 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn then Decide: A Learning Approach for Designing Data Marketplaces
Mar 13, 2025



As data marketplaces become increasingly central to the digital economy, it is crucial to design efficient pricing mechanisms that optimize revenue while ensuring fair and adaptive pricing. We introduce the Maximum Auction-to-Posted Price (MAPP) mechanism, a novel two-stage approach that first estimates the bidders' value distribution through auctions and then determines the optimal posted price based on the learned distribution. We establish that MAPP is individually rational and incentive-compatible, ensuring truthful bidding while balancing revenue maximization with minimal price discrimination. MAPP achieves a regret of $O_p(n^{-1})$ when incorporating historical bid data, where $n$ is the number of bids in the current round. It outperforms existing methods while imposing weaker distributional assumptions. For sequential dataset sales over $T$ rounds, we propose an online MAPP mechanism that dynamically adjusts pricing across datasets with varying value distributions. Our approach achieves no-regret learning, with the average cumulative regret converging at a rate of $O_p(T^{-1/2}(\log T)^2)$. We validate the effectiveness of MAPP through simulations and real-world data from the FCC AWS-3 spectrum auction.
Automatic database description generation for Text-to-SQL
Feb 28, 2025In the context of the Text-to-SQL task, table and column descriptions are crucial for bridging the gap between natural language and database schema. This report proposes a method for automatically generating effective database descriptions when explicit descriptions are unavailable. The proposed method employs a dual-process approach: a coarse-to-fine process, followed by a fine-to-coarse process. The coarse-to-fine approach leverages the inherent knowledge of LLM to guide the understanding process from databases to tables and finally to columns. This approach provides a holistic understanding of the database structure and ensures contextual alignment. Conversely, the fine-to-coarse approach starts at the column level, offering a more accurate and nuanced understanding when stepping back to the table level. Experimental results on the Bird benchmark indicate that using descriptions generated by the proposed improves SQL generation accuracy by 0.93\% compared to not using descriptions, and achieves 37\% of human-level performance. The source code is publicly available at https://github.com/XGenerationLab/XiYan-DBDescGen.
XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL
Nov 13, 2024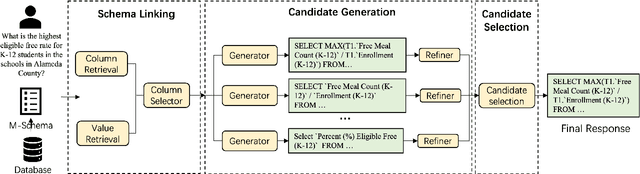
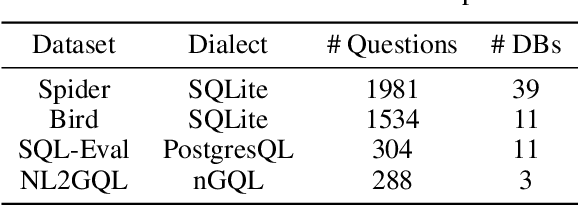


