 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-VLN: A Self-Evolving Vision-Language Navigation Framework Based on Multimodal Large Language Models
Jul 17, 2025Recent advances in vision-language navigation (VLN) were mainly attributed to emerging large language models (LLMs). These methods exhibited excellent generalization capabilities in instruction understanding and task reasoning. However, they were constrained by the fixed knowledge bases and reasoning abilities of LLMs, preventing fully incorporating experiential knowledge and thus resulting in a lack of efficient evolutionary capacity. To address this, we drew inspiration from the evolution capabilities of natural agents, and proposed a self-evolving VLN framework (SE-VLN) to endow VLN agents with the ability to continuously evolve during testing. To the best of our knowledge, it was the first time that an multimodal LLM-powered self-evolving VLN framework was proposed. Specifically, SE-VLN comprised three core modules, i.e., a hierarchical memory module to transfer successful and failure cases into reusable knowledge, a retrieval-augmented thought-based reasoning module to retrieve experience and enable multi-step decision-making, and a reflection module to realize continual evolution. Comprehensive tests illustrated that the SE-VLN achieved navigation success rates of 57% and 35.2% in unseen environments, representing absolute performance improvements of 23.9% and 15.0% over current state-of-the-art methods on R2R and REVERSE datasets, respectively. Moreover, the SE-VLN showed performance improvement with increasing experience repository, elucidating its great potential as a self-evolving agent framework for VLN.
Multi-View Incremental Learning with Structured Hebbian Plasticity for Enhanced Fusion Efficiency
Dec 17, 2024

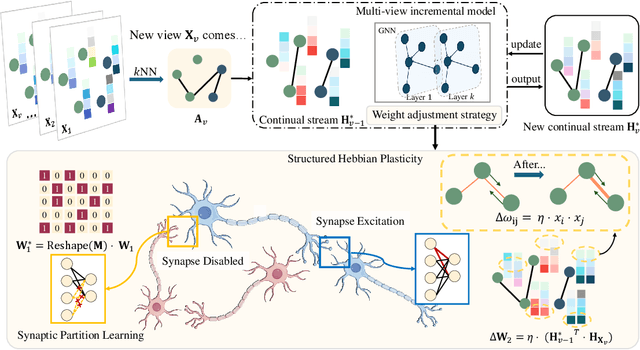

The rapid evolution of multimedia technology has revolutionized human perception, paving the way for multi-view learning. However, traditional multi-view learning approaches are tailored for scenarios with fixed data views, falling short of emulating the intricate cognitive procedures of the human brain processing signals sequentially. Our cerebral architecture seamlessly integrates sequential data through intricate feed-forward and feedback mechanisms. In stark contrast, traditional methods struggle to generalize effectively when confronted with data spanning diverse domains, highlighting the need for innovative strategies that can mimic the brain's adaptability and dynamic integration capabilities. In this paper, we propose a bio-neurologically inspired multi-view incremental framework named MVIL aimed at emulating the brain's fine-grained fusion of sequentially arriving views. MVIL lies two fundamental modules: structured Hebbian plasticity and synaptic partition learning. The structured Hebbian plasticity reshapes the structure of weights to express the high correlation between view representations, facilitating a fine-grained fusion of view representations. Moreover, synaptic partition learning is efficient in alleviating drastic changes in weights and also retaining old knowledge by inhibiting partial synapses. These modules bionically play a central role in reinforcing crucial associations between newly acquired information and existing knowledge repositories, thereby enhancing the network's capacity for generalization. Experimental results on six benchmark datasets show MVIL's effectiveness over state-of-the-art methods.
