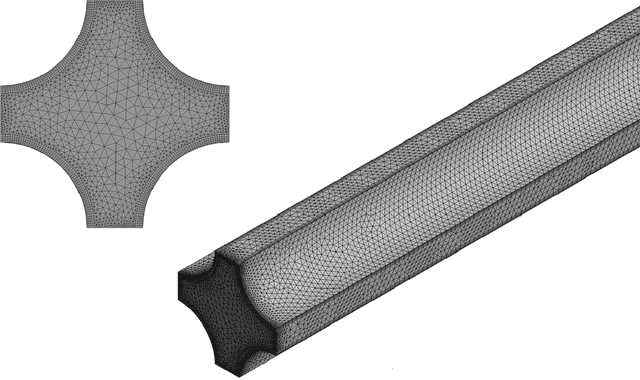
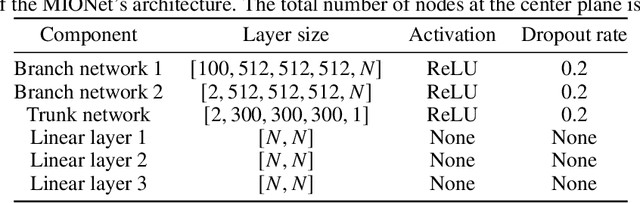
Real-time monitoring of critical parameters is essential for energy systems' safe and efficient operation. However, traditional sensors often fail and degrade in harsh environments where physical sensors cannot be placed (inaccessible locations). In addition, there are important parameters that cannot be directly measured by sensors. We need machine learning (ML)-based real-time monitoring in those remote locations to ensure system operations. However, traditional ML models struggle to process continuous sensor profile data to fit model requirements, leading to the loss of spatial relationships. Another challenge for real-time monitoring is ``dataset shift" and the need for frequent retraining under varying conditions, where extensive retraining prohibits real-time inference. To resolve these challenges, this study addressed the limitations of real-time monitoring methods by enabling monitoring in locations where physical sensors are impractical to deploy. Our proposed approach, utilizing Multi-Input Operator Network virtual sensors, leverages deep learning to seamlessly integrate diverse data sources and accurately predict key parameters in real-time without the need for additional physical sensors. The approach's effectiveness is demonstrated through thermal-hydraulic monitoring in a nuclear reactor subchannel, achieving remarkable accuracy.
Virtual Sensing for Real-Time Degradation Monitoring of Nuclear Systems: Leveraging DeepONet for Enhanced Sensing Coverage for Digital Twin-Enabling Technology
Oct 17, 2024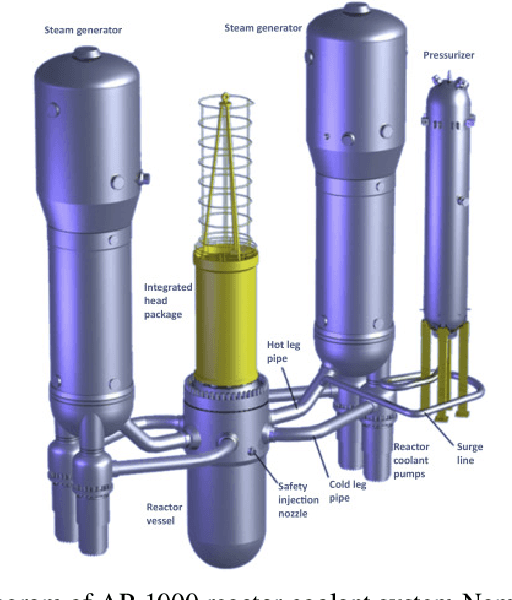

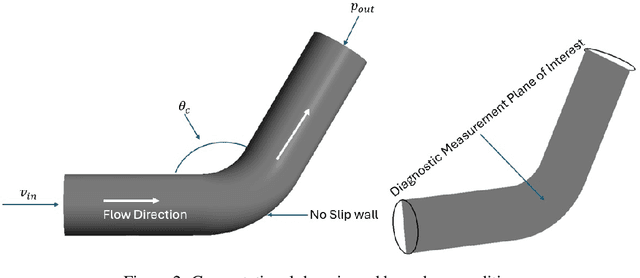
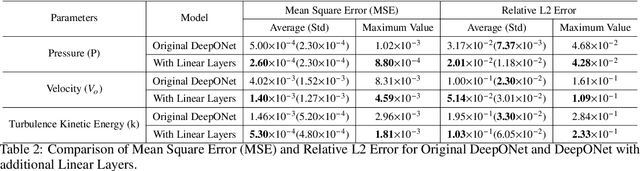
Effective real-time monitoring technique is crucial for detecting material degradation and maintaining the structural integrity of nuclear systems to ensure both safety and operational efficiency. Traditional physical sensor systems face limitations such as installation challenges, high costs, and difficulties in measuring critical parameters in hard-to-reach or harsh environments, often resulting in incomplete data coverage. Machine learning-driven virtual sensors offer a promising solution by enhancing physical sensor capabilities to monitor critical degradation indicators like pressure, velocity, and turbulence. However, conventional machine learning models struggle with real-time monitoring due to the high-dimensional nature of reactor data and the need for frequent retraining. This paper explores the use of Deep Operator Networks (DeepONet) within a digital twin (DT) framework to predict key thermal-hydraulic parameters in the hot leg of an AP-1000 Pressurized Water Reactor (PWR). In this study, DeepONet is trained with different operational conditions, which relaxes the requirement of continuous retraining, making it suitable for online and real-time prediction components for DT. Our results show that DeepONet achieves accurate predictions with low mean squared error and relative L2 error and can make predictions on unknown data 160,000 times faster than traditional finite element (FE) simulations. This speed and accuracy make DeepONet a powerful tool for tracking conditions that contribute to material degradation in real-time, enhancing reactor safety and longevity.
