 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMH-Bench: Benchmarking LLM Agents for Environment-Grounded Reasoning and Action in Smart Homes
Jun 01, 2026Smart homes are evolving toward complex state-dependent living environments, requiring Large Language Models (LLMs) to reason over user intent, preferences, and multi-device interactions. However, existing smart-home benchmarks often focus on static instruction-to-API mapping or limited simulations, failing to evaluate whether LLMs can reason, interact, and act reliably in realistic household scenarios. To address these limitations, we introduce SMH-Bench, a comprehensive benchmark for evaluating LLMs in smart-home environments. Built upon HomeEnv, an executable and verifiable smart-home simulator, SMH-Bench contains 1,100 high-quality tasks spanning 7 categories and 22 fine-grained subcategories. It further stratifies tasks across simple, medium and complex homes, ranging from small apartments to dense multi-room environments with 135 devices. Experiments show that although frontier LLMs achieve strong performance on explicit control and query tasks, they still exhibit significant weaknesses in automation task scheduling, ambiguity handling and personalized reasoning, especially as home complexity increases. We hope SMH-Bench will facilitate the development of more reliable, context-aware, and practically deployable smart-home agents.
HomeFlow: A Data Flywheel for Smart Home Agent Training with Verifiable Simulation
May 31, 2026Large language model agents are moving beyond text-only interaction toward physical-world control, with smart homes as a representative domain. Real domestic interaction requires understanding ambiguous intents, operating in dynamic environments, and performing multi-turn reasoning. However, existing methods struggle to generate high-quality training data for smart home agents. We propose HomeFlow, a verifiable data flywheel for this domain. HomeFlow uses HomeEnv as a unified simulation environment and HomeMaker to procedurally generate diverse home settings. Subsequently, Blueprint compiles open-ended user intents into executable state-based success conditions, while MCTS-Flow synthesizes diverse, verifiable multi-turn trajectories through environment-guided tree search. We then optimize the agents via supervised fine-tuning and step-wise RLVE, which facilitates iterative improvement through authentic physical feedback. We further construct SmartHome-Bench to evaluate the agent across various smart home tasks. On this benchmark, HomeFlow-RL-4B and HomeFlow-RL-8B achieve task success rates of 84.60% and 87.03%. It is worth noting that HomeFlow-RL-8B even surpasses the leading GPT-5.5 by 1.23 percentage points.
EvoCode-Bench: Evaluating Coding Agents in Multi-Turn Iterative Interactions
May 22, 2026Coding agents are increasingly used as iterative development partners, but most benchmarks still evaluate one specification followed by one final assessment. This leaves out a basic question: can an agent keep its own codebase working as requirements change? We introduce EvoCode-Bench, a benchmark of 26 stateful coding tasks and 227 evaluated rounds. Each task preserves the agent's workspace for 5-15 rounds, states requirements through observable behavior, and uses cumulative executable tests to check new requirements and still-active prior ones. We evaluate 13 coding agents with two metrics: MT@4, a four-attempt fail-stop multi-round score, and SR, a single-round score from a reference-completed prior state. For most agents, SR exceeds MT@4 by 22-40 points. The gap also changes rankings: the highest-SR agent (78.9) ranks only third in persistent execution (44.0 MT@4). Even the strongest agents achieve only about 50% success on multi-turn metrics, and aggregate pass rate drops below half of round-1 performance by round 5. Failure analysis shows tier-dependent behavior: weaker agents fail early, while stronger agents survive long enough to expose specification-tracking and regression failures. We release the benchmark data and Harbor multi-turn infrastructure.
