 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvoking Multi-modal Few-Shot LVLM via Exploration-Exploitation In-Context Learning
Jun 11, 2025In-context learning (ICL), a predominant trend in instruction learning, aims at enhancing the performance of large language models by providing clear task guidance and examples, improving their capability in task understanding and execution. This paper investigates ICL on Large Vision-Language Models (LVLMs) and explores the policies of multi-modal demonstration selection. Existing research efforts in ICL face significant challenges: First, they rely on pre-defined demonstrations or heuristic selecting strategies based on human intuition, which are usually inadequate for covering diverse task requirements, leading to sub-optimal solutions; Second, individually selecting each demonstration fails in modeling the interactions between them, resulting in information redundancy. Unlike these prevailing efforts, we propose a new exploration-exploitation reinforcement learning framework, which explores policies to fuse multi-modal information and adaptively select adequate demonstrations as an integrated whole. The framework allows LVLMs to optimize themselves by continually refining their demonstrations through self-exploration, enabling the ability to autonomously identify and generate the most effective selection policies for in-context learning. Experimental results verify the superior performance of our approach on four Visual Question-Answering (VQA) datasets, demonstrating its effectiveness in enhancing the generalization capability of few-shot LVLMs.
Incentivizing Strong Reasoning from Weak Supervision
May 28, 2025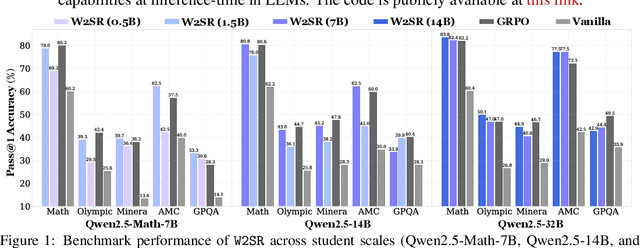
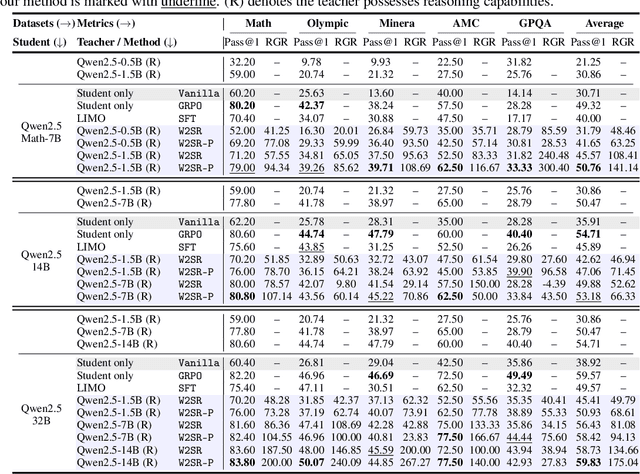
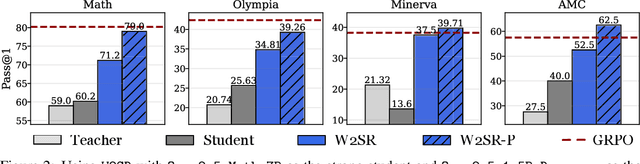
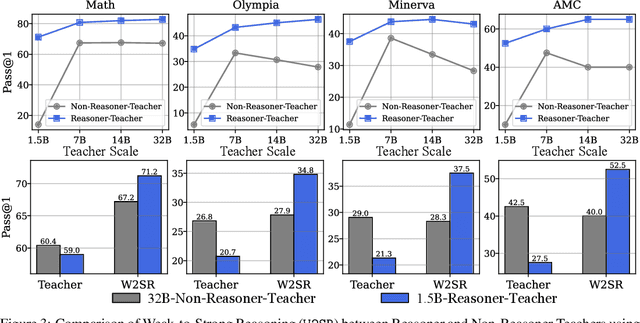
Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/w2sr.
Incentivizing Reasoning from Weak Supervision
May 26, 2025Large language models (LLMs) have demonstrated impressive performance on reasoning-intensive tasks, but enhancing their reasoning abilities typically relies on either reinforcement learning (RL) with verifiable signals or supervised fine-tuning (SFT) with high-quality long chain-of-thought (CoT) demonstrations, both of which are expensive. In this paper, we study a novel problem of incentivizing the reasoning capacity of LLMs without expensive high-quality demonstrations and reinforcement learning. We investigate whether the reasoning capabilities of LLMs can be effectively incentivized via supervision from significantly weaker models. We further analyze when and why such weak supervision succeeds in eliciting reasoning abilities in stronger models. Our findings show that supervision from significantly weaker reasoners can substantially improve student reasoning performance, recovering close to 94% of the gains of expensive RL at a fraction of the cost. Experiments across diverse benchmarks and model architectures demonstrate that weak reasoners can effectively incentivize reasoning in stronger student models, consistently improving performance across a wide range of reasoning tasks. Our results suggest that this simple weak-to-strong paradigm is a promising and generalizable alternative to costly methods for incentivizing strong reasoning capabilities at inference-time in LLMs. The code is publicly available at https://github.com/yuanyige/W2SR.