Multimodal Sentiment Analysis Based on Causal Reasoning
Dec 10, 2024



With the rapid development of multimedia, the shift from unimodal textual sentiment analysis to multimodal image-text sentiment analysis has obtained academic and industrial attention in recent years. However, multimodal sentiment analysis is affected by unimodal data bias, e.g., text sentiment is misleading due to explicit sentiment semantic, leading to low accuracy in the final sentiment classification. In this paper, we propose a novel CounterFactual Multimodal Sentiment Analysis framework (CF-MSA) using causal counterfactual inference to construct multimodal sentiment causal inference. CF-MSA mitigates the direct effect from unimodal bias and ensures heterogeneity across modalities by differentiating the treatment variables between modalities. In addition, considering the information complementarity and bias differences between modalities, we propose a new optimisation objective to effectively integrate different modalities and reduce the inherent bias from each modality. Experimental results on two public datasets, MVSA-Single and MVSA-Multiple, demonstrate that the proposed CF-MSA has superior debiasing capability and achieves new state-of-the-art performances. We will release the code and datasets to facilitate future research.
Towards End-to-End Explainable Facial Action Unit Recognition via Vision-Language Joint Learning
Aug 01, 2024



Facial action units (AUs), as defined in the Facial Action Coding System (FACS), have received significant research interest owing to their diverse range of applications in facial state analysis. Current mainstream FAU recognition models have a notable limitation, i.e., focusing only on the accuracy of AU recognition and overlooking explanations of corresponding AU states. In this paper, we propose an end-to-end Vision-Language joint learning network for explainable FAU recognition (termed VL-FAU), which aims to reinforce AU representation capability and language interpretability through the integration of joint multimodal tasks. Specifically, VL-FAU brings together language models to generate fine-grained local muscle descriptions and distinguishable global face description when optimising FAU recognition. Through this, the global facial representation and its local AU representations will achieve higher distinguishability among different AUs and different subjects. In addition, multi-level AU representation learning is utilised to improve AU individual attention-aware representation capabilities based on multi-scale combined facial stem feature. Extensive experiments on DISFA and BP4D AU datasets show that the proposed approach achieves superior performance over the state-of-the-art methods on most of the metrics. In addition, compared with mainstream FAU recognition methods, VL-FAU can provide local- and global-level interpretability language descriptions with the AUs' predictions.
* 10 pages, 5 figures, 4 tables
3SHNet: Boosting Image-Sentence Retrieval via Visual Semantic-Spatial Self-Highlighting
Apr 26, 2024



In this paper, we propose a novel visual Semantic-Spatial Self-Highlighting Network (termed 3SHNet) for high-precision, high-efficiency and high-generalization image-sentence retrieval. 3SHNet highlights the salient identification of prominent objects and their spatial locations within the visual modality, thus allowing the integration of visual semantics-spatial interactions and maintaining independence between two modalities. This integration effectively combines object regions with the corresponding semantic and position layouts derived from segmentation to enhance the visual representation. And the modality-independence guarantees efficiency and generalization. Additionally, 3SHNet utilizes the structured contextual visual scene information from segmentation to conduct the local (region-based) or global (grid-based) guidance and achieve accurate hybrid-level retrieval. Extensive experiments conducted on MS-COCO and Flickr30K benchmarks substantiate the superior performances, inference efficiency and generalization of the proposed 3SHNet when juxtaposed with contemporary state-of-the-art methodologies. Specifically, on the larger MS-COCO 5K test set, we achieve 16.3%, 24.8%, and 18.3% improvements in terms of rSum score, respectively, compared with the state-of-the-art methods using different image representations, while maintaining optimal retrieval efficiency. Moreover, our performance on cross-dataset generalization improves by 18.6%. Data and code are available at https://github.com/XuriGe1995/3SHNet.
