 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawBench: Can AI Agents Complete Everyday Online Tasks?
Apr 09, 2026AI agents may be able to automate your inbox, but can they automate other routine aspects of your life? Everyday online tasks offer a realistic yet unsolved testbed for evaluating the next generation of AI agents. To this end, we introduce ClawBench, an evaluation framework of 153 simple tasks that people need to accomplish regularly in their lives and work, spanning 144 live platforms across 15 categories, from completing purchases and booking appointments to submitting job applications. These tasks require demanding capabilities beyond existing benchmarks, such as obtaining relevant information from user-provided documents, navigating multi-step workflows across diverse platforms, and write-heavy operations like filling in many detailed forms correctly. Unlike existing benchmarks that evaluate agents in offline sandboxes with static pages, ClawBench operates on production websites, preserving the full complexity, dynamic nature, and challenges of real-world web interaction. A lightweight interception layer captures and blocks only the final submission request, ensuring safe evaluation without real-world side effects. Our evaluations of 7 frontier models show that both proprietary and open-source models can complete only a small portion of these tasks. For example, Claude Sonnet 4.6 achieves only 33.3%. Progress on ClawBench brings us closer to AI agents that can function as reliable general-purpose assistants.
Nested Browser-Use Learning for Agentic Information Seeking
Dec 29, 2025Information-seeking (IS) agents have achieved strong performance across a range of wide and deep search tasks, yet their tool use remains largely restricted to API-level snippet retrieval and URL-based page fetching, limiting access to the richer information available through real browsing. While full browser interaction could unlock deeper capabilities, its fine-grained control and verbose page content returns introduce substantial complexity for ReAct-style function-calling agents. To bridge this gap, we propose Nested Browser-Use Learning (NestBrowse), which introduces a minimal and complete browser-action framework that decouples interaction control from page exploration through a nested structure. This design simplifies agentic reasoning while enabling effective deep-web information acquisition. Empirical results on challenging deep IS benchmarks demonstrate that NestBrowse offers clear benefits in practice. Further in-depth analyses underscore its efficiency and flexibility.
IterResearch: Rethinking Long-Horizon Agents via Markovian State Reconstruction
Nov 10, 2025Recent advances in deep-research agents have shown promise for autonomous knowledge construction through dynamic reasoning over external sources. However, existing approaches rely on a mono-contextual paradigm that accumulates all information in a single, expanding context window, leading to context suffocation and noise contamination that limit their effectiveness on long-horizon tasks. We introduce IterResearch, a novel iterative deep-research paradigm that reformulates long-horizon research as a Markov Decision Process with strategic workspace reconstruction. By maintaining an evolving report as memory and periodically synthesizing insights, our approach preserves consistent reasoning capacity across arbitrary exploration depths. We further develop Efficiency-Aware Policy Optimization (EAPO), a reinforcement learning framework that incentivizes efficient exploration through geometric reward discounting and enables stable distributed training via adaptive downsampling. Extensive experiments demonstrate that IterResearch achieves substantial improvements over existing open-source agents with average +14.5pp across six benchmarks and narrows the gap with frontier proprietary systems. Remarkably, our paradigm exhibits unprecedented interaction scaling, extending to 2048 interactions with dramatic performance gains (from 3.5\% to 42.5\%), and serves as an effective prompting strategy, improving frontier models by up to 19.2pp over ReAct on long-horizon tasks. These findings position IterResearch as a versatile solution for long-horizon reasoning, effective both as a trained agent and as a prompting paradigm for frontier models.
