 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuseChat-3.0: Preference Optimization Meets Heterogeneous Model Fusion
Mar 06, 2025We introduce FuseChat-3.0, a suite of large language models (LLMs) developed by integrating the strengths of heterogeneous source LLMs into more compact target LLMs. Our source models include the powerful Gemma-2-27B-it, Mistral-Large-Instruct-2407, Qwen-2.5-72B-Instruct, and Llama-3.1-70B-Instruct. For target models, we focus on three widely-used smaller variants-Llama-3.1-8B-Instruct, Gemma-2-9B-it, and Qwen-2.5-7B-Instruct-along with two ultra-compact options, Llama-3.2-3B-Instruct and Llama-3.2-1B-Instruct. To leverage the diverse capabilities of these source models, we develop a specialized data construction protocol tailored to various tasks and domains. The FuseChat-3.0 training pipeline consists of two key stages: (1) supervised fine-tuning (SFT) to align the target and source model distributions, and (2) Direct Preference Optimization (DPO) to apply preferences from multiple source LLMs to fine-tune the target model. The resulting FuseChat-3.0 models exhibit significant performance gains across tasks such as instruction following, general knowledge, mathematics, and coding. As illustrated in Figure 1, using Llama-3.1-8B-Instruct as the target model, our fusion approach achieves an average improvement of 6.8 points across 14 benchmarks. Moreover, it demonstrates remarkable gains of 37.1 points and 30.1 points on the instruction-following benchmarks AlpacaEval-2 and Arena-Hard, respectively. Our code, models, and datasets are available at https://github.com/SLIT-AI/FuseChat-3.0.
ProFuser: Progressive Fusion of Large Language Models
Aug 09, 2024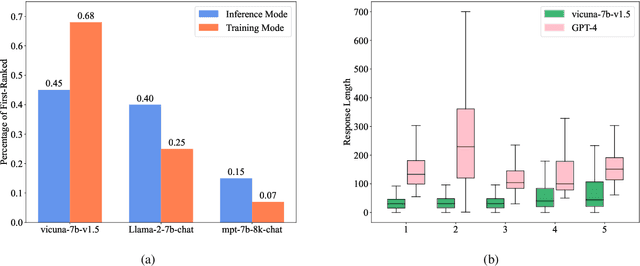
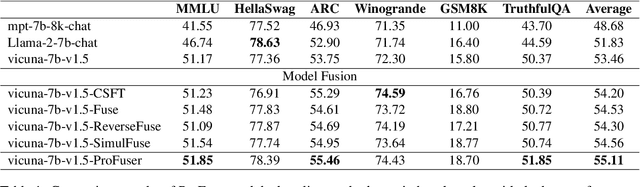

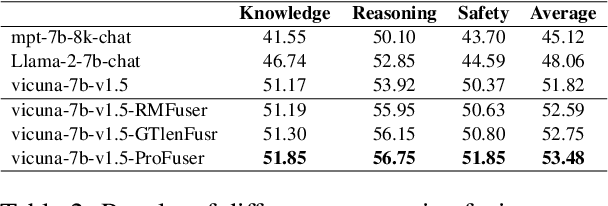
While fusing the capacities and advantages of various large language models (LLMs) offers a pathway to construct more powerful and versatile models, a fundamental challenge is to properly select advantageous model during the training. Existing fusion methods primarily focus on the training mode that uses cross entropy on ground truth in a teacher-forcing setup to measure a model's advantage, which may provide limited insight towards model advantage. In this paper, we introduce a novel approach that enhances the fusion process by incorporating both the training and inference modes. Our method evaluates model advantage not only through cross entropy during training but also by considering inference outputs, providing a more comprehensive assessment. To combine the two modes effectively, we introduce ProFuser to progressively transition from inference mode to training mode. To validate ProFuser's effectiveness, we fused three models, including vicuna-7b-v1.5, Llama-2-7b-chat, and mpt-7b-8k-chat, and demonstrated the improved performance in knowledge, reasoning, and safety compared to baseline methods.
Retrieval-Generation Alignment for End-to-End Task-Oriented Dialogue System
Oct 20, 2023Developing an efficient retriever to retrieve knowledge from a large-scale knowledge base (KB) is critical for task-oriented dialogue systems to effectively handle localized and specialized tasks. However, widely used generative models such as T5 and ChatGPT often struggle to differentiate subtle differences among the retrieved KB records when generating responses, resulting in suboptimal quality of generated responses. In this paper, we propose the application of maximal marginal likelihood to train a perceptive retriever by utilizing signals from response generation for supervision. In addition, our approach goes beyond considering solely retrieved entities and incorporates various meta knowledge to guide the generator, thus improving the utilization of knowledge. We evaluate our approach on three task-oriented dialogue datasets using T5 and ChatGPT as the backbone models. The results demonstrate that when combined with meta knowledge, the response generator can effectively leverage high-quality knowledge records from the retriever and enhance the quality of generated responses. The codes and models of this paper are available at https://github.com/shenwzh3/MK-TOD.