 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorpusQA: A 10 Million Token Benchmark for Corpus-Level Analysis and Reasoning
Jan 21, 2026While large language models now handle million-token contexts, their capacity for reasoning across entire document repositories remains largely untested. Existing benchmarks are inadequate, as they are mostly limited to single long texts or rely on a "sparse retrieval" assumption-that answers can be derived from a few relevant chunks. This assumption fails for true corpus-level analysis, where evidence is highly dispersed across hundreds of documents and answers require global integration, comparison, and statistical aggregation. To address this critical gap, we introduce CorpusQA, a new benchmark scaling up to 10 million tokens, generated via a novel data synthesis framework. By decoupling reasoning from textual representation, this framework creates complex, computation-intensive queries with programmatically guaranteed ground-truth answers, challenging systems to perform holistic reasoning over vast, unstructured text without relying on fallible human annotation. We further demonstrate the utility of our framework beyond evaluation, showing that fine-tuning on our synthesized data effectively enhances an LLM's general long-context reasoning capabilities. Extensive experiments reveal that even state-of-the-art long-context LLMs struggle as input length increases, and standard retrieval-augmented generation systems collapse entirely. Our findings indicate that memory-augmented agentic architectures offer a more robust alternative, suggesting a critical shift is needed from simply extending context windows to developing advanced architectures for global information synthesis.
Incentivizing In-depth Reasoning over Long Contexts with Process Advantage Shaping
Jan 18, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has proven effective in enhancing LLMs short-context reasoning, but its performance degrades in long-context scenarios that require both precise grounding and robust long-range reasoning. We identify the "almost-there" phenomenon in long-context reasoning, where trajectories are largely correct but fail at the final step, and attribute this failure to two factors: (1) the lack of high reasoning density in long-context QA data that push LLMs beyond mere grounding toward sophisticated multi-hop reasoning; and (2) the loss of valuable learning signals during long-context RL training due to the indiscriminate penalization of partially correct trajectories with incorrect outcomes. To overcome this bottleneck, we propose DeepReasonQA, a KG-driven synthesis framework that controllably constructs high-difficulty, multi-hop long-context QA pairs with inherent reasoning chains. Building on this, we introduce Long-context Process Advantage Shaping (LongPAS), a simple yet effective method that performs fine-grained credit assignment by evaluating reasoning steps along Validity and Relevance dimensions, which captures critical learning signals from "almost-there" trajectories. Experiments on three long-context reasoning benchmarks show that our approach substantially outperforms RLVR baselines and matches frontier LLMs while using far fewer parameters. Further analysis confirms the effectiveness of our methods in strengthening long-context reasoning while maintaining stable RL training.
QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
Dec 15, 2025We introduce QwenLong-L1.5, a model that achieves superior long-context reasoning capabilities through systematic post-training innovations. The key technical breakthroughs of QwenLong-L1.5 are as follows: (1) Long-Context Data Synthesis Pipeline: We develop a systematic synthesis framework that generates challenging reasoning tasks requiring multi-hop grounding over globally distributed evidence. By deconstructing documents into atomic facts and their underlying relationships, and then programmatically composing verifiable reasoning questions, our approach creates high-quality training data at scale, moving substantially beyond simple retrieval