* Accepted Information Processing and Management (IP&M), 10 pages, 9 figures and 8 tables
Cross-modal Semantic Enhanced Interaction for Image-Sentence Retrieval
Oct 17, 2022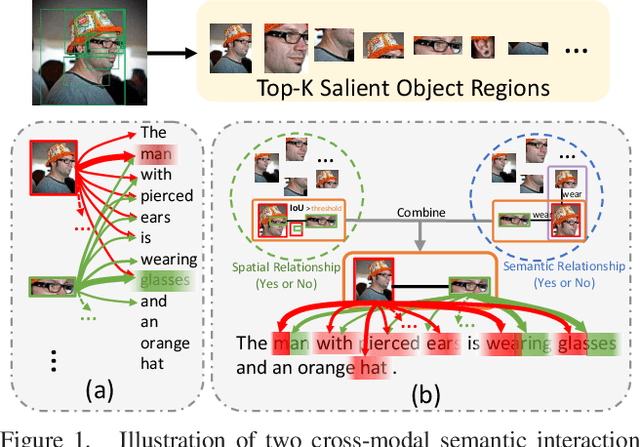
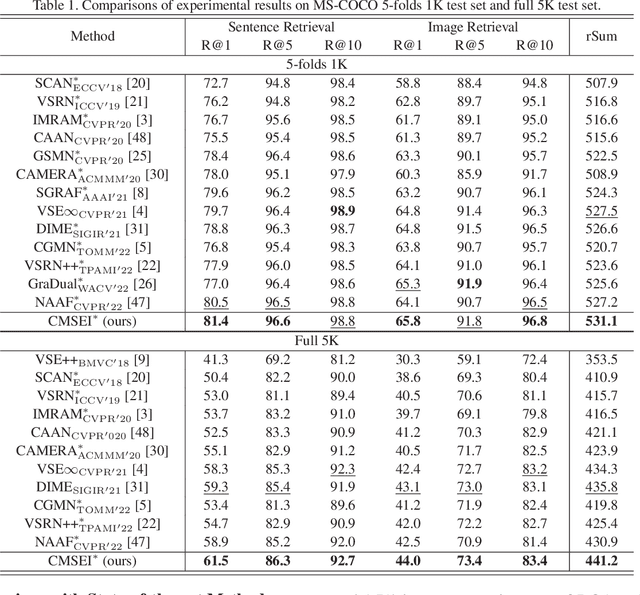
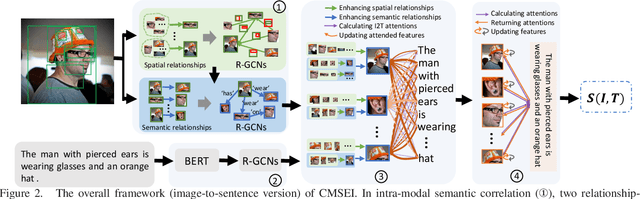
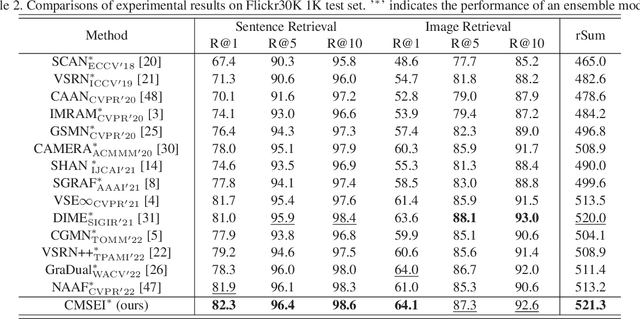
Image-sentence retrieval has attracted extensive research attention in multimedia and computer vision due to its promising application. The key issue lies in jointly learning the visual and textual representation to accurately estimate their similarity. To this end, the mainstream schema adopts an object-word based attention to calculate their relevance scores and refine their interactive representations with the attention features, which, however, neglects the context of the object representation on the inter-object relationship that matches the predicates in sentences. In this paper, we propose a Cross-modal Semantic Enhanced Interaction method, termed CMSEI for image-sentence retrieval, which correlates the intra- and inter-modal semantics between objects and words. In particular, we first design the intra-modal spatial and semantic graphs based reasoning to enhance the semantic representations of objects guided by the explicit relationships of the objects' spatial positions and their scene graph. Then the visual and textual semantic representations are refined jointly via the inter-modal interactive attention and the cross-modal alignment. To correlate the context of objects with the textual context, we further refine the visual semantic representation via the cross-level object-sentence and word-image based interactive attention. Experimental results on seven standard evaluation metrics show that the proposed CMSEI outperforms the state-of-the-art and the alternative approaches on MS-COCO and Flickr30K benchmarks.
