 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExamining DOM Coordinate Effectiveness For Page Segmentation
Jan 14, 2026Web pages form a cornerstone of available data for daily human consumption and with the rise of LLM-based search and learning systems a treasure trove of valuable data. The scale of this data and its unstructured format still continue to grow requiring ever more robust automated extraction and retrieval mechanisms. Existing work, leveraging the web pages Document Object Model (DOM), often derives clustering vectors from coordinates informed by the DOM such as visual placement or tree structure. The construction and component value of these vectors often go unexamined. Our work proposes and examines DOM coordinates in a detail to understand their impact on web page segmentation. Our work finds that there is no one-size-fits-all vector, and that visual coordinates under-perform compared to DOM coordinates by about 20-30% on average. This challenges the necessity of including visual coordinates in clustering vectors. Further, our work finds that simple vectors, comprised of single coordinates, fare better than complex vectors constituting 68.2% of the top performing vectors of the pages examined. Finally, we find that if a vector, clustering algorithm, and page are properly matched, one can achieve overall high segmentation accuracy at 74%. This constitutes a 20% improvement over a naive application of vectors. Conclusively, our results challenge the current orthodoxy for segmentation vector creation, opens up the possibility to optimize page segmentation via clustering on DOM coordinates, and highlights the importance of finding mechanisms to match the best approach for web page segmentation.
Robust Multiple Description Neural Video Codec with Masked Transformer for Dynamic and Noisy Networks
Dec 10, 2024Multiple Description Coding (MDC) is a promising error-resilient source coding method that is particularly suitable for dynamic networks with multiple (yet noisy and unreliable) paths. However, conventional MDC video codecs suffer from cumbersome architectures, poor scalability, limited loss resilience, and lower compression efficiency. As a result, MDC has never been widely adopted. Inspired by the potential of neural video codecs, this paper rethinks MDC design. We propose a novel MDC video codec, NeuralMDC, demonstrating how bidirectional transformers trained for masked token prediction can vastly simplify the design of MDC video codec. To compress a video, NeuralMDC starts by tokenizing each frame into its latent representation and then splits the latent tokens to create multiple descriptions containing correlated information. Instead of using motion prediction and warping operations, NeuralMDC trains a bidirectional masked transformer to model the spatial-temporal dependencies of latent representations and predict the distribution of the current representation based on the past. The predicted distribution is used to independently entropy code each description and infer any potentially lost tokens. Extensive experiments demonstrate NeuralMDC achieves state-of-the-art loss resilience with minimal sacrifices in compression efficiency, significantly outperforming the best existing residual-coding-based error-resilient neural video codec.
CLARA: A Constrained Reinforcement Learning Based Resource Allocation Framework for Network Slicing
Nov 16, 2021As mobile networks proliferate, we are experiencing a strong diversification of services, which requires greater flexibility from the existing network. Network slicing is proposed as a promising solution for resource utilization in 5G and future networks to address this dire need. In network slicing, dynamic resource orchestration and network slice management are crucial for maximizing resource utilization. Unfortunately, this process is too complex for traditional approaches to be effective due to a lack of accurate models and dynamic hidden structures. We formulate the problem as a Constrained Markov Decision Process (CMDP) without knowing models and hidden structures. Additionally, we propose to solve the problem using CLARA, a Constrained reinforcement LeArning based Resource Allocation algorithm. In particular, we analyze cumulative and instantaneous constraints using adaptive interior-point policy optimization and projection layer, respectively. Evaluations show that CLARA clearly outperforms baselines in resource allocation with service demand guarantees.
