 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGSAN: Dual-Graph Spatiotemporal Attention Network for Pulmonary Nodule Malignancy Prediction
Dec 24, 2025Lung cancer continues to be the leading cause of cancer-related deaths globally. Early detection and diagnosis of pulmonary nodules are essential for improving patient survival rates. Although previous research has integrated multimodal and multi-temporal information, outperforming single modality and single time point, the fusion methods are limited to inefficient vector concatenation and simple mutual attention, highlighting the need for more effective multimodal information fusion. To address these challenges, we introduce a Dual-Graph Spatiotemporal Attention Network, which leverages temporal variations and multimodal data to enhance the accuracy of predictions. Our methodology involves developing a Global-Local Feature Encoder to better capture the local, global, and fused characteristics of pulmonary nodules. Additionally, a Dual-Graph Construction method organizes multimodal features into inter-modal and intra-modal graphs. Furthermore, a Hierarchical Cross-Modal Graph Fusion Module is introduced to refine feature integration. We also compiled a novel multimodal dataset named the NLST-cmst dataset as a comprehensive source of support for related research. Our extensive experiments, conducted on both the NLST-cmst and curated CSTL-derived datasets, demonstrate that our DGSAN significantly outperforms state-of-the-art methods in classifying pulmonary nodules with exceptional computational efficiency.
No Modality Left Behind: Adapting to Missing Modalities via Knowledge Distillation for Brain Tumor Segmentation
Sep 18, 2025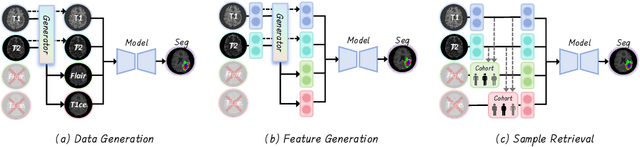
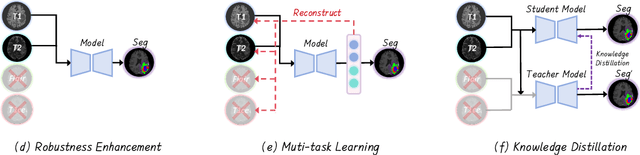
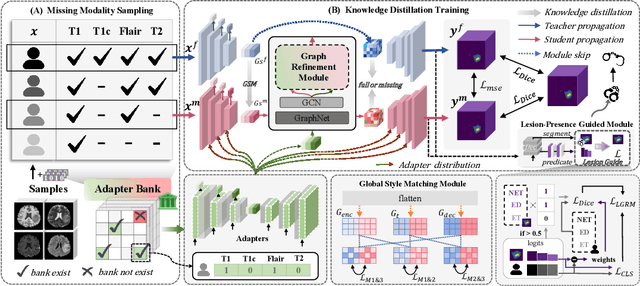
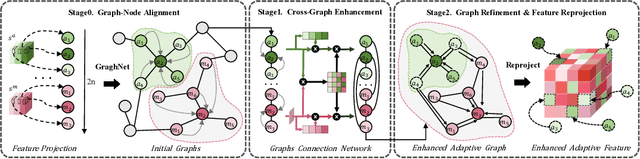
Accurate brain tumor segmentation is essential for preoperative evaluation and personalized treatment. Multi-modal MRI is widely used due to its ability to capture complementary tumor features across different sequences. However, in clinical practice, missing modalities are common, limiting the robustness and generalizability of existing deep learning methods that rely on complete inputs, especially under non-dominant modality combinations. To address this, we propose AdaMM, a multi-modal brain tumor segmentation framework tailored for missing-modality scenarios, centered on knowledge distillation and composed of three synergistic modules. The Graph-guided Adaptive Refinement Module explicitly models semantic associations between generalizable and modality-specific features, enhancing adaptability to modality absence. The Bi-Bottleneck Distillation Module transfers structural and textural knowledge from teacher to student models via global style matching and adversarial feature alignment. The Lesion-Presence-Guided Reliability Module predicts prior probabilities of lesion types through an auxiliary classification task, effectively suppressing false positives under incomplete inputs. Extensive experiments on the BraTS 2018 and 2024 datasets demonstrate that AdaMM consistently outperforms existing methods, exhibiting superior segmentation accuracy and robustness, particularly in single-modality and weak-modality configurations. In addition, we conduct a systematic evaluation of six categories of missing-modality strategies, confirming the superiority of knowledge distillation and offering practical guidance for method selection and future research. Our source code is available at https://github.com/Quanato607/AdaMM.