Global2Local: A Joint-Hierarchical Attention for Video Captioning
Mar 13, 2022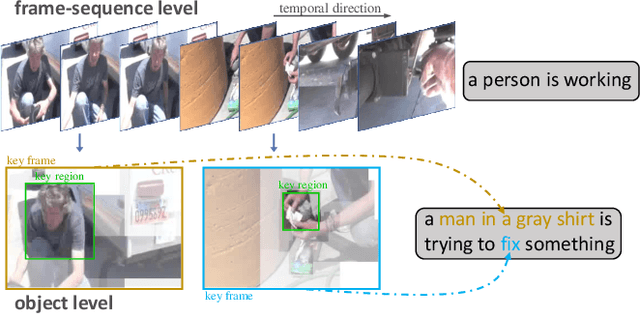
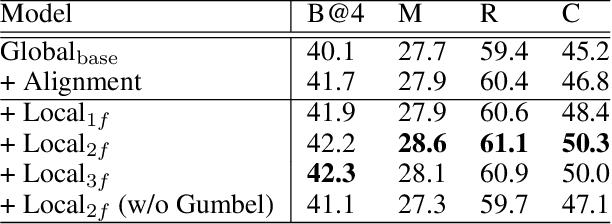
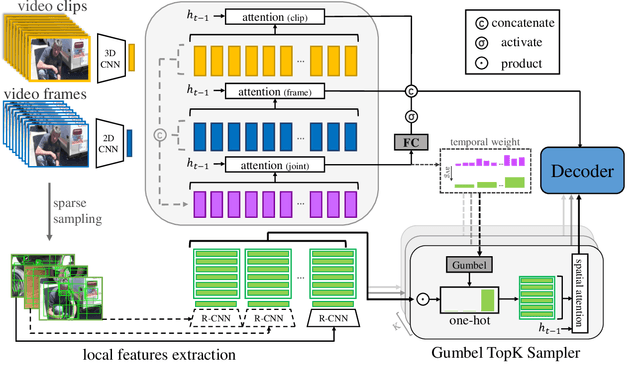
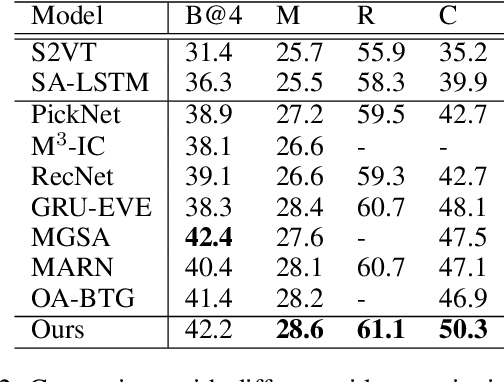
Recently, automatic video captioning has attracted increasing attention, where the core challenge lies in capturing the key semantic items, like objects and actions as well as their spatial-temporal correlations from the redundant frames and semantic content. To this end, existing works select either the key video clips in a global level~(across multi frames), or key regions within each frame, which, however, neglect the hierarchical order, i.e., key frames first and key regions latter. In this paper, we propose a novel joint-hierarchical attention model for video captioning, which embeds the key clips, the key frames and the key regions jointly into the captioning model in a hierarchical manner. Such a joint-hierarchical attention model first conducts a global selection to identify key frames, followed by a Gumbel sampling operation to identify further key regions based on the key frames, achieving an accurate global-to-local feature representation to guide the captioning. Extensive quantitative evaluations on two public benchmark datasets MSVD and MSR-VTT demonstrates the superiority of the proposed method over the state-of-the-art methods.