Evaluation Report on MCP Servers
Apr 15, 2025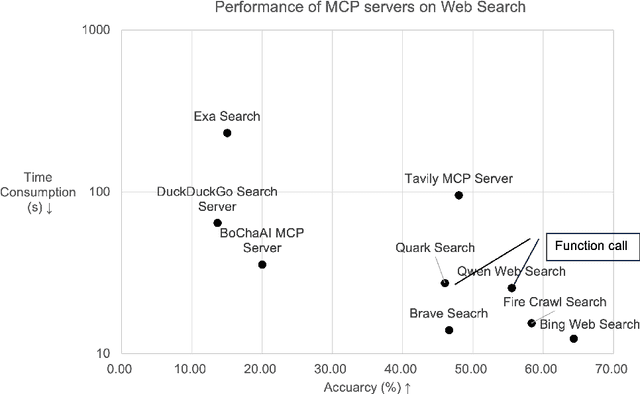
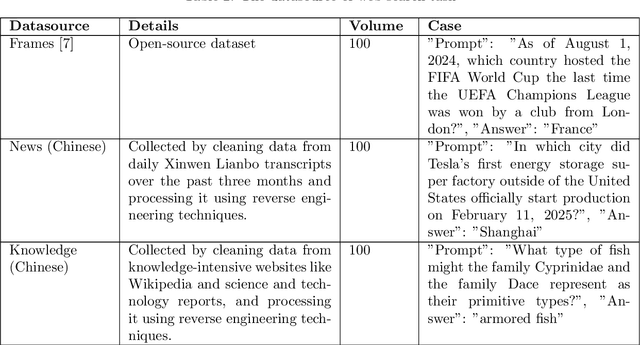

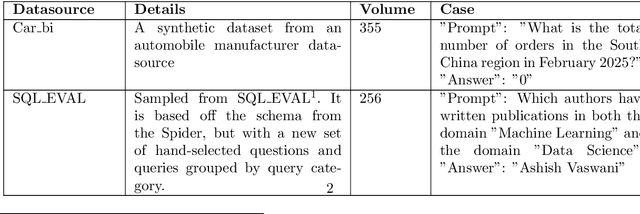
With the rise of LLMs, a large number of Model Context Protocol (MCP) services have emerged since the end of 2024. However, the effectiveness and efficiency of MCP servers have not been well studied. To study these questions, we propose an evaluation framework, called MCPBench. We selected several widely used MCP server and conducted an experimental evaluation on their accuracy, time, and token usage. Our experiments showed that the most effective MCP, Bing Web Search, achieved an accuracy of 64%. Importantly, we found that the accuracy of MCP servers can be substantially enhanced by involving declarative interface. This research paves the way for further investigations into optimized MCP implementations, ultimately leading to better AI-driven applications and data retrieval solutions.
RePO: ReLU-based Preference Optimization
Mar 10, 2025Aligning large language models (LLMs) with human preferences is critical for real-world deployment, yet existing methods like RLHF face computational and stability challenges. While DPO establishes an offline paradigm with single hyperparameter $\beta$, subsequent methods like SimPO reintroduce complexity through dual parameters ($\beta$, $\gamma$). We propose {ReLU-based Preference Optimization (RePO)}, a streamlined algorithm that eliminates $\beta$ via two advances: (1) retaining SimPO's reference-free margins but removing $\beta$ through gradient analysis, and (2) adopting a ReLU-based max-margin loss that naturally filters trivial pairs. Theoretically, RePO is characterized as SimPO's limiting case ($\beta \to \infty$), where the logistic weighting collapses to binary thresholding, forming a convex envelope of the 0-1 loss. Empirical results on AlpacaEval 2 and Arena-Hard show that RePO outperforms DPO and SimPO across multiple base models, requiring only one hyperparameter to tune.