OccludeNet: A Causal Journey into Mixed-View Actor-Centric Video Action Recognition under Occlusions
Nov 24, 2024The lack of occlusion data in commonly used action recognition video datasets limits model robustness and impedes sustained performance improvements. We construct OccludeNet, a large-scale occluded video dataset that includes both real-world and synthetic occlusion scene videos under various natural environments. OccludeNet features dynamic tracking occlusion, static scene occlusion, and multi-view interactive occlusion, addressing existing gaps in data. Our analysis reveals that occlusion impacts action classes differently, with actions involving low scene relevance and partial body visibility experiencing greater accuracy degradation. To overcome the limitations of current occlusion-focused approaches, we propose a structural causal model for occluded scenes and introduce the Causal Action Recognition (CAR) framework, which employs backdoor adjustment and counterfactual reasoning. This framework enhances key actor information, improving model robustness to occlusion. We anticipate that the challenges posed by OccludeNet will stimulate further exploration of causal relations in occlusion scenarios and encourage a reevaluation of class correlations, ultimately promoting sustainable performance improvements. The code and full dataset will be released soon.
Mitigating Modality Prior-Induced Hallucinations in Multimodal Large Language Models via Deciphering Attention Causality
Oct 07, 2024



Multimodal Large Language Models (MLLMs) have emerged as a central focus in both industry and academia, but often suffer from biases introduced by visual and language priors, which can lead to multimodal hallucination. These biases arise from the visual encoder and the Large Language Model (LLM) backbone, affecting the attention mechanism responsible for aligning multimodal inputs. Existing decoding-based mitigation methods focus on statistical correlations and overlook the causal relationships between attention mechanisms and model output, limiting their effectiveness in addressing these biases. To tackle this issue, we propose a causal inference framework termed CausalMM that applies structural causal modeling to MLLMs, treating modality priors as a confounder between attention mechanisms and output. Specifically, by employing backdoor adjustment and counterfactual reasoning at both the visual and language attention levels, our method mitigates the negative effects of modality priors and enhances the alignment of MLLM's inputs and outputs, with a maximum score improvement of 65.3% on 6 VLind-Bench indicators and 164 points on MME Benchmark compared to conventional methods. Extensive experiments validate the effectiveness of our approach while being a plug-and-play solution. Our code is available at: https://github.com/The-Martyr/CausalMM