Factored Attention and Embedding for Unstructured-view Topic-related Ultrasound Report Generation
Mar 12, 2022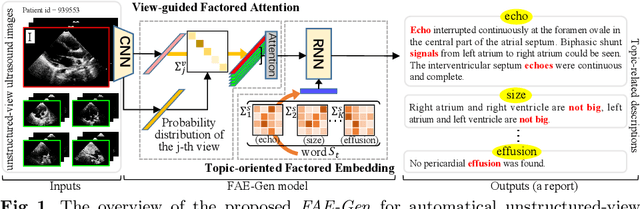
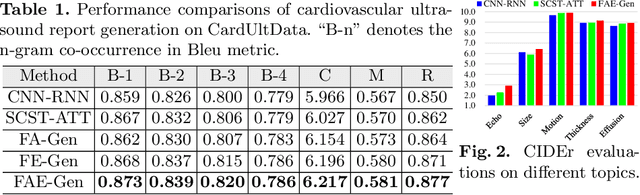

Echocardiography is widely used to clinical practice for diagnosis and treatment, e.g., on the common congenital heart defects. The traditional manual manipulation is error-prone due to the staff shortage, excess workload, and less experience, leading to the urgent requirement of an automated computer-aided reporting system to lighten the workload of ultrasonologists considerably and assist them in decision making. Despite some recent successful attempts in automatical medical report generation, they are trapped in the ultrasound report generation, which involves unstructured-view images and topic-related descriptions. To this end, we investigate the task of the unstructured-view topic-related ultrasound report generation, and propose a novel factored attention and embedding model (termed FAE-Gen). The proposed FAE-Gen mainly consists of two modules, i.e., view-guided factored attention and topic-oriented factored embedding, which 1) capture the homogeneous and heterogeneous morphological characteristic across different views, and 2) generate the descriptions with different syntactic patterns and different emphatic contents for different topics. Experimental evaluations are conducted on a to-be-released large-scale clinical cardiovascular ultrasound dataset (CardUltData). Both quantitative comparisons and qualitative analysis demonstrate the effectiveness and the superiority of FAE-Gen over seven commonly-used metrics.
Differentiated Relevances Embedding for Group-based Referring Expression Comprehension
Mar 12, 2022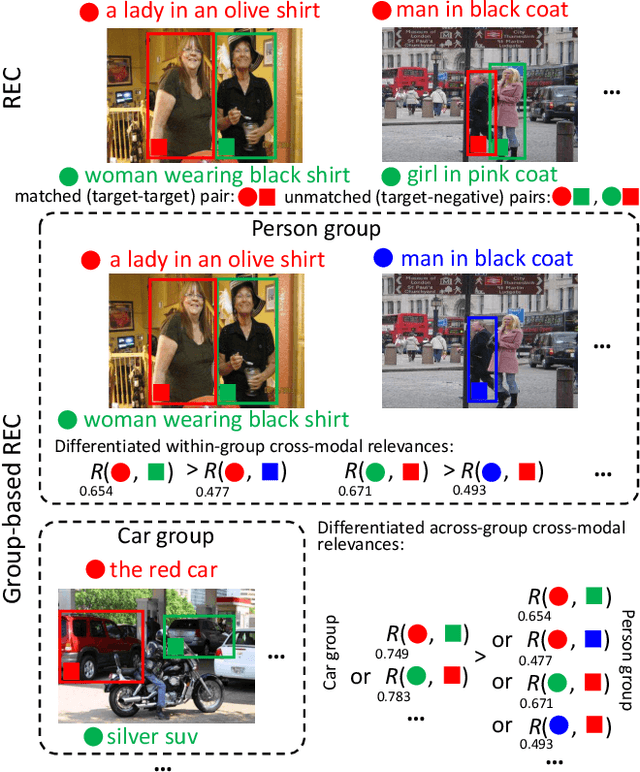
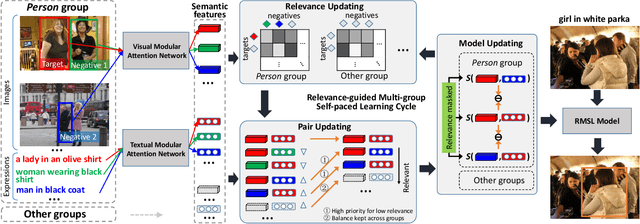

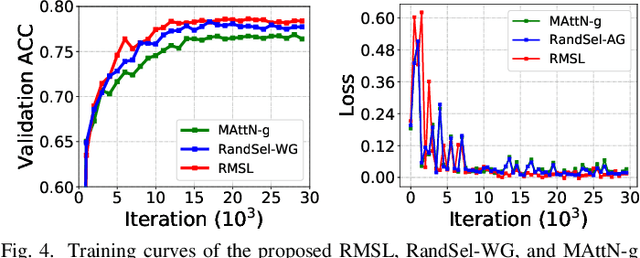
Referring expression comprehension (REC) aims to locate a certain object in an image referred by a natural language expression. For joint understanding of regions and expressions, existing REC works typically target on modeling the cross-modal relevance in each region-expression pair within each single image. In this paper, we explore a new but general REC-related problem, named Group-based REC, where the regions and expressions can come from different subject-related