 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Shaping of Human Prosociality: A Latent-State POMDP Framework
Mar 02, 2026We propose a decision-theoretic framework in which a robot strategically can shape inferred human's prosocial state during repeated interactions. Modeling the human's prosociality as a latent state that evolves over time, the robot learns to infer and influence this state through its own actions, including helping and signaling. We formalize this as a latent-state POMDP with limited observations and learn the transition and observation dynamics using expectation maximization. The resulting belief-based policy balances task and social objectives, selecting actions that maximize long-term cooperative outcomes. We evaluate the model using data from user studies and show that the learned policy outperforms baseline strategies in both team performance and increasing observed human cooperative behavior.
EMAD: Evidence-Centric Grounded Multimodal Diagnosis for Alzheimer's Disease
Feb 22, 2026Deep learning models for medical image analysis often act as black boxes, seldom aligning with clinical guidelines or explicitly linking decisions to supporting evidence. This is especially critical in Alzheimer's disease (AD), where predictions should be grounded in both anatomical and clinical findings. We present EMAD, a vision-language framework that generates structured AD diagnostic reports in which each claim is explicitly grounded in multimodal evidence. EMAD uses a hierarchical Sentence-Evidence-Anatomy (SEA) grounding mechanism: (i) sentence-to-evidence grounding links generated sentences to clinical evidence phrases, and (ii) evidence-to-anatomy grounding localizes corresponding structures on 3D brain MRI. To reduce dense annotation requirements, we propose GTX-Distill, which transfers grounding behavior from a teacher trained with limited supervision to a student operating on model-generated reports. We further introduce Executable-Rule GRPO, a reinforcement fine-tuning scheme with verifiable rewards that enforces clinical consistency, protocol adherence, and reasoning-diagnosis coherence. On the AD-MultiSense dataset, EMAD achieves state-of-the-art diagnostic accuracy and produces more transparent, anatomically faithful reports than existing methods. We will release code and grounding annotations to support future research in trustworthy medical vision-language models.
Early GVHD Prediction in Liver Transplantation via Multi-Modal Deep Learning on Imbalanced EHR Data
Nov 06, 2025Graft-versus-host disease (GVHD) is a rare but often fatal complication in liver transplantation, with a very high mortality rate. By harnessing multi-modal deep learning methods to integrate heterogeneous and imbalanced electronic health records (EHR), we aim to advance early prediction of GVHD, paving the way for timely intervention and improved patient outcomes. In this study, we analyzed pre-transplant electronic health records (EHR) spanning the period before surgery for 2,100 liver transplantation patients, including 42 cases of graft-versus-host disease (GVHD), from a cohort treated at Mayo Clinic between 1992 and 2025. The dataset comprised four major modalities: patient demographics, laboratory tests, diagnoses, and medications. We developed a multi-modal deep learning framework that dynamically fuses these modalities, handles irregular records with missing values, and addresses extreme class imbalance through AUC-based optimization. The developed framework outperforms all single-modal and multi-modal machine learning baselines, achieving an AUC of 0.836, an AUPRC of 0.157, a recall of 0.768, and a specificity of 0.803. It also demonstrates the effectiveness of our approach in capturing complementary information from different modalities, leading to improved performance. Our multi-modal deep learning framework substantially improves existing approaches for early GVHD prediction. By effectively addressing the challenges of heterogeneity and extreme class imbalance in real-world EHR, it achieves accurate early prediction. Our proposed multi-modal deep learning method demonstrates promising results for early prediction of a GVHD in liver transplantation, despite the challenge of extremely imbalanced EHR data.