Predicting and Accelerating Nanomaterials Synthesis Using Machine Learning Featurization
Sep 12, 2024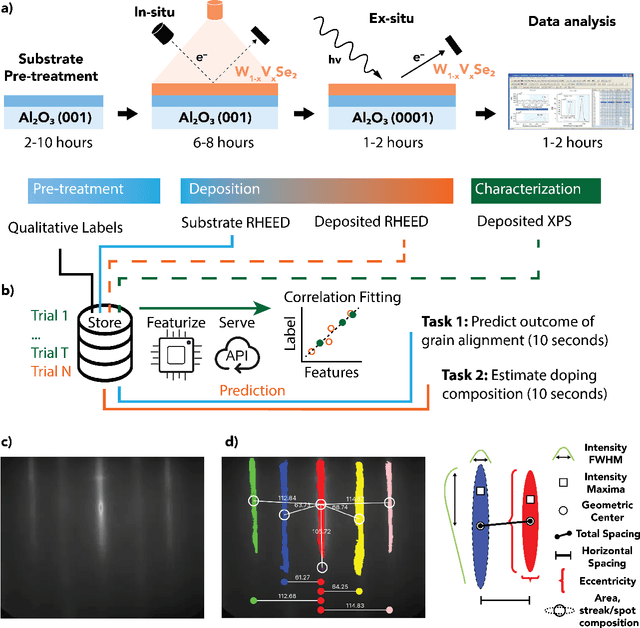
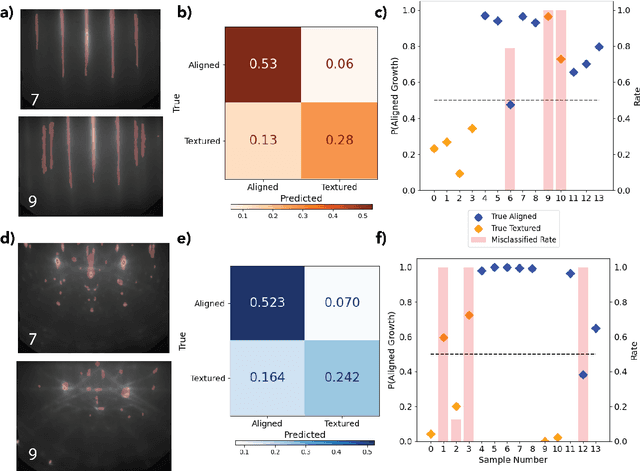
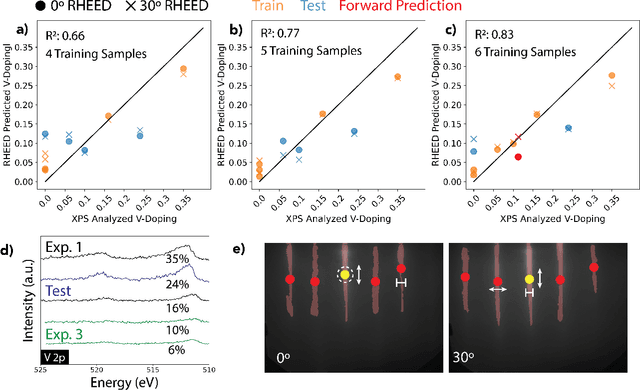
Solving for the complex conditions of materials synthesis and processing requires analyzing information gathered from multiple modes of characterization. Currently, quantitative information is extracted serially with manual tools and intuition, constraining the feedback cycle for process optimization. We use machine learning to automate and generalize feature extraction for in-situ reflection high-energy electron diffraction (RHEED) data to establish quantitatively predictive relationships in small sets ($\sim$10) of expert-labeled data, and apply these to save significant time on subsequent epitaxially grown samples. The fidelity of these relationships is tested on a representative material system ($W_{1-x}V_xSe2$ growth on c-plane sapphire substrate (0001)) at two stages of synthesis with two aims: 1) predicting the grain alignment of the deposited film from the pre-growth substrate surface data, and 2) estimating the vanadium (V) dopant concentration using in-situ RHEED as a proxy for ex-situ methods (e.g. x-ray photoelectron spectroscopy). Both tasks are accomplished using the same set of materials agnostic core features, eliminating the need to retrain for specific systems and leading to a potential 80\% time saving over a 100 sample synthesis campaign. These predictions provide guidance for recipe adjustments to avoid doomed trials, reduce follow-on characterization, and improve control resolution for materials synthesis, ultimately accelerating materials discovery and commercial scale-up.
LPUWF-LDM: Enhanced Latent Diffusion Model for Precise Late-phase UWF-FA Generation on Limited Dataset
Sep 01, 2024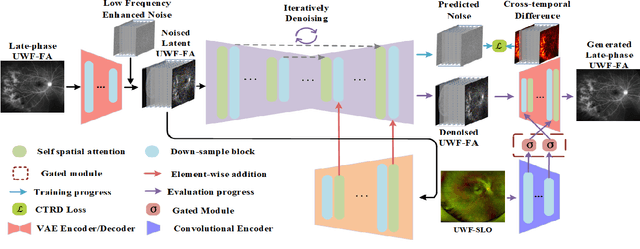
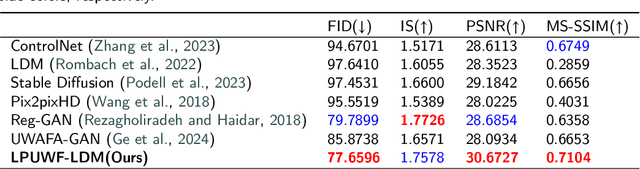
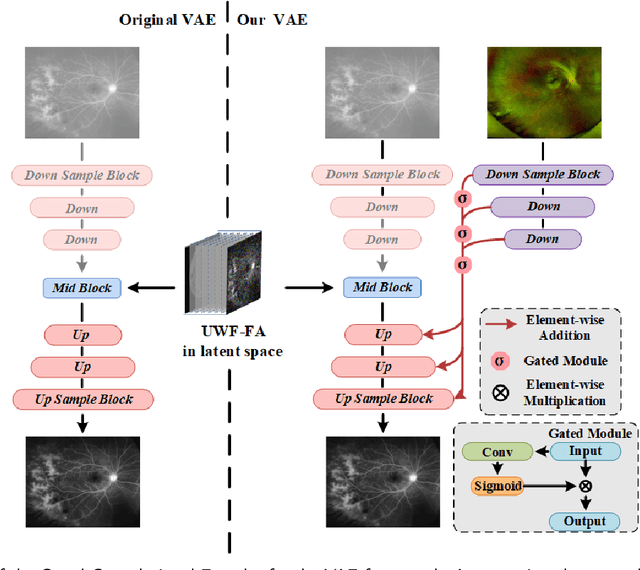

Ultra-Wide-Field Fluorescein Angiography (UWF-FA) enables precise identification of ocular diseases using sodium fluorescein, which can be potentially harmful. Existing research has developed methods to generate UWF-FA from Ultra-Wide-Field Scanning Laser Ophthalmoscopy (UWF-SLO) to reduce the adverse reactions associated with injections. However, these methods have been less effective in producing high-quality late-phase UWF-FA, particularly in lesion areas and fine details. Two primary challenges hinder the generation of high-quality late-phase UWF-FA: the scarcity of paired UWF-SLO and early/late-phase UWF-FA datasets, and the need for realistic generation at lesion sites and potential blood leakage regions. This study introduces an improved latent diffusion model framework to generate high-quality late-phase