 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2ML: Spatio-Spectral Mutual Learning for Depth Completion
Nov 08, 2025The raw depth images captured by RGB-D cameras using Time-of-Flight (TOF) or structured light often suffer from incomplete depth values due to weak reflections, boundary shadows, and artifacts, which limit their applications in downstream vision tasks. Existing methods address this problem through depth completion in the image domain, but they overlook the physical characteristics of raw depth images. It has been observed that the presence of invalid depth areas alters the frequency distribution pattern. In this work, we propose a Spatio-Spectral Mutual Learning framework (S2ML) to harmonize the advantages of both spatial and frequency domains for depth completion. Specifically, we consider the distinct properties of amplitude and phase spectra and devise a dedicated spectral fusion module. Meanwhile, the local and global correlations between spatial-domain and frequency-domain features are calculated in a unified embedding space. The gradual mutual representation and refinement encourage the network to fully explore complementary physical characteristics and priors for more accurate depth completion. Extensive experiments demonstrate the effectiveness of our proposed S2ML method, outperforming the state-of-the-art method CFormer by 0.828 dB and 0.834 dB on the NYU-Depth V2 and SUN RGB-D datasets, respectively.
FADPNet: Frequency-Aware Dual-Path Network for Face Super-Resolution
Jun 17, 2025Face super-resolution (FSR) under limited computational costs remains an open problem. Existing approaches typically treat all facial pixels equally, resulting in suboptimal allocation of computational resources and degraded FSR performance. CNN is relatively sensitive to high-frequency facial features, such as component contours and facial outlines. Meanwhile, Mamba excels at capturing low-frequency features like facial color and fine-grained texture, and does so with lower complexity than Transformers. Motivated by these observations, we propose FADPNet, a Frequency-Aware Dual-Path Network that decomposes facial features into low- and high-frequency components and processes them via dedicated branches. For low-frequency regions, we introduce a Mamba-based Low-Frequency Enhancement Block (LFEB), which combines state-space attention with squeeze-and-excitation operations to extract low-frequency global interactions and emphasize informative channels. For high-frequency regions, we design a CNN-based Deep Position-Aware Attention (DPA) module to enhance spatially-dependent structural details, complemented by a lightweight High-Frequency Refinement (HFR) module that further refines frequency-specific representations. Through the above designs, our method achieves an excellent balance between FSR quality and model efficiency, outperforming existing approaches.
Beyond the Horizon: Decoupling UAVs Multi-View Action Recognition via Partial Order Transfer
Apr 29, 2025Action recognition in unmanned aerial vehicles (UAVs) poses unique challenges due to significant view variations along the vertical spatial axis. Unlike traditional ground-based settings, UAVs capture actions from a wide range of altitudes, resulting in considerable appearance discrepancies. We introduce a multi-view formulation tailored to varying UAV altitudes and empirically observe a partial order among views, where recognition accuracy consistently decreases as the altitude increases. This motivates a novel approach that explicitly models the hierarchical structure of UAV views to improve recognition performance across altitudes. To this end, we propose the Partial Order Guided Multi-View Network (POG-MVNet), designed to address drastic view variations by effectively leveraging view-dependent information across different altitude levels. The framework comprises three key components: a View Partition (VP) module, which uses the head-to-body ratio to group views by altitude; an Order-aware Feature Decoupling (OFD) module, which disentangles action-relevant and view-specific features under partial order guidance; and an Action Partial Order Guide (APOG), which leverages the partial order to transfer informative knowledge from easier views to support learning in more challenging ones. We conduct experiments on Drone-Action, MOD20, and UAV datasets, demonstrating that POG-MVNet significantly outperforms competing methods. For example, POG-MVNet achieves a 4.7% improvement on Drone-Action dataset and a 3.5% improvement on UAV dataset compared to state-of-the-art methods ASAT and FAR. The code for POG-MVNet will be made available soon.