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
Sep 16, 2025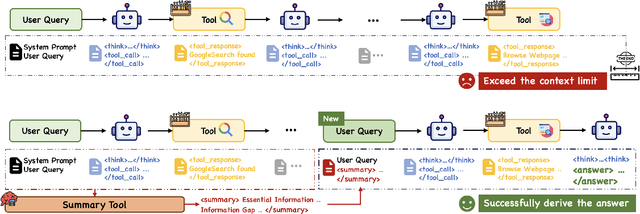
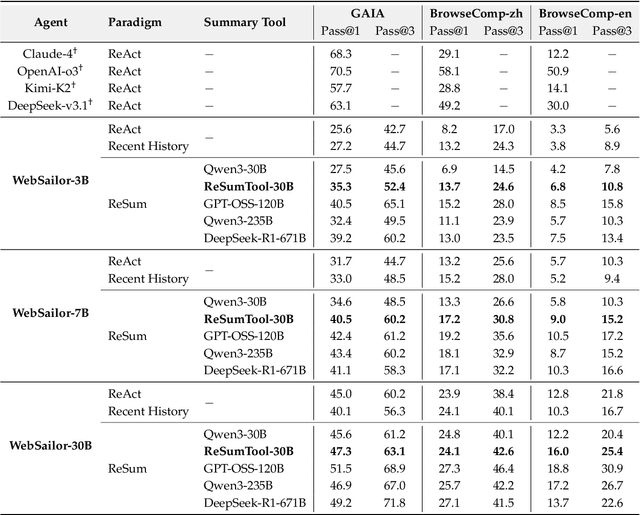
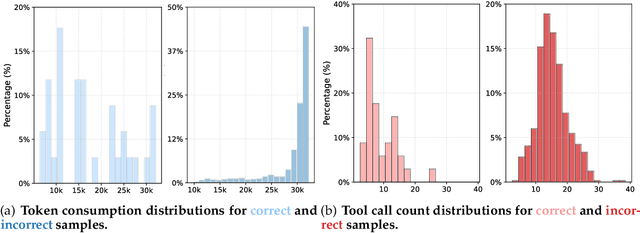
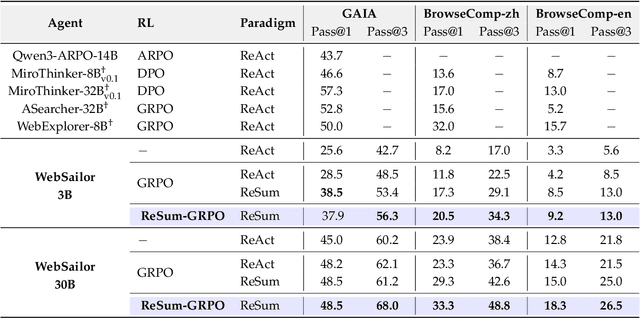
Large Language Model (LLM)-based web agents demonstrate strong performance on knowledge-intensive tasks but are hindered by context window limitations in paradigms like ReAct. Complex queries involving multiple entities, intertwined relationships, and high uncertainty demand extensive search cycles that rapidly exhaust context budgets before reaching complete solutions. To overcome this challenge, we introduce ReSum, a novel paradigm that enables indefinite exploration through periodic context summarization. ReSum converts growing interaction histories into compact reasoning states, maintaining awareness of prior discoveries while bypassing context constraints. For paradigm adaptation, we propose ReSum-GRPO, integrating GRPO with segmented trajectory training and advantage broadcasting to familiarize agents with summary-conditioned reasoning. Extensive experiments on web agents of varying scales across three benchmarks demonstrate that ReSum delivers an average absolute improvement of 4.5\% over ReAct, with further gains of up to 8.2\% following ReSum-GRPO training. Notably, with only 1K training samples, our WebResummer-30B (a ReSum-GRPO-trained version of WebSailor-30B) achieves 33.3\% Pass@1 on BrowseComp-zh and 18.3\% on BrowseComp-en, surpassing existing open-source web agents.
WebSailor-V2: Bridging the Chasm to Proprietary Agents via Synthetic Data and Scalable Reinforcement Learning
Sep 16, 2025



Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all open-source agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Sep 16, 2025



Recent advances in deep-research systems have demonstrated the potential for AI agents to autonomously discover and synthesize knowledge from external sources. In this paper, we introduce WebResearcher, a novel framework for building such agents through two key components: (1) WebResearcher, an iterative deep-research paradigm that reformulates deep research as a Markov Decision Process, where agents periodically consolidate findings into evolving reports while maintaining focused workspaces, overcoming the context suffocation and noise contamination that plague existing mono-contextual approaches; and (2) WebFrontier, a scalable data synthesis engine that generates high-quality training data through tool-augmented complexity escalation, enabling systematic creation of research tasks that bridge the gap between passive knowledge recall and active knowledge construction. Notably, we find that the training data from our paradigm significantly enhances tool-use capabilities even for traditional mono-contextual methods. Furthermore, our paradigm naturally scales through parallel thinking, enabling concurrent multi-agent exploration for more comprehensive conclusions. Extensive experiments across 6 challenging benchmarks demonstrate that WebResearcher achieves state-of-the-art performance, even surpassing frontier proprietary systems.
Scaling Agents via Continual Pre-training
Sep 16, 2025Large language models (LLMs) have evolved into agentic systems capable of autonomous tool use and multi-step reasoning for complex problem-solving. However, post-training approaches building upon general-purpose foundation models consistently underperform in agentic tasks, particularly in open-source implementations. We identify the root cause: the absence of robust agentic foundation models forces models during post-training to simultaneously learn diverse agentic behaviors while aligning them to expert demonstrations, thereby creating fundamental optimization tensions. To this end, we are the first to propose incorporating Agentic Continual Pre-training (Agentic CPT) into the deep research agents training pipeline to build powerful agentic foundational models. Based on this approach, we develop a deep research agent model named AgentFounder. We evaluate our AgentFounder-30B on 10 benchmarks and achieve state-of-the-art performance while retains strong tool-use ability, notably 39.9% on BrowseComp-en, 43.3% on BrowseComp-zh, and 31.5% Pass@1 on HLE.