$f$-GAIL: Learning $f$-Divergence for Generative Adversarial Imitation Learning
Oct 02, 2020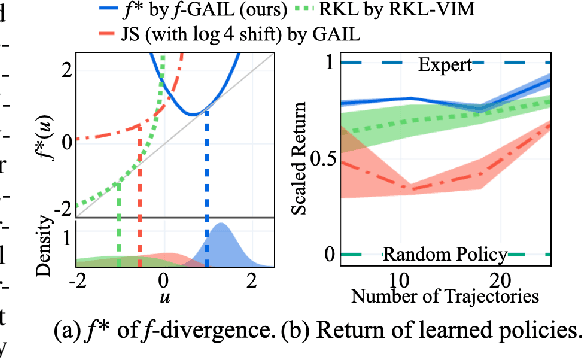
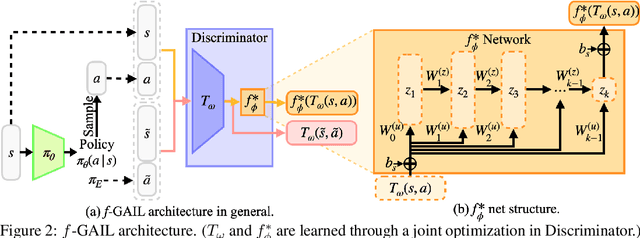

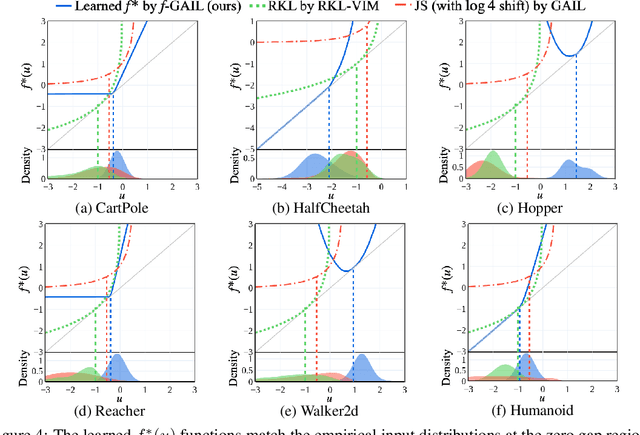
Imitation learning (IL) aims to learn a policy from expert demonstrations that minimizes the discrepancy between the learner and expert behaviors. Various imitation learning algorithms have been proposed with different pre-determined divergences to quantify the discrepancy. This naturally gives rise to the following question: Given a set of expert demonstrations, which divergence can recover the expert policy more accurately with higher data efficiency? In this work, we propose $f$-GAIL, a new generative adversarial imitation learning (GAIL) model, that automatically learns a discrepancy measure from the $f$-divergence family as well as a policy capable of producing expert-like behaviors. Compared with IL baselines with various predefined divergence measures, $f$-GAIL learns better policies with higher data efficiency in six physics-based control tasks.
Modeling Personalized Item Frequency Information for Next-basket Recommendation
May 31, 2020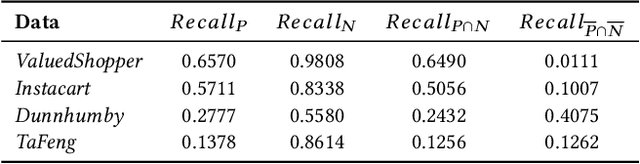



Next-basket recommendation (NBR) is prevalent in e-commerce and retail industry. In this scenario, a user purchases a set of items (a basket) at a time. NBR performs sequential modeling and recommendation based on a sequence of baskets. NBR is in general more complex than the widely studied sequential (session-based) recommendation which recommends the next item based on a sequence of items. Recurrent neural network (RNN) has proved to be very effective for sequential modeling and thus been adapted for NBR. However, we argue that existing RNNs cannot directly capture item frequency information in the recommendation scenario. Through careful analysis of real-world datasets, we find that {\em personalized item frequency} (PIF) information (which records the number of times that each item is purchased by a user) provides two critical signals for NBR. But, this has been largely ignored by existing methods. Even though existing methods such as RNN based methods have strong representation ability, our empirical results show that they fail to learn and capture PIF. As a result, existing methods cannot fully exploit the critical signals contained in PIF. Given this inherent limitation of RNNs, we propose a simple item frequency based k-nearest neighbors (kNN) method to directly utilize these critical signals. We evaluate our method on four public real-world datasets. Despite its relative simplicity, our method frequently outperforms the state-of-the-art NBR methods -- including deep learning based methods using RNNs -- when patterns associated with PIF play an important role in the data.
