 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal2Local: A Joint-Hierarchical Attention for Video Captioning
Mar 13, 2022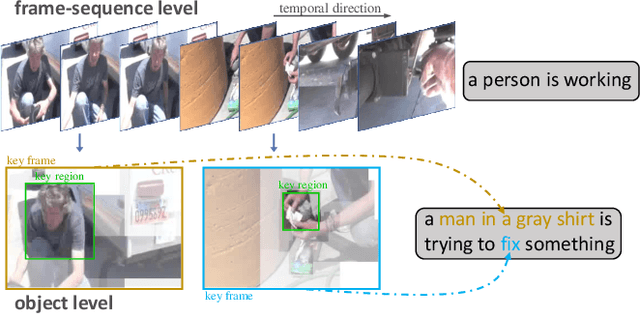
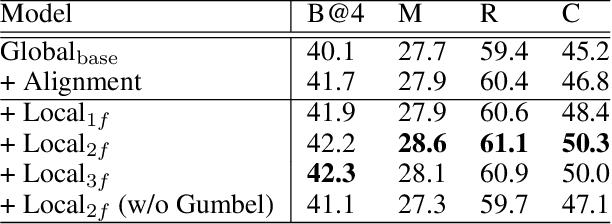
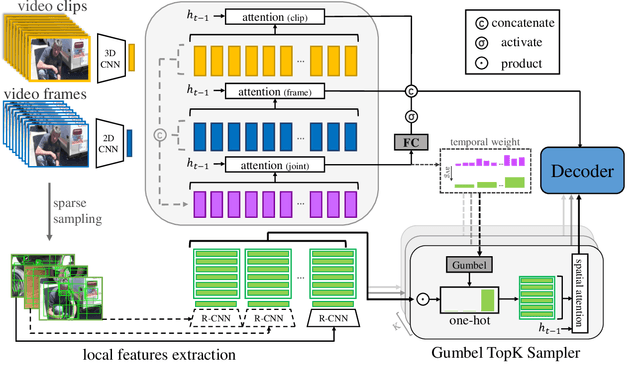
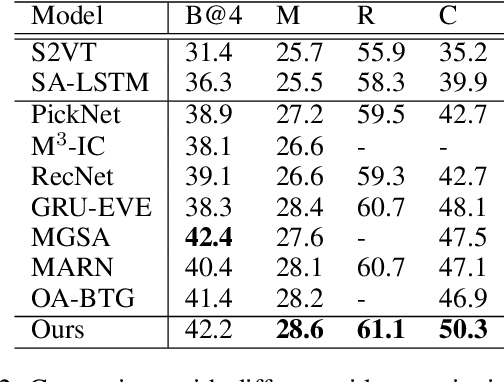
Recently, automatic video captioning has attracted increasing attention, where the core challenge lies in capturing the key semantic items, like objects and actions as well as their spatial-temporal correlations from the redundant frames and semantic content. To this end, existing works select either the key video clips in a global level~(across multi frames), or key regions within each frame, which, however, neglect the hierarchical order, i.e., key frames first and key regions latter. In this paper, we propose a novel joint-hierarchical attention model for video captioning, which embeds the key clips, the key frames and the key regions jointly into the captioning model in a hierarchical manner. Such a joint-hierarchical attention model first conducts a global selection to identify key frames, followed by a Gumbel sampling operation to identify further key regions based on the key frames, achieving an accurate global-to-local feature representation to guide the captioning. Extensive quantitative evaluations on two public benchmark datasets MSVD and MSR-VTT demonstrates the superiority of the proposed method over the state-of-the-art methods.
Factored Attention and Embedding for Unstructured-view Topic-related Ultrasound Report Generation
Mar 12, 2022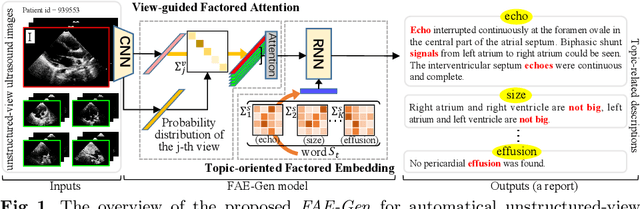
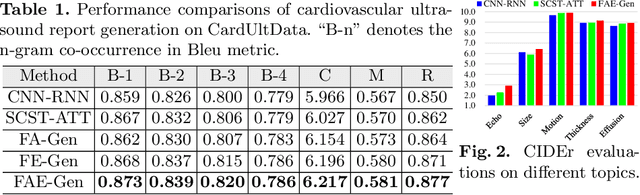