images (images in the same group), e.g., sets of photo albums or video frames. Different from REC, Group-based REC involves differentiated cross-modal relevances within each group and across different groups, which, however, are neglected in the existing one-line paradigm. To this end, we propose a novel relevance-guided multi-group self-paced learning schema (termed RMSL), where the within-group region-expression pairs are adaptively assigned with different priorities according to their cross-modal relevances, and the bias of the group priority is balanced via an across-group relevance constraint simultaneously. In particular, based on the visual and textual semantic features, RMSL conducts an adaptive learning cycle upon triplet ranking, where (1) the target-negative region-expression pairs with low within-group relevances are used preferentially in model training to distinguish the primary semantics of the target objects, and (2) an across-group relevance regularization is integrated into model training to balance the bias of group priority. The relevances, the pairs, and the model parameters are alternatively updated upon a unified self-paced hinge loss.
Weakly-Supervised Dense Action Anticipation
Nov 15, 2021

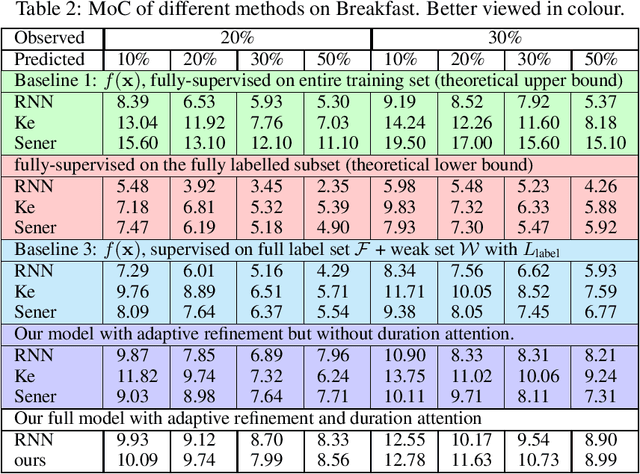
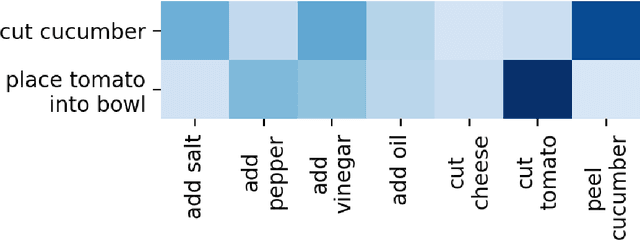
Dense anticipation aims to forecast future actions and their durations for long horizons. Existing approaches rely on fully-labelled data, i.e. sequences labelled with all future actions and their durations. We present a (semi-) weakly supervised method using only a small number of fully-labelled sequences and predominantly sequences in which only the (one) upcoming action is labelled. To this end, we propose a framework that generates pseudo-labels for future actions and their durations and adaptively refines them through a refinement module. Given only the upcoming action label as input, these pseudo-labels guide action/duration prediction for the future. We further design an attention mechanism to predict context-aware durations. Experiments on the Breakfast and 50Salads benchmarks verify our method's effectiveness; we are competitive even when compared to fully supervised state-of-the-art models. We will make our code available at: https://github.com/zhanghaotong1/WSLVideoDenseAnticipation.