 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL
Nov 13, 2024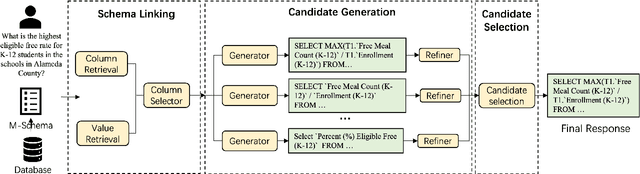
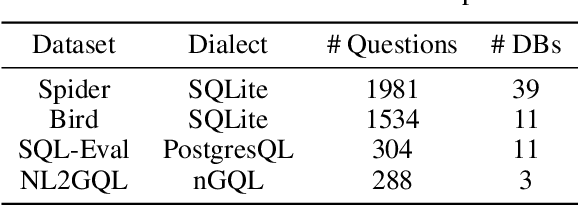


To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation. We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning. On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences. On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent overemphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors. To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries. The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios. Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of 89.65% on the Spider test set, 69.86% on SQL-Eval, 41.20% on NL2GQL, and a competitive score of 72.23% on the Bird development benchmark. The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.