UWF-FA from limited paired UWF images. To address the challenges as mentioned earlier, our approach employs a module utilizing Cross-temporal Regional Difference Loss, which encourages the model to focus on the differences between early and late phases. Additionally, we introduce a low-frequency enhanced noise strategy in the diffusion forward process to improve the realism of medical images. To further enhance the mapping capability of the variational autoencoder module, especially with limited datasets, we implement a Gated Convolutional Encoder to extract additional information from conditional images. Our Latent Diffusion Model for Ultra-Wide-Field Late-Phase Fluorescein Angiography (LPUWF-LDM) effectively reconstructs fine details in late-phase UWF-FA and achieves state-of-the-art results compared to other existing methods when working with limited datasets. Our source code is available at: https://github.com/Tinysqua/****.
TC-KANRecon: High-Quality and Accelerated MRI Reconstruction via Adaptive KAN Mechanisms and Intelligent Feature Scaling
Aug 11, 2024



Magnetic Resonance Imaging (MRI) has become essential in clinical diagnosis due to its high resolution and multiple contrast mechanisms. However, the relatively long acquisition time limits its broader application. To address this issue, this study presents an innovative conditional guided diffusion model, named as TC-KANRecon, which incorporates the Multi-Free U-KAN (MF-UKAN) module and a dynamic clipping strategy. TC-KANRecon model aims to accelerate the MRI reconstruction process through deep learning methods while maintaining the quality of the reconstructed images. The MF-UKAN module can effectively balance the tradeoff between image denoising and structure preservation. Specifically, it presents the multi-head attention mechanisms and scalar modulation factors, which significantly enhances the model's robustness and structure preservation capabilities in complex noise environments. Moreover, the dynamic clipping strategy in TC-KANRecon adjusts the cropping interval according to the sampling steps, thereby mitigating image detail loss typically caused by traditional cropping methods and enriching the visual features of the images. Furthermore, the MC-Model module incorporates full-sampling k-space information, realizing efficient fusion of conditional information, enhancing the model's ability to process complex data, and improving the realism and detail richness of reconstructed images. Experimental results demonstrate that the proposed method outperforms other MRI reconstruction methods in both qualitative and quantitative evaluations. Notably, TC-KANRecon method exhibits excellent reconstruction results when processing high-noise, low-sampling-rate MRI data. Our source code is available at https://github.com/lcbkmm/TC-KANRecon.