Enhancing Uncertainty Estimation and Interpretability via Bayesian Non-negative Decision Layer
May 28, 2025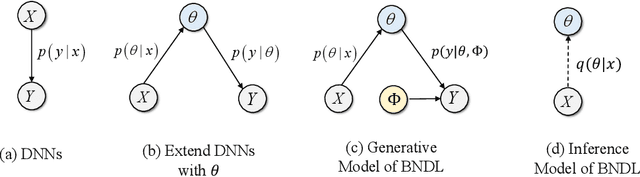
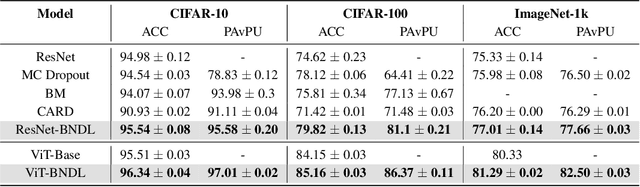


Although deep neural networks have demonstrated significant success due to their powerful expressiveness, most models struggle to meet practical requirements for uncertainty estimation. Concurrently, the entangled nature of deep neural networks leads to a multifaceted problem, where various localized explanation techniques reveal that multiple unrelated features influence the decisions, thereby undermining interpretability. To address these challenges, we develop a Bayesian Non-negative Decision Layer (BNDL), which reformulates deep neural networks as a conditional Bayesian non-negative factor analysis. By leveraging stochastic latent variables, the BNDL can model complex dependencies and provide robust uncertainty estimation. Moreover, the sparsity and non-negativity of the latent variables encourage the model to learn disentangled representations and decision layers, thereby improving interpretability. We also offer theoretical guarantees that BNDL can achieve effective disentangled learning. In addition, we developed a corresponding variational inference method utilizing a Weibull variational inference network to approximate the posterior distribution of the latent variables. Our experimental results demonstrate that with enhanced disentanglement capabilities, BNDL not only improves the model's accuracy but also provides reliable uncertainty estimation and improved interpretability.
Generative Active Adaptation for Drifting and Imbalanced Network Intrusion Detection
Mar 04, 2025



Machine learning has shown promise in network intrusion detection systems, yet its performance often degrades due to concept drift and imbalanced data. These challenges are compounded by the labor-intensive process of labeling network traffic, especially when dealing with evolving and rare attack types, which makes selecting the right data for adaptation difficult. To address these issues, we propose a generative active adaptation framework that minimizes labeling effort while enhancing model robustness. Our approach employs density-aware active sampling to identify the most informative samples for annotation and leverages deep generative models to synthesize diverse samples, thereby augmenting the training set and mitigating the effects of concept drift. We evaluate our end-to-end framework on both simulated IDS data and a real-world ISP dataset, demonstrating significant improvements in intrusion detection performance. Our method boosts the overall F1-score from 0.60 (without adaptation) to 0.86. Rare attacks such as Infiltration, Web Attack, and FTP-BruteForce, which originally achieve F1 scores of 0.001, 0.04, and 0.00, improve to 0.30, 0.50, and 0.71, respectively, with generative active adaptation in the CIC-IDS 2018 dataset. Our framework effectively enhances rare attack detection while reducing labeling costs, making it a scalable and adaptive solution for real-world intrusion detection.
Robust Multiple Description Neural Video Codec with Masked Transformer for Dynamic and Noisy Networks
Dec 10, 2024Multiple Description Coding (MDC) is a promising error-resilient source coding method that is particularly suitable for dynamic networks with multiple (yet noisy and unreliable) paths. However, conventional MDC video codecs suffer from cumbersome architectures, poor scalability, limited loss resilience, and lower compression efficiency. As a result, MDC has never been widely adopted. Inspired by the potential of neural video codecs, this paper rethinks MDC design. We propose a novel MDC video codec, NeuralMDC, demonstrating how bidirectional transformers trained for masked token prediction can vastly simplify the design of MDC video codec. To compress a video, NeuralMDC starts by tokenizing each frame into its latent representation and then splits the latent tokens to create multiple descriptions containing correlated information. Instead of using motion prediction and warping operations, NeuralMDC trains a bidirectional masked transformer to model the spatial-temporal dependencies of latent representations and predict the distribution of the current representation based on the past. The predicted distribution is used to independently entropy code each description and infer any potentially lost tokens. Extensive experiments demonstrate NeuralMDC achieves state-of-the-art loss resilience with minimal sacrifices in compression efficiency, significantly outperforming the best existing residual-coding-based error-resilient neural video codec.
Disentangled Generative Graph Representation Learning
Aug 24, 2024Recently, generative graph models have shown promising results in learning graph representations through self-supervised methods. However, most existing generative graph representation learning (GRL) approaches rely on random masking across the entire graph, which overlooks the entanglement of learned representations. This oversight results in non-robustness and a lack of explainability. Furthermore, disentangling the learned representations remains a significant challenge and has not been sufficiently explored in GRL research. Based on these insights, this paper introduces DiGGR (Disentangled Generative Graph Representation Learning), a self-supervised learning framework. DiGGR aims to learn latent disentangled factors and utilizes them to guide graph mask modeling, thereby enhancing the disentanglement of learned representations and enabling end-to-end joint learning. Extensive experiments on 11 public datasets for two different graph learning tasks demonstrate that DiGGR consistently outperforms many previous self-supervised methods, verifying the effectiveness of the proposed approach.