WebSailor: Navigating Super-human Reasoning for Web Agent
Jul 03, 2025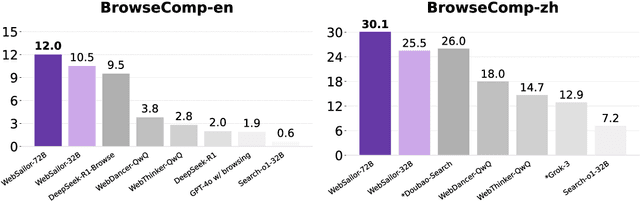
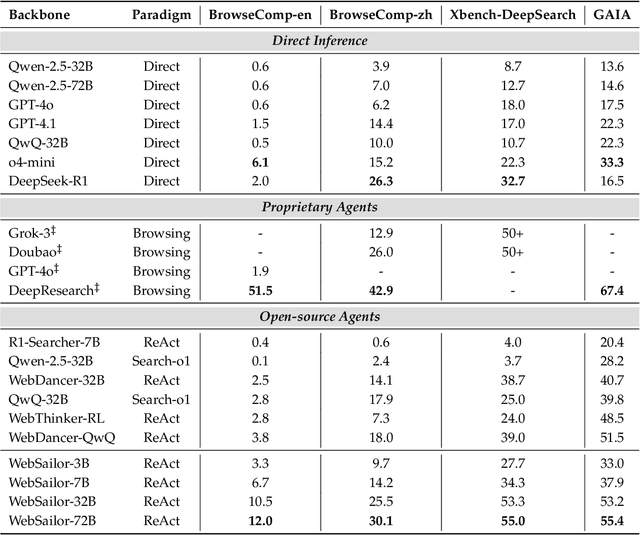
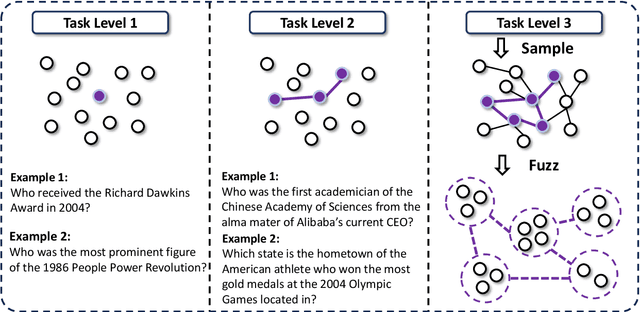

Transcending human cognitive limitations represents a critical frontier in LLM training. Proprietary agentic systems like DeepResearch have demonstrated superhuman capabilities on extremely complex information-seeking benchmarks such as BrowseComp, a feat previously unattainable. We posit that their success hinges on a sophisticated reasoning pattern absent in open-source models: the ability to systematically reduce extreme uncertainty when navigating vast information landscapes. Based on this insight, we introduce WebSailor, a complete post-training methodology designed to instill this crucial capability. Our approach involves generating novel, high-uncertainty tasks through structured sampling and information obfuscation, RFT cold start, and an efficient agentic RL training algorithm, Duplicating Sampling Policy Optimization (DUPO). With this integrated pipeline, WebSailor significantly outperforms all opensource agents in complex information-seeking tasks, matching proprietary agents' performance and closing the capability gap.
The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks
Apr 22, 2025



As large language models (LLMs) continue to advance in linguistic capabilities, robust multilingual evaluation has become essential for promoting equitable technological progress. This position paper examines over 2,000 multilingual (non-English) benchmarks from 148 countries, published between 2021 and 2024, to evaluate past, present, and future practices in multilingual benchmarking. Our findings reveal that, despite significant investments amounting to tens of millions of dollars, English remains significantly overrepresented in these benchmarks. Additionally, most benchmarks rely on original language content rather than translations, with the majority sourced from high-resource countries such as China, India, Germany, the UK, and the USA. Furthermore, a comparison of benchmark performance with human judgments highlights notable disparities. STEM-related tasks exhibit strong correlations with human evaluations (0.70 to 0.85), while traditional NLP tasks like question answering (e.g., XQuAD) show much weaker correlations (0.11 to 0.30). Moreover, translating English benchmarks into other languages proves insufficient, as localized benchmarks demonstrate significantly higher alignment with local human judgments (0.68) than their translated counterparts (0.47). This underscores the importance of creating culturally and linguistically tailored benchmarks rather than relying solely on translations. Through this comprehensive analysis, we highlight six key limitations in current multilingual evaluation practices, propose the guiding principles accordingly for effective multilingual benchmarking, and outline five critical research directions to drive progress in the field. Finally, we call for a global collaborative effort to develop human-aligned benchmarks that prioritize real-world applications.
Towards Widening The Distillation Bottleneck for Reasoning Models
Mar 03, 2025Large Reasoning Models(LRMs) such as OpenAI o1 and DeepSeek-R1 have shown remarkable reasoning capabilities by scaling test-time compute and generating long Chain-of-Thought(CoT). Distillation--post-training on LRMs-generated data--is a straightforward yet effective method to enhance the reasoning abilities of smaller models, but faces a critical bottleneck: we found that distilled long CoT data poses learning difficulty for small models and leads to the inheritance of biases (i.e. over-thinking) when using Supervised Fine-tuning(SFT) and Reinforcement Learning(RL) methods. To alleviate this bottleneck, we propose constructing tree-based CoT data from scratch via Monte Carlo Tree Search(MCTS). We then exploit a set of CoT-aware approaches, including Thoughts Length Balance, Fine-grained DPO, and Joint Post-training Objective, to enhance SFT and RL on the construted data.