Physics-Guided Deep Neural Networks for PowerFlow Analysis
Jan 31, 2020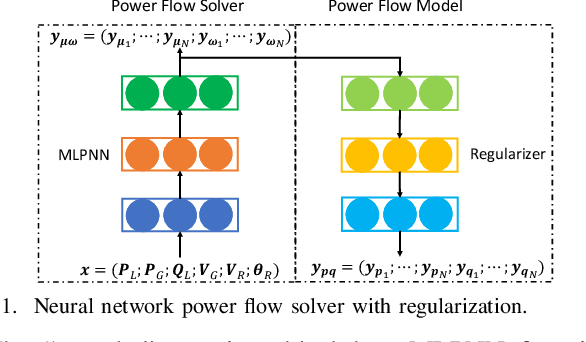
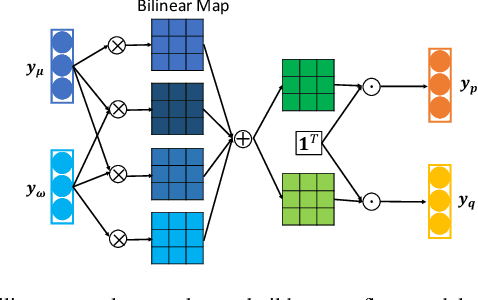

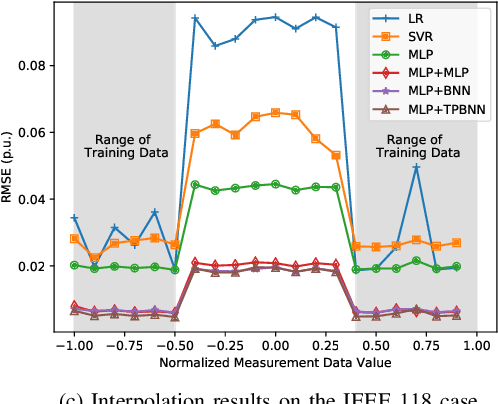
Solving power flow (PF) equations is the basis of power flow analysis, which is important in determining the best operation of existing systems, performing security analysis, etc. However, PF equations can be out-of-date or even unavailable due to system dynamics and uncertainties, making traditional numerical approaches infeasible. To address these concerns, researchers have proposed data-driven approaches to solve the PF problem by learning the mapping rules from historical system operation data. Nevertheless, prior data-driven approaches suffer from poor performance and generalizability, due to overly simplified assumptions of the PF problem or ignorance of physical laws governing power systems. In this paper, we propose a physics-guided neural network to solve the PF problem, with an auxiliary task to rebuild the PF model. By encoding different granularity of Kirchhoff's laws and system topology into the rebuilt PF model, our neural-network based PF solver is regularized by the auxiliary task and constrained by the physical laws. The simulation results show that our physics-guided neural network methods achieve better performance and generalizability compared to existing unconstrained data-driven approaches. Furthermore, we demonstrate that the weight matrices of our physics-guided neural networks embody power system physics by showing their similarities with the bus admittance matrices.
Deep Universal Graph Embedding Neural Network
Sep 25, 2019
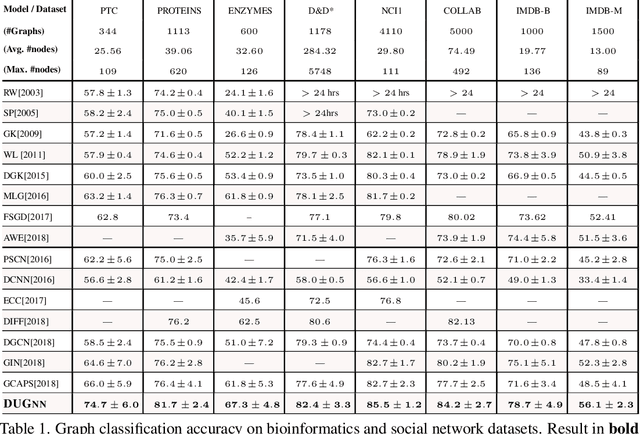
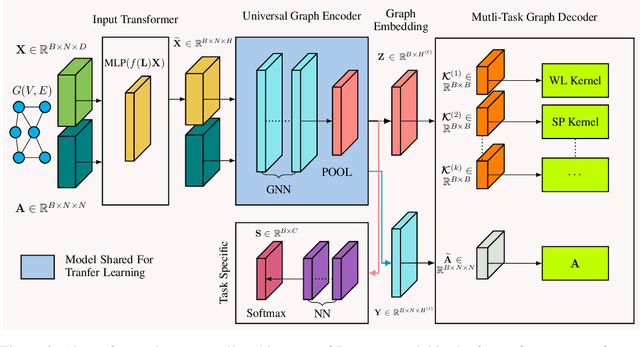

Learning powerful data embeddings has become a center piece in machine learning, especially in natural language processing and computer vision domains. The crux of these embeddings is that they are pretrained on huge corpus of data in a unsupervised fashion, sometimes aided with transfer learning. However currently in the graph learning domain, embeddings learned through existing graph neural networks (GNNs) are task dependent and thus cannot be shared across different datasets. In this paper, we present a first powerful and theoretically guaranteed graph neural network that is designed to learn task-independent graph embeddings, thereafter referred to as deep universal graph embedding (DUGNN). Our DUGNN model incorporates a novel graph neural network (as a universal graph encoder) and leverages rich Graph Kernels (as a multi-task graph decoder) for both unsupervised learning and (task-specific) adaptive supervised learning. By learning task-independent graph embeddings across diverse datasets, DUGNN also reaps the benefits of transfer learning. Through extensive experiments and ablation studies, we show that the proposed DUGNN model consistently outperforms both the existing state-of-art GNN models and Graph Kernels by an increased accuracy of 3% - 8% on graph classification benchmark datasets.