QIRL: Boosting Visual Question Answering via Optimized Question-Image Relation Learning
Apr 04, 2025Existing debiasing approaches in Visual Question Answering (VQA) primarily focus on enhancing visual learning, integrating auxiliary models, or employing data augmentation strategies. However, these methods exhibit two major drawbacks. First, current debiasing techniques fail to capture the superior relation between images and texts because prevalent learning frameworks do not enable models to extract deeper correlations from highly contrasting samples. Second, they do not assess the relevance between the input question and image during inference, as no prior work has examined the degree of input relevance in debiasing studies. Motivated by these limitations, we propose a novel framework, Optimized Question-Image Relation Learning (QIRL), which employs a generation-based self-supervised learning strategy. Specifically, two modules are introduced to address the aforementioned issues. The Negative Image Generation (NIG) module automatically produces highly irrelevant question-image pairs during training to enhance correlation learning, while the Irrelevant Sample Identification (ISI) module improves model robustness by detecting and filtering irrelevant inputs, thereby reducing prediction errors. Furthermore, to validate our concept of reducing output errors through filtering unrelated question-image inputs, we propose a specialized metric to evaluate the performance of the ISI module. Notably, our approach is model-agnostic and can be integrated with various VQA models. Extensive experiments on VQA-CPv2 and VQA-v2 demonstrate the effectiveness and generalization ability of our method. Among data augmentation strategies, our approach achieves state-of-the-art results.
Spiking Meets Attention: Efficient Remote Sensing Image Super-Resolution with Attention Spiking Neural Networks
Mar 06, 2025Spiking neural networks (SNNs) are emerging as a promising alternative to traditional artificial neural networks (ANNs), offering biological plausibility and energy efficiency. Despite these merits, SNNs are frequently hampered by limited capacity and insufficient representation power, yet remain underexplored in remote sensing super-resolution (SR) tasks. In this paper, we first observe that spiking signals exhibit drastic intensity variations across diverse textures, highlighting an active learning state of the neurons. This observation motivates us to apply SNNs for efficient SR of RSIs. Inspired by the success of attention mechanisms in representing salient information, we devise the spiking attention block (SAB), a concise yet effective component that optimizes membrane potentials through inferred attention weights, which, in turn, regulates spiking activity for superior feature representation. Our key contributions include: 1) we bridge the independent modulation between temporal and channel dimensions, facilitating joint feature correlation learning, and 2) we access the global self-similar patterns in large-scale remote sensing imagery to infer spatial attention weights, incorporating effective priors for realistic and faithful reconstruction. Building upon SAB, we proposed SpikeSR, which achieves state-of-the-art performance across various remote sensing benchmarks such as AID, DOTA, and DIOR, while maintaining high computational efficiency. The code of SpikeSR will be available upon paper acceptance.
OccludeNet: A Causal Journey into Mixed-View Actor-Centric Video Action Recognition under Occlusions
Nov 24, 2024The lack of occlusion data in commonly used action recognition video datasets limits model robustness and impedes sustained performance improvements. We construct OccludeNet, a large-scale occluded video dataset that includes both real-world and synthetic occlusion scene videos under various natural environments. OccludeNet features dynamic tracking occlusion, static scene occlusion, and multi-view interactive occlusion, addressing existing gaps in data. Our analysis reveals that occlusion impacts action classes differently, with actions involving low scene relevance and partial body visibility experiencing greater accuracy degradation. To overcome the limitations of current occlusion-focused approaches, we propose a structural causal model for occluded scenes and introduce the Causal Action Recognition (CAR) framework, which employs backdoor adjustment and counterfactual reasoning. This framework enhances key actor information, improving model robustness to occlusion. We anticipate that the challenges posed by OccludeNet will stimulate further exploration of causal relations in occlusion scenarios and encourage a reevaluation of class correlations, ultimately promoting sustainable performance improvements. The code and full dataset will be released soon.