MAC: A Benchmark for Multiple Attributes Compositional Zero-Shot Learning
Jun 18, 2024

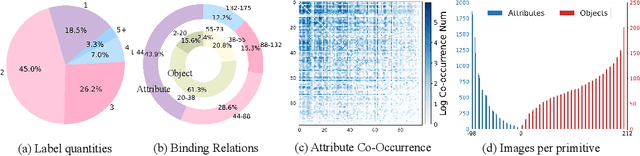

Compositional Zero-Shot Learning (CZSL) aims to learn semantic primitives (attributes and objects) from seen compositions and recognize unseen attribute-object compositions. Existing CZSL datasets focus on single attributes, neglecting the fact that objects naturally exhibit multiple interrelated attributes. Real-world objects often possess multiple interrelated attributes, and current datasets' narrow attribute scope and single attribute labeling introduce annotation biases, undermining model performance and evaluation. To address these limitations, we introduce the Multi-Attribute Composition (MAC) dataset, encompassing 18,217 images and 11,067 compositions with comprehensive, representative, and diverse attribute annotations. MAC includes an average of 30.2 attributes per object and 65.4 objects per attribute, facilitating better multi-attribute composition predictions. Our dataset supports deeper semantic understanding and higher-order attribute associations, providing a more realistic and challenging benchmark for the CZSL task. We also develop solutions for multi-attribute compositional learning and propose the MM-encoder to disentangling the attributes and objects.
The Calibration Gap between Model and Human Confidence in Large Language Models
Jan 24, 2024For large language models (LLMs) to be trusted by humans they need to be well-calibrated in the sense that they can accurately assess and communicate how likely it is that their predictions are correct. Recent work has focused on the quality of internal LLM confidence assessments, but the question remains of how well LLMs can communicate this internal model confidence to human users. This paper explores the disparity between external human confidence in an LLM's responses and the internal confidence of the model. Through experiments involving multiple-choice questions, we systematically examine human users' ability to discern the reliability of LLM outputs. Our study focuses on two key areas: (1) assessing users' perception of true LLM confidence and (2) investigating the impact of tailored explanations on this perception. The research highlights that default explanations from LLMs