ToolCoder: A Systematic Code-Empowered Tool Learning Framework for Large Language Models
Feb 17, 2025
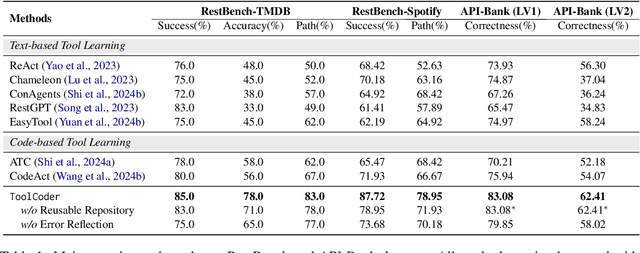
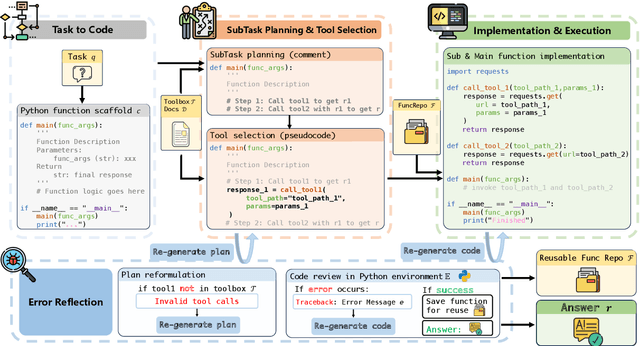
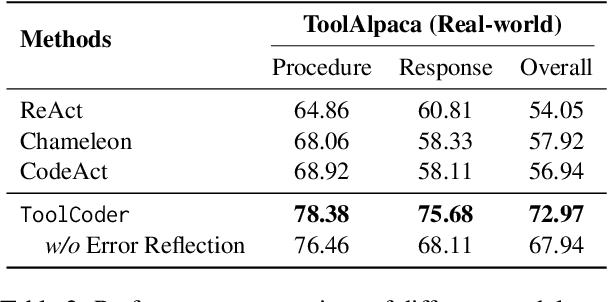
Tool learning has emerged as a crucial capability for large language models (LLMs) to solve complex real-world tasks through interaction with external tools. Existing approaches face significant challenges, including reliance on hand-crafted prompts, difficulty in multi-step planning, and lack of precise error diagnosis and reflection mechanisms. We propose ToolCoder, a novel framework that reformulates tool learning as a code generation task. Inspired by software engineering principles, ToolCoder transforms natural language queries into structured Python function scaffold and systematically breaks down tasks with descriptive comments, enabling LLMs to leverage coding paradigms for complex reasoning and planning. It then generates and executes function implementations to obtain final responses. Additionally, ToolCoder stores successfully executed functions in a repository to promote code reuse, while leveraging error traceback mechanisms for systematic debugging, optimizing both execution efficiency and robustness. Experiments demonstrate that ToolCoder achieves superior performance in task completion accuracy and execution reliability compared to existing approaches, establishing the effectiveness of code-centric approaches in tool learning.
XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL
Nov 13, 2024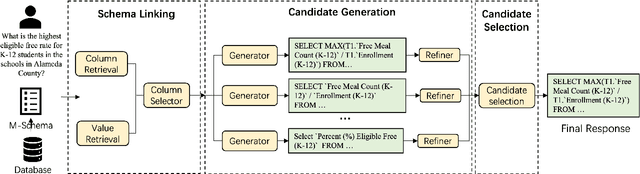
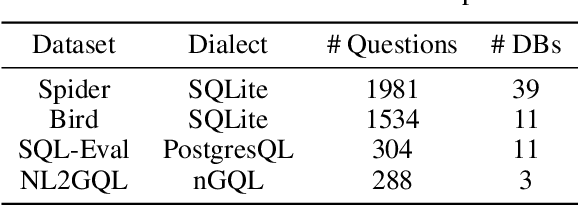


To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation. We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning. On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences. On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent overemphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors. To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries. The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios. Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of 89.65% on the Spider test set, 69.86% on SQL-Eval, 41.20% on NL2GQL, and a competitive score of 72.23% on the Bird development benchmark. The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.
What is Wrong with Perplexity for Long-context Language Modeling?