Can Physician Judgment Enhance Model Trustworthiness? A Case Study on Predicting Pathological Lymph Nodes in Rectal Cancer
Dec 15, 2023Explainability is key to enhancing artificial intelligence's trustworthiness in medicine. However, several issues remain concerning the actual benefit of explainable models for clinical decision-making. Firstly, there is a lack of consensus on an evaluation framework for quantitatively assessing the practical benefits that effective explainability should provide to practitioners. Secondly, physician-centered evaluations of explainability are limited. Thirdly, the utility of built-in attention mechanisms in transformer-based models as an explainability technique is unclear. We hypothesize that superior attention maps should align with the information that physicians focus on, potentially reducing prediction uncertainty and increasing model reliability. We employed a multimodal transformer to predict lymph node metastasis in rectal cancer using clinical data and magnetic resonance imaging, exploring how well attention maps, visualized through a state-of-the-art technique, can achieve agreement with physician understanding. We estimated the model's uncertainty using meta-level information like prediction probability variance and quantified agreement. Our assessment of whether this agreement reduces uncertainty found no significant effect. In conclusion, this case study did not confirm the anticipated benefit of attention maps in enhancing model reliability. Superficial explanations could do more harm than good by misleading physicians into relying on uncertain predictions, suggesting that the current state of attention mechanisms in explainability should not be overestimated. Identifying explainability mechanisms truly beneficial for clinical decision-making remains essential.
Expert Uncertainty and Severity Aware Chest X-Ray Classification by Multi-Relationship Graph Learning
Sep 06, 2023Patients undergoing chest X-rays (CXR) often endure multiple lung diseases. When evaluating a patient's condition, due to the complex pathologies, subtle texture changes of different lung lesions in images, and patient condition differences, radiologists may make uncertain even when they have experienced long-term clinical training and professional guidance, which makes much noise in extracting disease labels based on CXR reports. In this paper, we re-extract disease labels from CXR reports to make them more realistic by considering disease severity and uncertainty in classification. Our contributions are as follows: 1. We re-extracted the disease labels with severity and uncertainty by a rule-based approach with keywords discussed with clinical experts. 2. To further improve the explainability of chest X-ray diagnosis, we designed a multi-relationship graph learning method with an expert uncertainty-aware loss function. 3. Our multi-relationship graph learning method can also interpret the disease classification results. Our experimental results show that models considering disease severity and uncertainty outperform previous state-of-the-art methods.