To tackle the challenges of large language model performance in natural language to SQL tasks, we introduce XiYan-SQL, an innovative framework that employs a multi-generator ensemble strategy to improve candidate generation. We introduce M-Schema, a semi-structured schema representation method designed to enhance the understanding of database structures. To enhance the quality and diversity of generated candidate SQL queries, XiYan-SQL integrates the significant potential of in-context learning (ICL) with the precise control of supervised fine-tuning. On one hand, we propose a series of training strategies to fine-tune models to generate high-quality candidates with diverse preferences. On the other hand, we implement the ICL approach with an example selection method based on named entity recognition to prevent overemphasis on entities. The refiner optimizes each candidate by correcting logical or syntactical errors. To address the challenge of identifying the best candidate, we fine-tune a selection model to distinguish nuances of candidate SQL queries. The experimental results on multiple dialect datasets demonstrate the robustness of XiYan-SQL in addressing challenges across different scenarios. Overall, our proposed XiYan-SQL achieves the state-of-the-art execution accuracy of 89.65% on the Spider test set, 69.86% on SQL-Eval, 41.20% on NL2GQL, and a competitive score of 72.23% on the Bird development benchmark. The proposed framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods.
Retrieval-Generation Alignment for End-to-End Task-Oriented Dialogue System
Oct 20, 2023Developing an efficient retriever to retrieve knowledge from a large-scale knowledge base (KB) is critical for task-oriented dialogue systems to effectively handle localized and specialized tasks. However, widely used generative models such as T5 and ChatGPT often struggle to differentiate subtle differences among the retrieved KB records when generating responses, resulting in suboptimal quality of generated responses. In this paper, we propose the application of maximal marginal likelihood to train a perceptive retriever by utilizing signals from response generation for supervision. In addition, our approach goes beyond considering solely retrieved entities and incorporates various meta knowledge to guide the generator, thus improving the utilization of knowledge. We evaluate our approach on three task-oriented dialogue datasets using T5 and ChatGPT as the backbone models. The results demonstrate that when combined with meta knowledge, the response generator can effectively leverage high-quality knowledge records from the retriever and enhance the quality of generated responses. The codes and models of this paper are available at https://github.com/shenwzh3/MK-TOD.
Deeply supervised neural network with short connections for retinal vessel segmentation
Mar 11, 2018

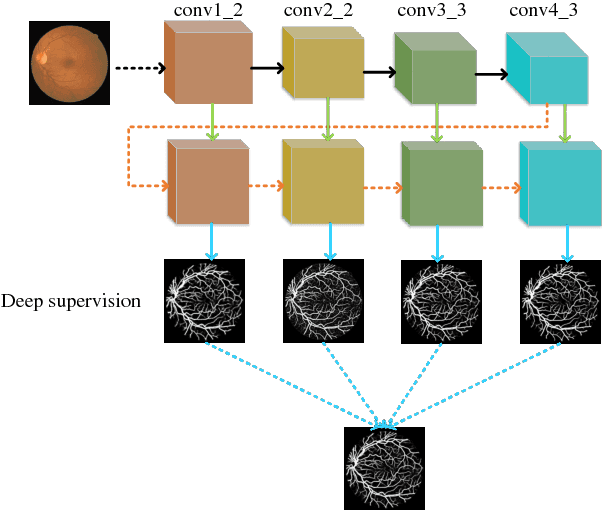
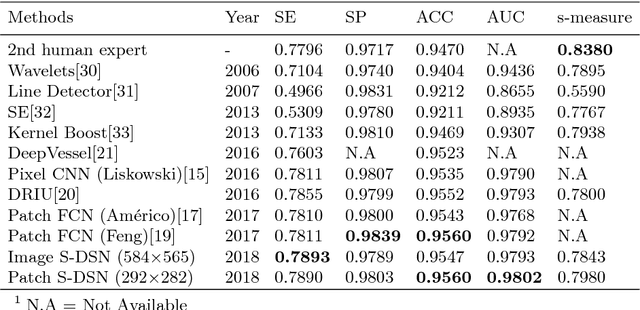
The condition of vessel of the human eye is a fundamental factor for the diagnosis of ophthalmological diseases. Vessel segmentation in fundus image is a challenging task due to low contrast, the presence of microaneurysms and hemorrhages. In this paper, we present a multi-scale and multi-level deeply supervised convolutional neural network with short connections for vessel segmentation. We use short connections to transfer semantic information between side-output layers. Forward short connections could pass low level semantic information to high level and backward short connections could pass much structural information to low level. In addition, we propose using a structural similarity measurement to evaluate the vessel map. The proposed method is verified on DRIVE dataset and it shows superior performance compared with other state-of-the-art methods. Specially, with patch level input, the network gets 0.7890 sensitivity, 0.9803 specificity and 0.9802 AUC. Code will be made available at https://github.com/guomugong/sdsn.