Route Before Retrieve: Activating Latent Routing Abilities of LLMs for RAG vs. Long-Context Selection
May 11, 2026Recent advances in large language models (LLMs) have expanded the context window to beyond 128K tokens, enabling long-document understanding and multi-source reasoning. A key challenge, however, lies in choosing between retrieval-augmented generation (RAG) and long-context (LC) strategies: RAG is efficient but constrained by retrieval quality, while LC supports global reasoning at higher cost and with position sensitivity. Existing methods such as Self-Route adopt failure-driven fallback from RAG to LC, but remain passive, inefficient, and hard to interpret. We propose Pre-Route, a proactive routing framework that performs structured reasoning before answering. Using lightweight metadata (e.g., document type, length, initial snippet), Pre-Route enables task analysis, coverage estimation, and information-need prediction, producing explainable and cost-efficient routing decisions. Our study shows three key findings: (i) LLMs possess latent routing ability that can be reliably elicited with guidelines, allowing single-sample performance to approach that of multi-sample (Best-of-N) results; (ii) linear probes reveal that structured prompts sharpen the separability of the "optimal routing dimension" in representation space; and (iii) distillation transfers this reasoning structure to smaller models for lightweight deployment. Experiments on LaRA (in-domain) and LongBench-v2 (OOD) confirm that Pre-Route outperforms Always-RAG, Always-LC, and Self-Route baselines, achieving superior overall cost-effectiveness.
BabyVision: Visual Reasoning Beyond Language
Jan 10, 2026While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.
Nested Browser-Use Learning for Agentic Information Seeking
Dec 29, 2025Information-seeking (IS) agents have achieved strong performance across a range of wide and deep search tasks, yet their tool use remains largely restricted to API-level snippet retrieval and URL-based page fetching, limiting access to the richer information available through real browsing. While full browser interaction could unlock deeper capabilities, its fine-grained control and verbose page content returns introduce substantial complexity for ReAct-style function-calling agents. To bridge this gap, we propose Nested Browser-Use Learning (NestBrowse), which introduces a minimal and complete browser-action framework that decouples interaction control from page exploration through a nested structure. This design simplifies agentic reasoning while enabling effective deep-web information acquisition. Empirical results on challenging deep IS benchmarks demonstrate that NestBrowse offers clear benefits in practice. Further in-depth analyses underscore its efficiency and flexibility.
IterResearch: Rethinking Long-Horizon Agents via Markovian State Reconstruction
Nov 10, 2025Recent advances in deep-research agents have shown promise for autonomous knowledge construction through dynamic reasoning over external sources. However, existing approaches rely on a mono-contextual paradigm that accumulates all information in a single, expanding context window, leading to context suffocation and noise contamination that limit their effectiveness on long-horizon tasks. We introduce IterResearch, a novel iterative deep-research paradigm that reformulates long-horizon research as a Markov Decision Process with strategic workspace reconstruction. By maintaining an evolving report as memory and periodically synthesizing insights, our approach preserves consistent reasoning capacity across arbitrary exploration depths. We further develop Efficiency-Aware Policy Optimization (EAPO), a reinforcement learning framework that incentivizes efficient exploration through geometric reward discounting and enables stable distributed training via adaptive downsampling. Extensive experiments demonstrate that IterResearch achieves substantial improvements over existing open-source agents with average +14.5pp across six benchmarks and narrows the gap with frontier proprietary systems. Remarkably, our paradigm exhibits unprecedented interaction scaling, extending to 2048 interactions with dramatic performance gains (from 3.5\% to 42.5\%), and serves as an effective prompting strategy, improving frontier models by up to 19.2pp over ReAct on long-horizon tasks. These findings position IterResearch as a versatile solution for long-horizon reasoning, effective both as a trained agent and as a prompting paradigm for frontier models.