tasks to enable genuine long-range reasoning capabilities. (2) Stabilized Reinforcement Learning for Long-Context Training: To overcome the critical instability in long-context RL, we introduce task-balanced sampling with task-specific advantage estimation to mitigate reward bias, and propose Adaptive Entropy-Controlled Policy Optimization (AEPO) that dynamically regulates exploration-exploitation trade-offs. (3) Memory-Augmented Architecture for Ultra-Long Contexts: Recognizing that even extended context windows cannot accommodate arbitrarily long sequences, we develop a memory management framework with multi-stage fusion RL training that seamlessly integrates single-pass reasoning with iterative memory-based processing for tasks exceeding 4M tokens. Based on Qwen3-30B-A3B-Thinking, QwenLong-L1.5 achieves performance comparable to GPT-5 and Gemini-2.5-Pro on long-context reasoning benchmarks, surpassing its baseline by 9.90 points on average. On ultra-long tasks (1M~4M tokens), QwenLong-L1.5's memory-agent framework yields a 9.48-point gain over the agent baseline. Additionally, the acquired long-context reasoning ability translates to enhanced performance in general domains like scientific reasoning, memory tool using, and extended dialogue.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
WebSailor: Navigating Super-human Reasoning for Web Agent
Jul 03, 2025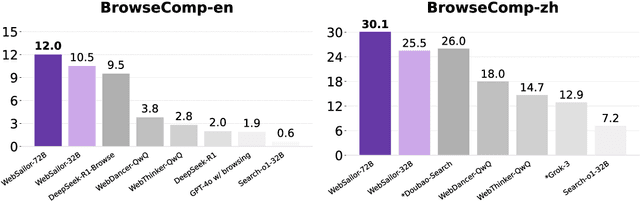
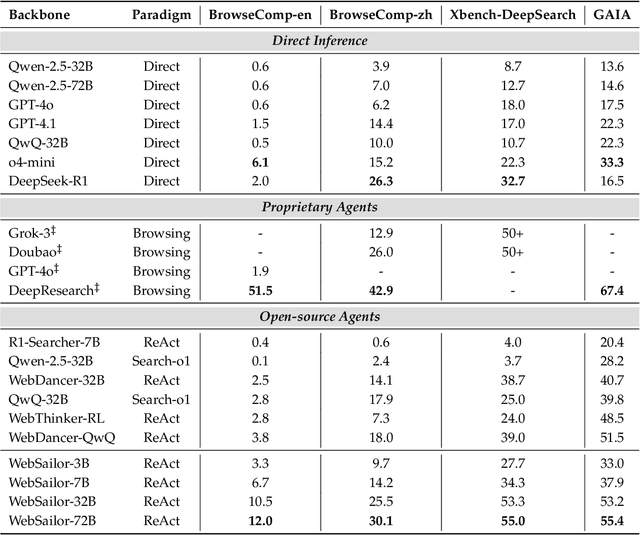
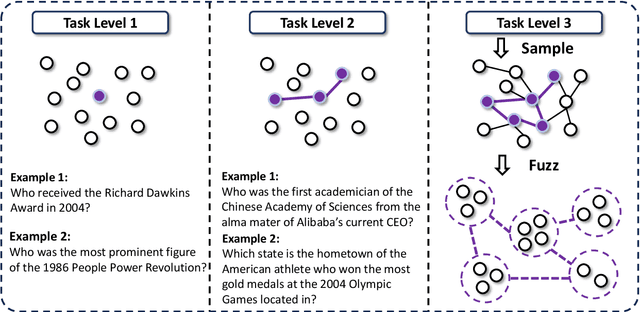

Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all opensource agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
Writing-RL: Advancing Long-form Writing via Adaptive Curriculum Reinforcement Learning
Jun 06, 2025Recent advances in Large Language Models (LLMs) have enabled strong performance in long-form writing, yet existing supervised fine-tuning (SFT) approaches suffer from limitations such as data saturation and restricted learning capacity bounded by teacher signals. In this work, we present Writing-RL: an Adaptive Curriculum Reinforcement Learning framework to advance long-form writing capabilities beyond SFT. The framework consists of three key components: Margin-aware Data Selection strategy that prioritizes samples with high learning potential, Pairwise Comparison Reward mechanism that provides discriminative learning signals in the absence of verifiable rewards, and Dynamic Reference Scheduling approach, which plays a particularly critical role by adaptively adjusting task difficulty based on evolving model performance. Experiments on 7B-scale writer models show that our RL framework largely improves long-form writing performance over strong SFT baselines. Furthermore, we observe that models trained with long-output RL generalize surprisingly well to long-input reasoning tasks, potentially offering a promising perspective for rethinking long-context training.
MUSEG: Reinforcing Video Temporal Understanding via Timestamp-Aware Multi-Segment Grounding
May 27, 2025Video temporal understanding is crucial for multimodal large language models (MLLMs) to reason over events in videos. Despite recent advances in general video understanding, current MLLMs still struggle with fine-grained temporal reasoning. While reinforcement learning (RL) has been explored to address this issue recently, existing RL approaches remain limited in effectiveness. In this work, we propose MUSEG, a novel RL-based method that enhances temporal understanding by introducing timestamp-aware multi-segment grounding. MUSEG enables MLLMs to align queries with multiple relevant video segments, promoting more comprehensive temporal reasoning. To facilitate effective learning, we design a customized RL training recipe with phased rewards that progressively guides the model toward temporally grounded reasoning. Extensive experiments on temporal grounding and time-sensitive video QA tasks demonstrate that MUSEG significantly outperforms existing methods and generalizes well across diverse temporal understanding scenarios. View our project at https://github.com/THUNLP-MT/MUSEG.
QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
May 23, 2025Recent large reasoning models (LRMs) have demonstrated strong reasoning capabilities through reinforcement learning (RL). These improvements have primarily been observed within the short-context reasoning tasks. In contrast, extending LRMs to effectively process and reason on long-context inputs via RL remains a critical unsolved challenge. To bridge this gap, we first formalize the paradigm of long-context reasoning RL, and identify key challenges in suboptimal training efficiency and unstable optimization process. To address these issues, we propose QwenLong-L1, a framework that adapts short-context LRMs to long-context scenarios via progressive context scaling. Specifically, we utilize a warm-up supervised fine-tuning (SFT) stage to establish a robust initial policy, followed by a curriculum-guided phased RL technique to stabilize the policy evolution, and enhanced with a difficulty-aware retrospective sampling strategy to incentivize the policy exploration. Experiments on seven long-context document question-answering benchmarks demonstrate that QwenLong-L1-32B outperforms flagship LRMs like OpenAI-o3-mini and Qwen3-235B-A22B, achieving performance on par with Claude-3.7-Sonnet-Thinking, demonstrating leading performance among state-of-the-art LRMs. This work advances the development of practical long-context LRMs capable of robust reasoning across information-intensive environments.
QwenLong-CPRS: Towards $\infty$-LLMs with Dynamic Context Optimization
May 23, 2025This technical report presents QwenLong-CPRS, a context compression framework designed for explicit long-context optimization, addressing prohibitive computation overhead during the prefill stage and the "lost in the middle" performance degradation of large language models (LLMs) during long sequence processing. Implemented through a novel dynamic context optimization mechanism, QwenLong-CPRS enables multi-granularity context compression guided by natural language instructions, achieving both efficiency gains and improved performance. Evolved from the Qwen architecture series, QwenLong-CPRS introduces four key innovations: (1) Natural language-guided dynamic optimization, (2) Bidirectional reasoning layers for enhanced boundary awareness, (3) Token critic mechanisms with language modeling heads, and (4) Window-parallel inference. Comprehensive evaluations across five benchmarks (4K-2M word contexts) demonstrate QwenLong-CPRS's threefold effectiveness: (1) Consistent superiority over other context management methods like RAG and sparse attention in both accuracy and efficiency. (2) Architecture-agnostic integration with all flagship LLMs, including GPT-4o, Gemini2.0-pro, Claude3.7-sonnet, DeepSeek-v3, and Qwen2.5-max, achieves 21.59$\times$ context compression alongside 19.15-point average performance gains; (3) Deployed with Qwen2.5-32B-Instruct, QwenLong-CPRS surpasses leading proprietary LLMs by 4.85 and 10.88 points on Ruler-128K and InfiniteBench, establishing new SOTA performance.
SoLoPO: Unlocking Long-Context Capabilities in LLMs via Short-to-Long Preference Optimization
May 16, 2025Despite advances in pretraining with extended context lengths, large language models (LLMs) still face challenges in effectively utilizing real-world long-context information, primarily due to insufficient long-context alignment caused by data quality issues, training inefficiencies, and the lack of well-designed optimization objectives. To address these limitations, we propose a framework named $\textbf{S}$h$\textbf{o}$rt-to-$\textbf{Lo}$ng $\textbf{P}$reference $\textbf{O}$ptimization ($\textbf{SoLoPO}$), decoupling long-context preference optimization (PO) into two components: short-context PO and short-to-long reward alignment (SoLo-RA), supported by both theoretical and empirical evidence. Specifically, short-context PO leverages preference pairs sampled from short contexts to enhance the model's contextual knowledge utilization ability. Meanwhile, SoLo-RA explicitly encourages reward score consistency utilization for the responses when conditioned on both short and long contexts that contain identical task-relevant information. This facilitates transferring the model's ability to handle short contexts into long-context scenarios. SoLoPO is compatible with mainstream preference optimization algorithms, while substantially improving the efficiency of data construction and training processes. Experimental results show that SoLoPO enhances all these algorithms with respect to stronger length and domain generalization abilities across various long-context benchmarks, while achieving notable improvements in both computational and memory efficiency.