Echocardiography is widely used to clinical practice for diagnosis and treatment, e.g., on the common congenital heart defects. The traditional manual manipulation is error-prone due to the staff shortage, excess workload, and less experience, leading to the urgent requirement of an automated computer-aided reporting system to lighten the workload of ultrasonologists considerably and assist them in decision making. Despite some recent successful attempts in automatical medical report generation, they are trapped in the ultrasound report generation, which involves unstructured-view images and topic-related descriptions. To this end, we investigate the task of the unstructured-view topic-related ultrasound report generation, and propose a novel factored attention and embedding model (termed FAE-Gen). The proposed FAE-Gen mainly consists of two modules, i.e., view-guided factored attention and topic-oriented factored embedding, which 1) capture the homogeneous and heterogeneous morphological characteristic across different views, and 2) generate the descriptions with different syntactic patterns and different emphatic contents for different topics. Experimental evaluations are conducted on a to-be-released large-scale clinical cardiovascular ultrasound dataset (CardUltData). Both quantitative comparisons and qualitative analysis demonstrate the effectiveness and the superiority of FAE-Gen over seven commonly-used metrics.
Semantic-aware Image Deblurring
Oct 09, 2019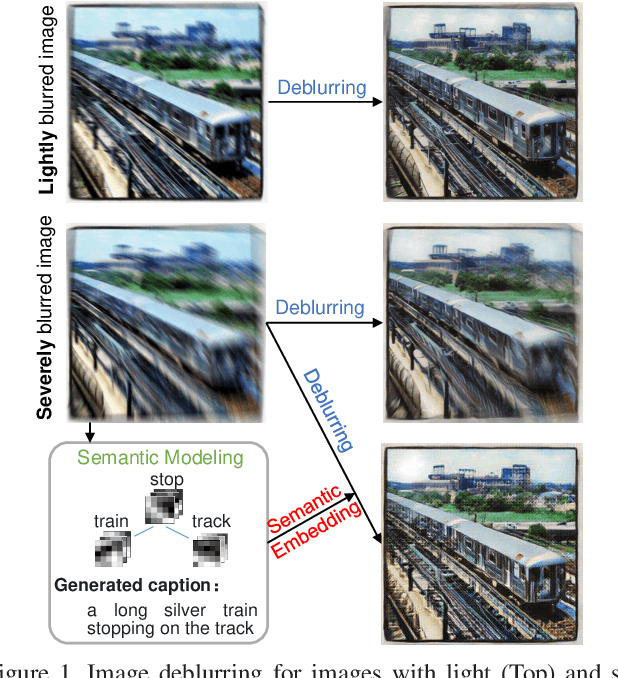

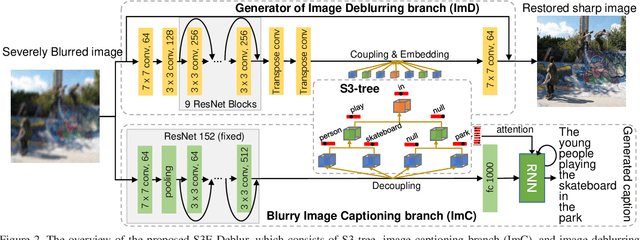

Image deblurring has achieved exciting progress in recent years. However, traditional methods fail to deblur severely blurred images, where semantic contents appears ambiguously. In this paper, we conduct image deblurring guided by the semantic contents inferred from image captioning. Specially, we propose a novel Structured-Spatial Semantic Embedding model for image deblurring (termed S3E-Deblur), which introduces a novel Structured-Spatial Semantic tree model (S3-tree) to bridge two basic tasks in computer vision: image deblurring (ImD) and image captioning (ImC). In particular, S3-tree captures and represents the semantic contents in structured spatial features in ImC, and then embeds the spatial features of the tree nodes into GAN based ImD. Co-training on S3-tree, ImC, and ImD is conducted to optimize the overall model in a multi-task end-to-end manner. Extensive experiments on severely blurred MSCOCO and GoPro datasets demonstrate the significant superiority of S3E-Deblur compared to the state-of-the-arts on both ImD and ImC tasks.