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
Sep 16, 2025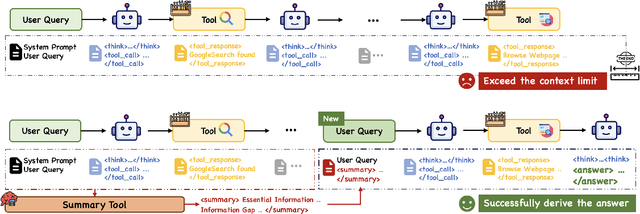
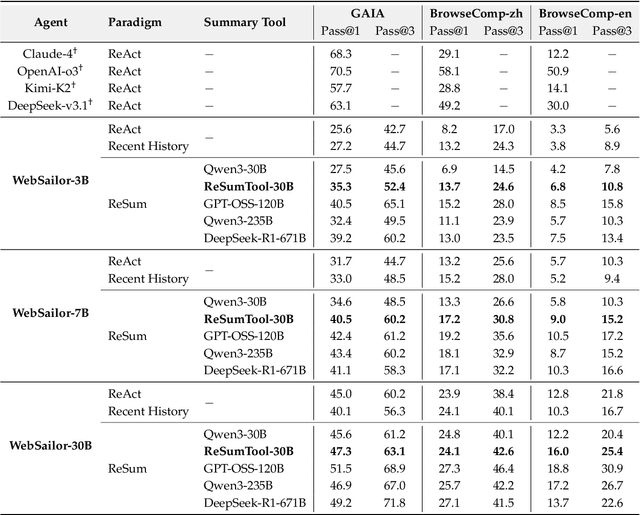
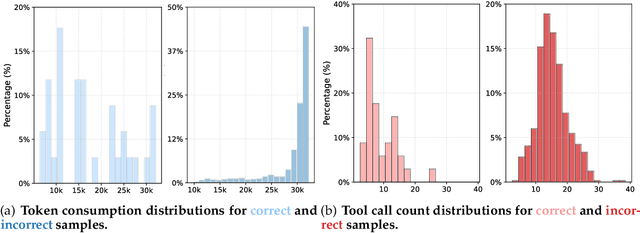
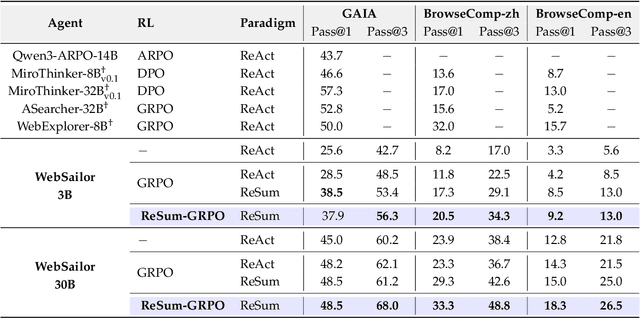
Large Language Model (LLM)-based web agents demonstrate strong performance on knowledge-intensive tasks but are hindered by context window limitations in paradigms like ReAct. Complex queries involving multiple entities, intertwined relationships, and high uncertainty demand extensive search cycles that rapidly exhaust context budgets before reaching complete solutions. To overcome this challenge, we introduce ReSum, a novel paradigm that enables indefinite exploration through periodic context summarization. ReSum converts growing interaction histories into compact reasoning states, maintaining awareness of prior discoveries while bypassing context constraints. For paradigm adaptation, we propose ReSum-GRPO, integrating GRPO with segmented trajectory training and advantage broadcasting to familiarize agents with summary-conditioned reasoning. Extensive experiments on web agents of varying scales across three benchmarks demonstrate that ReSum delivers an average absolute improvement of 4.5\% over ReAct, with further gains of up to 8.2\% following ReSum-GRPO training. Notably, with only 1K training samples, our WebResummer-30B (a ReSum-GRPO-trained version of WebSailor-30B) achieves 33.3\% Pass@1 on BrowseComp-zh and 18.3\% on BrowseComp-en, surpassing existing open-source web agents.
Scaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Sep 16, 2025



Recent advances in deep-research systems have demonstrated the potential for AI agents to autonomously discover and synthesize knowledge from external sources. In this paper, we introduce WebResearcher, a novel framework for building such agents through two key components: (1) WebResearcher, an iterative deep-research paradigm that reformulates deep research as a Markov Decision Process, where agents periodically consolidate findings into evolving reports while maintaining focused workspaces, overcoming the context suffocation and noise contamination that plague existing mono-contextual approaches; and (2) WebFrontier, a scalable data synthesis engine that generates high-quality training data through tool-augmented complexity escalation, enabling systematic creation of research tasks that bridge the gap between passive knowledge recall and active knowledge construction. Notably, we find that the training data from our paradigm significantly enhances tool-use capabilities even for traditional mono-contextual methods. Furthermore, our paradigm naturally scales through parallel thinking, enabling concurrent multi-agent exploration for more comprehensive conclusions. Extensive experiments across 6 challenging benchmarks demonstrate that WebResearcher achieves state-of-the-art performance, even surpassing frontier proprietary systems.