Stability and Generalization of Graph Convolutional Neural Networks
May 14, 2019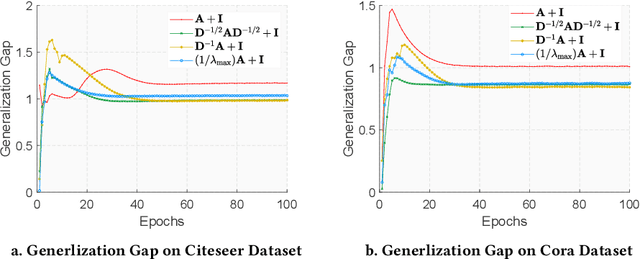

Inspired by convolutional neural networks on 1D and 2D data, graph convolutional neural networks (GCNNs) have been developed for various learning tasks on graph data, and have shown superior performance on real-world datasets. Despite their success, there is a dearth of theoretical explorations of GCNN models such as their generalization properties. In this paper, we take a first step towards developing a deeper theoretical understanding of GCNN models by analyzing the stability of single-layer GCNN models and deriving their generalization guarantees in a semi-supervised graph learning setting. In particular, we show that the algorithmic stability of a GCNN model depends upon the largest absolute eigenvalue of its graph convolution filter. Moreover, to ensure the uniform stability needed to provide strong generalization guarantees, the largest absolute eigenvalue must be independent of the graph size. Our results shed new insights on the design of new & improved graph convolution filters with guaranteed algorithmic stability. We evaluate the generalization gap and stability on various real-world graph datasets and show that the empirical results indeed support our theoretical findings. To the best of our knowledge, we are the first to study stability bounds on graph learning in a semi-supervised setting and derive generalization bounds for GCNN models.
Graph Capsule Convolutional Neural Networks
Aug 26, 2018

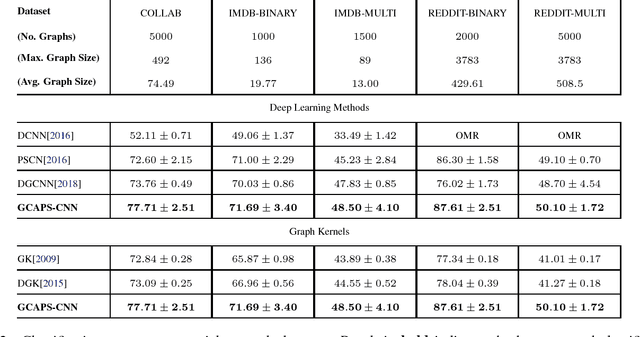
Graph Convolutional Neural Networks (GCNNs) are the most recent exciting advancement in deep learning field and their applications are quickly spreading in multi-cross-domains including bioinformatics, chemoinformatics, social networks, natural language processing and computer vision. In this paper, we expose and tackle some of the basic weaknesses of a GCNN model with a capsule idea presented in \cite{hinton2011transforming} and propose our Graph Capsule Network (GCAPS-CNN) model. In addition, we design our GCAPS-CNN model to solve especially graph classification problem which current GCNN models find challenging. Through extensive experiments, we show that our proposed Graph Capsule Network can significantly outperforms both the existing state-of-art deep learning methods and graph kernels on graph classification benchmark datasets.