Understanding Audiovisual Deepfake Detection: Techniques, Challenges, Human Factors and Perceptual Insights
Nov 12, 2024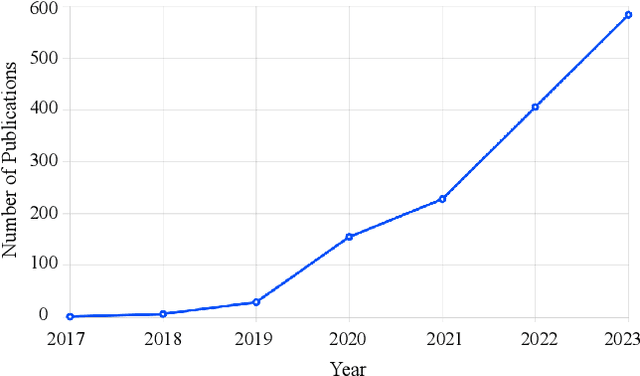

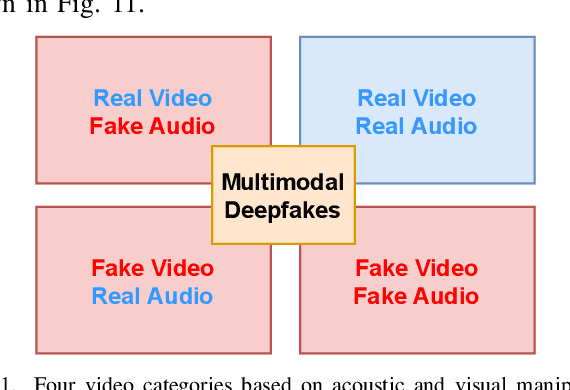
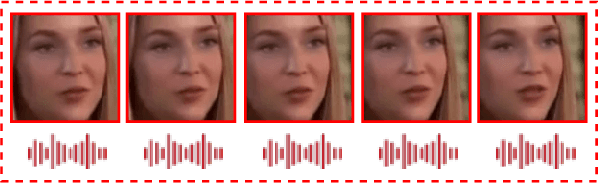
Deep Learning has been successfully applied in diverse fields, and its impact on deepfake detection is no exception. Deepfakes are fake yet realistic synthetic content that can be used deceitfully for political impersonation, phishing, slandering, or spreading misinformation. Despite extensive research on unimodal deepfake detection, identifying complex deepfakes through joint analysis of audio and visual streams remains relatively unexplored. To fill this gap, this survey first provides an overview of audiovisual deepfake generation techniques, applications, and their consequences, and then provides a comprehensive review of state-of-the-art methods that combine audio and visual modalities to enhance detection accuracy, summarizing and critically analyzing their strengths and limitations. Furthermore, we discuss existing open source datasets for a deeper understanding, which can contribute to the research community and provide necessary information to beginners who want to analyze deep learning-based audiovisual methods for video forensics. By bridging the gap between unimodal and multimodal approaches, this paper aims to improve the effectiveness of deepfake detection strategies and guide future research in cybersecurity and media integrity.
TextDestroyer: A Training- and Annotation-Free Diffusion Method for Destroying Anomal Text from Images
Nov 01, 2024In this paper, we propose TextDestroyer, the first training- and annotation-free method for scene text destruction using a pre-trained diffusion model. Existing scene text removal models require complex annotation and retraining, and may leave faint yet recognizable text information, compromising privacy protection and content concealment. TextDestroyer addresses these issues by employing a three-stage hierarchical process to obtain accurate text masks. Our method scrambles text areas in the latent start code using a Gaussian distribution before reconstruction. During the diffusion denoising process, self-attention key and value are referenced from the original latent to restore the compromised background. Latent codes saved at each inversion step are used for replacement during reconstruction, ensuring perfect background restoration. The advantages of TextDestroyer include: (1) it eliminates labor-intensive data annotation and resource-intensive training; (2) it achieves more thorough text destruction, preventing recognizable traces; and (3) it demonstrates better generalization capabilities, performing well on both real-world scenes and generated images.