Oct 31, 2024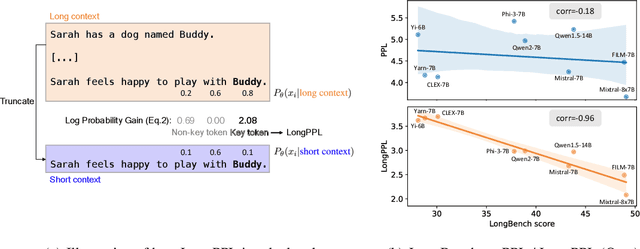

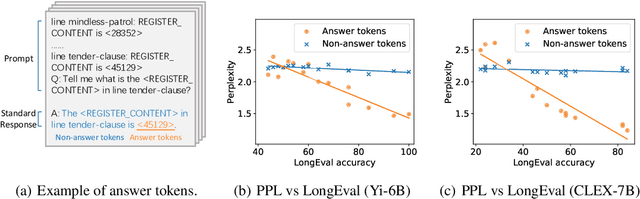
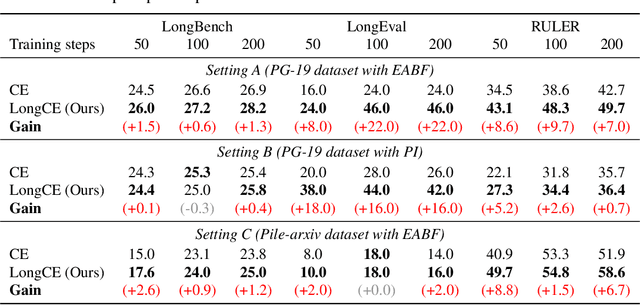
Handling long-context inputs is crucial for large language models (LLMs) in tasks such as extended conversations, document summarization, and many-shot in-context learning. While recent approaches have extended the context windows of LLMs and employed perplexity (PPL) as a standard evaluation metric, PPL has proven unreliable for assessing long-context capabilities. The underlying cause of this limitation has remained unclear. In this work, we provide a comprehensive explanation for this issue. We find that PPL overlooks key tokens, which are essential for long-context understanding, by averaging across all tokens and thereby obscuring the true performance of models in long-context scenarios. To address this, we propose \textbf{LongPPL}, a novel metric that focuses on key tokens by employing a long-short context contrastive method to identify them. Our experiments demonstrate that LongPPL strongly correlates with performance on various long-context benchmarks (e.g., Pearson correlation of -0.96), significantly outperforming traditional PPL in predictive accuracy. Additionally, we introduce \textbf{LongCE} (Long-context Cross-Entropy) loss, a re-weighting strategy for fine-tuning that prioritizes key tokens, leading to consistent improvements across diverse benchmarks. In summary, these contributions offer deeper insights into the limitations of PPL and present effective solutions for accurately evaluating and enhancing the long-context capabilities of LLMs. Code is available at https://github.com/PKU-ML/LongPPL.
MoMQ: Mixture-of-Experts Enhances Multi-Dialect Query Generation across Relational and Non-Relational Databases
Oct 24, 2024



The improvement in translating natural language to structured query language (SQL) can be attributed to the advancements in large language models (LLMs). Open-source LLMs, tailored for specific database dialects such as MySQL, have shown great performance. However, cloud service providers are looking for a unified database manager service (e.g., Cosmos DB from Azure, Amazon Aurora from AWS, Lindorm from AlibabaCloud) that can support multiple dialects. This requirement has led to the concept of multi-dialect query generation, which presents challenges to LLMs. These challenges include syntactic differences among dialects and imbalanced data distribution across multiple dialects. To tackle these challenges, we propose MoMQ, a novel Mixture-of-Experts-based multi-dialect query generation framework across both relational and non-relational databases. MoMQ employs a dialect expert group for each dialect and a multi-level routing strategy to handle dialect-specific knowledge, reducing interference during query generation. Additionally, a shared expert group is introduced to address data imbalance, facilitating the transfer of common knowledge from high-resource dialects to low-resource ones. Furthermore, we have developed a high-quality multi-dialect query generation benchmark that covers relational and non-relational databases such as MySQL, PostgreSQL, Cypher for Neo4j, and nGQL for NebulaGraph. Extensive experiments have shown that MoMQ performs effectively and robustly even in resource-imbalanced scenarios.
$α$-DPO: Adaptive Reward Margin is What Direct Preference Optimization Needs
Oct 14, 2024



Aligning large language models (LLMs) with human values and intentions is crucial for their utility, honesty, and safety. Reinforcement learning from human feedback (RLHF) is a popular approach to achieve this alignment, but it faces challenges in computational efficiency and training stability. Recent methods like Direct Preference Optimization (DPO) and Simple Preference Optimization (SimPO) have proposed offline alternatives to RLHF, simplifying the process by reparameterizing the reward function. However, DPO depends on a potentially suboptimal reference model, and SimPO's assumption of a fixed target reward margin may lead to suboptimal decisions in diverse data settings. In this work, we propose $\alpha$-DPO, an adaptive preference optimization algorithm designed to address these limitations by introducing a dynamic reward margin. Specifically, $\alpha$-DPO employs an adaptive preference distribution, balancing the policy model and the reference model to achieve personalized reward margins. We provide theoretical guarantees for $\alpha$-DPO, demonstrating its effectiveness as a surrogate optimization objective and its ability to balance alignment and diversity through KL divergence control. Empirical evaluations on AlpacaEval 2 and Arena-Hard show that $\alpha$-DPO consistently outperforms DPO and SimPO across various model settings, establishing it as a robust approach for fine-tuning LLMs. Our method achieves significant improvements in win rates, highlighting its potential as a powerful tool for LLM alignment. The code is available at https://github.com/junkangwu/alpha-DPO