Macroscopic auxiliary asymptotic preserving neural networks for the linear radiative transfer equations
Mar 04, 2024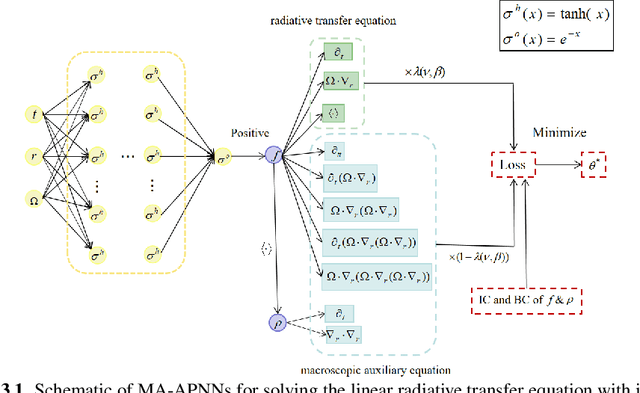
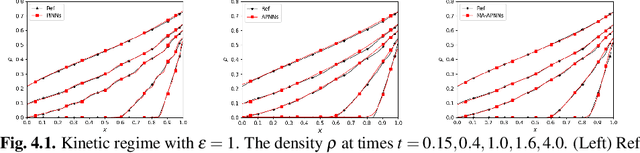

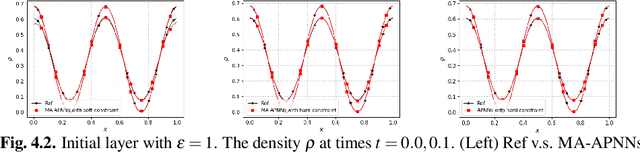
We develop a Macroscopic Auxiliary Asymptotic-Preserving Neural Network (MA-APNN) method to solve the time-dependent linear radiative transfer equations (LRTEs), which have a multi-scale nature and high dimensionality. To achieve this, we utilize the Physics-Informed Neural Networks (PINNs) framework and design a new adaptive exponentially weighted Asymptotic-Preserving (AP) loss function, which incorporates the macroscopic auxiliary equation that is derived from the original transfer equation directly and explicitly contains the information of the diffusion limit equation. Thus, as the scale parameter tends to zero, the loss function gradually transitions from the transport state to the diffusion limit state. In addition, the initial data, boundary conditions, and conservation laws serve as the regularization terms for the loss. We present several numerical examples to demonstrate the effectiveness of MA-APNNs.
A model-data asymptotic-preserving neural network method based on micro-macro decomposition for gray radiative transfer equations
Dec 11, 2022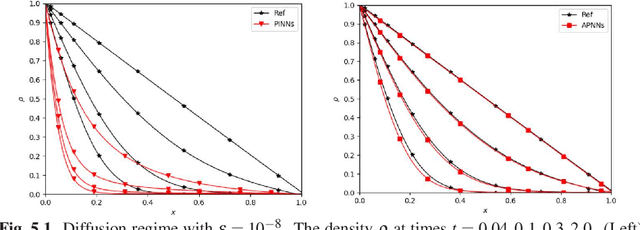
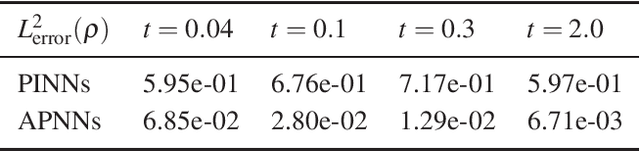
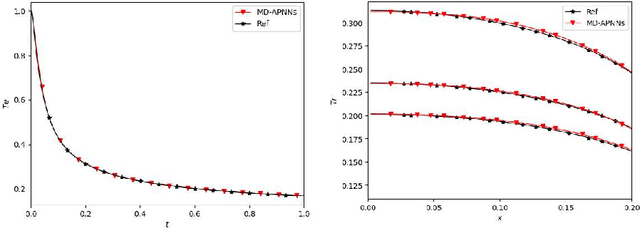
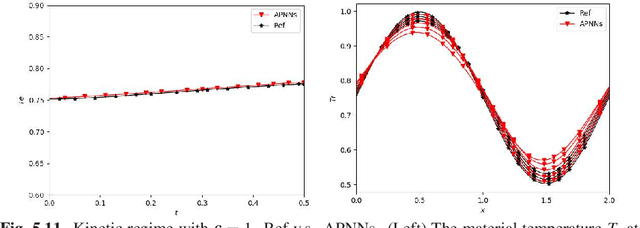
We propose a model-data asymptotic-preserving neural network(MD-APNN) method to solve the nonlinear gray radiative transfer equations(GRTEs). The system is challenging to be simulated with both the traditional numerical schemes and the vanilla physics-informed neural networks(PINNs) due to the multiscale characteristics. Under the framework of PINNs, we employ a micro-macro decomposition technique to construct a new asymptotic-preserving(AP) loss function, which includes the residual of the governing equations in the micro-macro coupled form, the initial and boundary conditions with additional diffusion limit information, the conservation laws, and a few labeled data. A convergence analysis is performed for the proposed method, and a number of numerical examples are presented to illustrate the efficiency of MD-APNNs, and particularly, the importance of the AP property in the neural networks for the diffusion dominating problems. The numerical results indicate that MD-APNNs lead to a better performance than APNNs or pure data-driven networks in the simulation of the nonlinear non-stationary GRTEs.