Potential of Deep Operator Networks in Digital Twin-enabling Technology for Nuclear System
Aug 15, 2023This research introduces the Deep Operator Network (DeepONet) as a robust surrogate modeling method within the context of digital twin (DT) systems for nuclear engineering. With the increasing importance of nuclear energy as a carbon-neutral solution, adopting DT technology has become crucial to enhancing operational efficiencies, safety, and predictive capabilities in nuclear engineering applications. DeepONet exhibits remarkable prediction accuracy, outperforming traditional ML methods. Through extensive benchmarking and evaluation, this study showcases the scalability and computational efficiency of DeepONet in solving a challenging particle transport problem. By taking functions as input data and constructing the operator $G$ from training data, DeepONet can handle diverse and complex scenarios effectively. However, the application of DeepONet also reveals challenges related to optimal sensor placement and model evaluation, critical aspects of real-world implementation. Addressing these challenges will further enhance the method's practicality and reliability. Overall, DeepONet presents a promising and transformative tool for nuclear engineering research and applications. Its accurate prediction and computational efficiency capabilities can revolutionize DT systems, advancing nuclear engineering research. This study marks an important step towards harnessing the power of surrogate modeling techniques in critical engineering domains.
Expert Knowledge-Aware Image Difference Graph Representation Learning for Difference-Aware Medical Visual Question Answering
Jul 22, 2023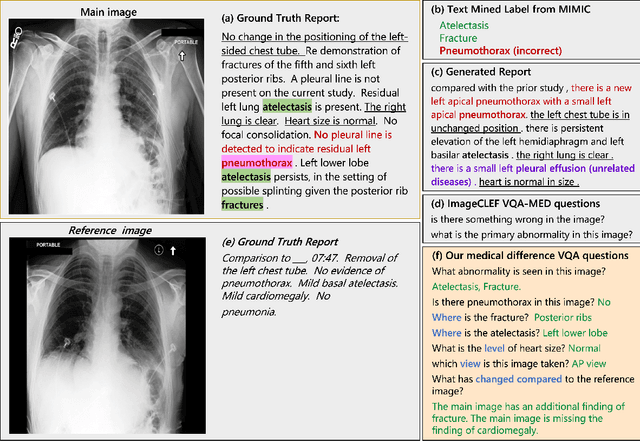

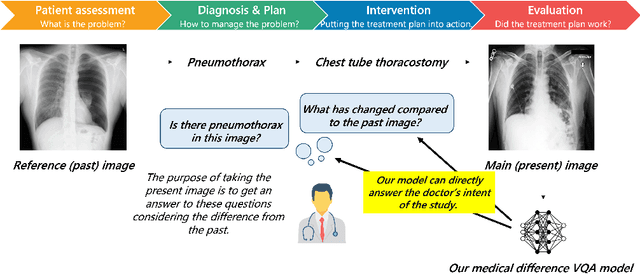
To contribute to automating the medical vision-language model, we propose a novel Chest-Xray Difference Visual Question Answering (VQA) task. Given a pair of main and reference images, this task attempts to answer several questions on both diseases and, more importantly, the differences between them. This is consistent with the radiologist's diagnosis practice that compares the current image with the reference before concluding the report. We collect a new dataset, namely MIMIC-Diff-VQA, including 700,703 QA pairs from 164,324 pairs of main and reference images. Compared to existing medical VQA datasets, our questions are tailored to the Assessment-Diagnosis-Intervention-Evaluation treatment procedure used by clinical professionals. Meanwhile, we also propose a novel expert knowledge-aware graph representation learning model to address this task. The proposed baseline model leverages expert knowledge such as anatomical structure prior, semantic, and spatial knowledge to construct a multi-relationship graph, representing the image differences between two images for the image difference VQA task. The dataset and code can be found at https://github.com/Holipori/MIMIC-Diff-VQA. We believe this work would further push forward the medical vision language model.