TANet: Triplet Attention Network for All-In-One Adverse Weather Image Restoration
Oct 10, 2024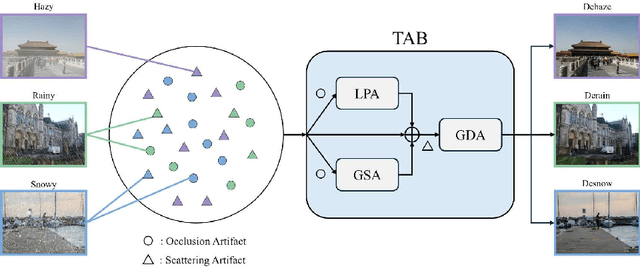
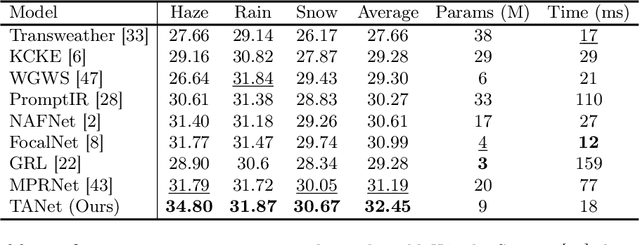
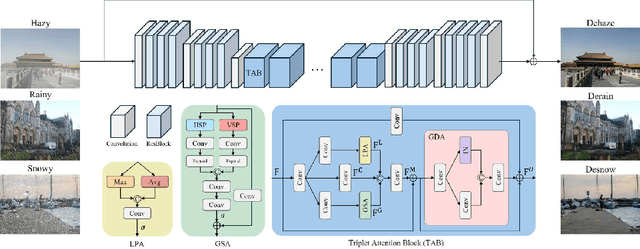
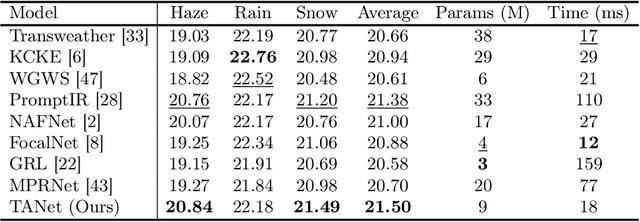
Adverse weather image restoration aims to remove unwanted degraded artifacts, such as haze, rain, and snow, caused by adverse weather conditions. Existing methods achieve remarkable results for addressing single-weather conditions. However, they face challenges when encountering unpredictable weather conditions, which often happen in real-world scenarios. Although different weather conditions exhibit different degradation patterns, they share common characteristics that are highly related and complementary, such as occlusions caused by degradation patterns, color distortion, and contrast attenuation due to the scattering of atmospheric particles. Therefore, we focus on leveraging common knowledge across multiple weather conditions to restore images in a unified manner. In this paper, we propose a Triplet Attention Network (TANet) to efficiently and effectively address all-in-one adverse weather image restoration. TANet consists of Triplet Attention Block (TAB) that incorporates three types of attention mechanisms: Local Pixel-wise Attention (LPA) and Global Strip-wise Attention (GSA) to address occlusions caused by non-uniform degradation patterns, and Global Distribution Attention (GDA) to address color distortion and contrast attenuation caused by atmospheric phenomena. By leveraging common knowledge shared across different weather conditions, TANet successfully addresses multiple weather conditions in a unified manner. Experimental results show that TANet efficiently and effectively achieves state-of-the-art performance in all-in-one adverse weather image restoration. The source code is available at https://github.com/xhuachris/TANet-ACCV-2024.
Efficient Semantic Segmentation via Lightweight Multiple-Information Interaction Network
Oct 03, 2024Recently, the integration of the local modeling capabilities of Convolutional Neural Networks (CNNs) with the global dependency strengths of Transformers has created a sensation in the semantic segmentation community. However, substantial computational workloads and high hardware memory demands remain major obstacles to their further application in real-time scenarios. In this work, we propose a lightweight multiple-information interaction network for real-time semantic segmentation, called LMIINet, which effectively combines CNNs and Transformers while reducing redundant computations and memory footprint. It features Lightweight Feature Interaction Bottleneck (LFIB) modules comprising efficient convolutions that enhance context integration. Additionally, improvements are made to the Flatten Transformer by enhancing local and global feature interaction to capture detailed semantic information. The incorporation of a combination coefficient learning scheme in both LFIB and Transformer blocks facilitates improved feature interaction. Extensive experiments demonstrate that LMIINet excels in balancing accuracy and efficiency. With only 0.72M parameters and 11.74G FLOPs, LMIINet achieves 72.0% mIoU at 100 FPS on the Cityscapes test set and 69.94% mIoU at 160 FPS on the CamVid test dataset using a single RTX2080Ti GPU.