often lead to user overestimation of both the model's confidence and its' accuracy. By modifying the explanations to more accurately reflect the LLM's internal confidence, we observe a significant shift in user perception, aligning it more closely with the model's actual confidence levels. This adjustment in explanatory approach demonstrates potential for enhancing user trust and accuracy in assessing LLM outputs. The findings underscore the importance of transparent communication of confidence levels in LLMs, particularly in high-stakes applications where understanding the reliability of AI-generated information is essential.
Volumetric Medical Image Segmentation via Scribble Annotations and Shape Priors
Oct 12, 2023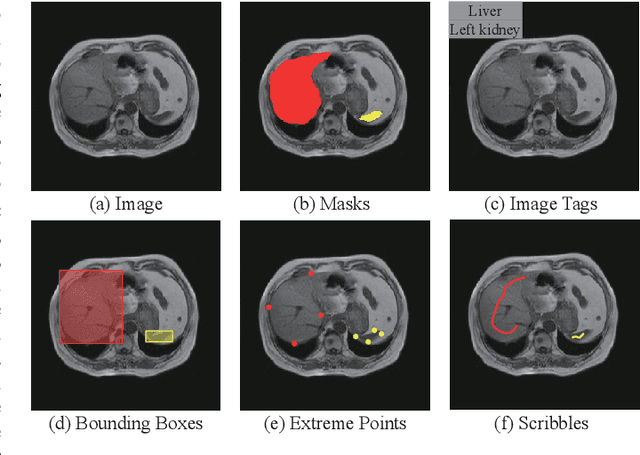
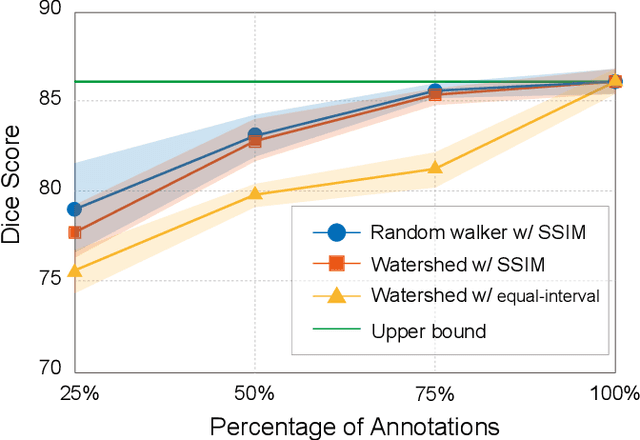
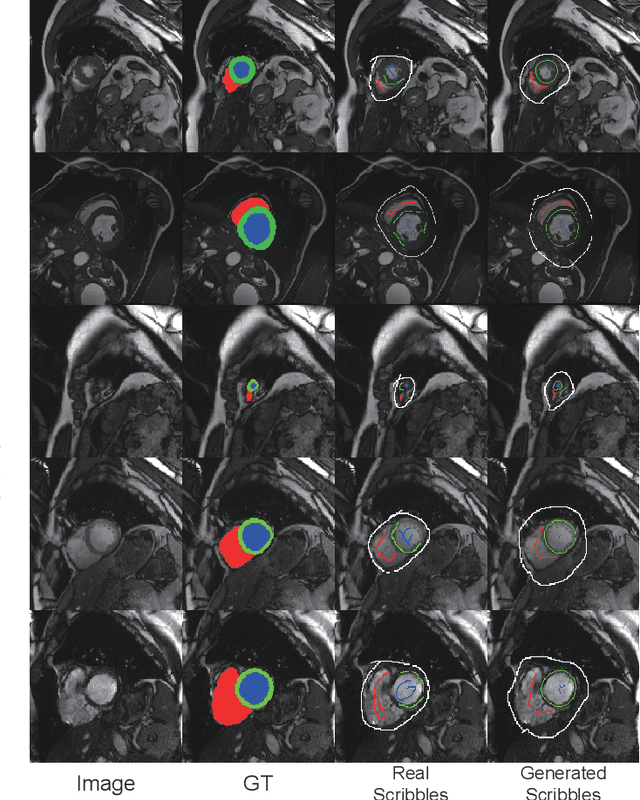
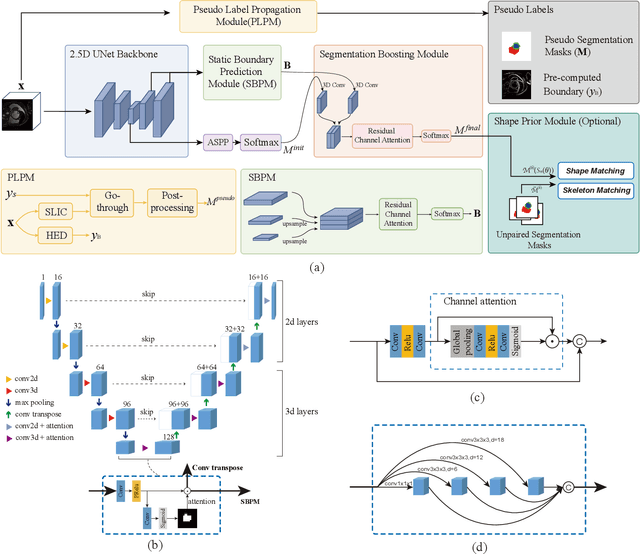
Recently, weakly-supervised image segmentation using weak annotations like scribbles has gained great attention in computer vision and medical image analysis, since such annotations are much easier to obtain compared to time-consuming and labor-intensive labeling at the pixel/voxel level. However, due to a lack of structure supervision on regions of interest (ROIs), existing scribble-based methods suffer from poor boundary localization. Furthermore, most current methods are designed for 2D image segmentation, which do not fully leverage the volumetric information if directly applied to each image slice. In this paper, we propose a scribble-based volumetric image segmentation, Scribble2D5, which tackles 3D anisotropic image segmentation and aims to its improve boundary prediction. To achieve this, we augment a 2.5D attention UNet with a proposed label propagation module to extend semantic information from scribbles and use a combination of static and active boundary prediction to learn ROI's boundary and regularize its shape. Also, we propose an optional add-on component, which incorporates the shape prior information from unpaired segmentation masks to further improve model accuracy. Extensive experiments on three public datasets and one private dataset demonstrate our Scribble2D5 achieves state-of-the-art performance on volumetric image segmentation using scribbles and shape prior if available.