 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Medical Image Visual Question Answering via Multi-Modal Relationship Graph Learning
Paper and Code
Feb 19, 2023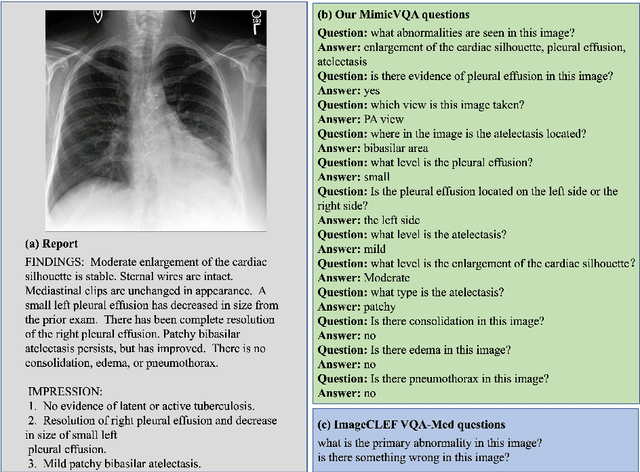
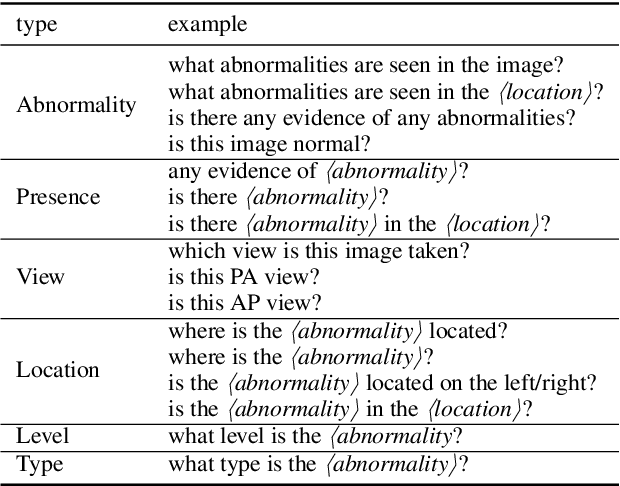
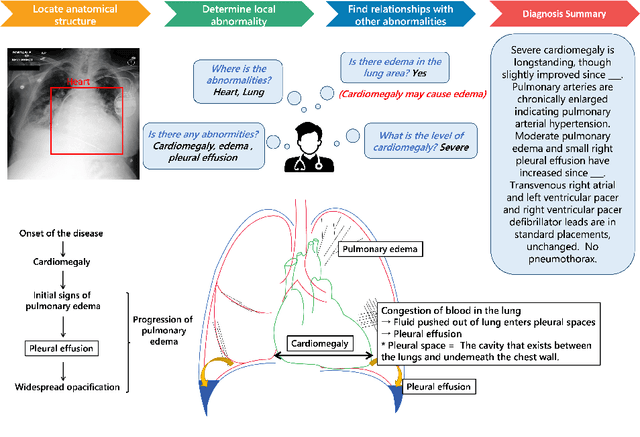
Medical visual question answering (VQA) aims to answer clinically relevant questions regarding input medical images. This technique has the potential to improve the efficiency of medical professionals while relieving the burden on the public health system, particularly in resource-poor countries. Existing medical VQA methods tend to encode medical images and learn the correspondence between visual features and questions without exploiting the spatial, semantic, or medical knowledge behind them. This is partially because of the small size of the current medical VQA dataset, which often includes simple questions. Therefore, we first collected a comprehensive and large-scale medical VQA dataset, focusing on chest X-ray images. The questions involved detailed relationships, such as disease names, locations, levels, and types in our dataset. Based on this dataset, we also propose a novel baseline method by constructing three different relationship graphs: spatial relationship, semantic relationship, and implicit relationship graphs on the image regions, questions, and semantic labels. The answer and graph reasoning paths are learned for different questions.