 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Filtered Backprojection by Learnable Interpolation Network
May 03, 2025Accurate reconstruction of computed tomography (CT) images is crucial in medical imaging field. However, there are unavoidable interpolation errors in the backprojection step of the conventional reconstruction methods, i.e., filtered-back-projection based methods, which are detrimental to the accurate reconstruction. In this study, to address this issue, we propose a novel deep learning model, named Leanable-Interpolation-based FBP or LInFBP shortly, to enhance the reconstructed CT image quality, which achieves learnable interpolation in the backprojection step of filtered backprojection (FBP) and alleviates the interpolation errors. Specifically, in the proposed LInFBP, we formulate every local piece of the latent continuous function of discrete sinogram data as a linear combination of selected basis functions, and learn this continuous function by exploiting a deep network to predict the linear combination coefficients. Then, the learned latent continuous function is exploited for interpolation in backprojection step, which first time takes the advantage of deep learning for the interpolation in FBP. Extensive experiments, which encompass diverse CT scenarios, demonstrate the effectiveness of the proposed LInFBP in terms of enhanced reconstructed image quality, plug-and-play ability and generalization capability.
SS-CTML: Self-Supervised Cross-Task Mutual Learning for CT Image Reconstruction
Dec 31, 2024



Supervised deep-learning (SDL) techniques with paired training datasets have been widely studied for X-ray computed tomography (CT) image reconstruction. However, due to the difficulties of obtaining paired training datasets in clinical routine, the SDL methods are still away from common uses in clinical practices. In recent years, self-supervised deep-learning (SSDL) techniques have shown great potential for the studies of CT image reconstruction. In this work, we propose a self-supervised cross-task mutual learning (SS-CTML) framework for CT image reconstruction. Specifically, a sparse-view scanned and a limited-view scanned sinogram data are first extracted from a full-view scanned sinogram data, which results in three individual reconstruction tasks, i.e., the full-view CT (FVCT) reconstruction, the sparse-view CT (SVCT) reconstruction, and limited-view CT (LVCT) reconstruction. Then, three neural networks are constructed for the three reconstruction tasks. Considering that the ultimate goals of the three tasks are all to reconstruct high-quality CT images, we therefore construct a set of cross-task mutual learning objectives for the three tasks, in which way, the three neural networks can be self-supervised optimized by learning from each other. Clinical datasets are adopted to evaluate the effectiveness of the proposed framework. Experimental results demonstrate that the SS-CTML framework can obtain promising CT image reconstruction performance in terms of both quantitative and qualitative measurements.
TC-KANRecon: High-Quality and Accelerated MRI Reconstruction via Adaptive KAN Mechanisms and Intelligent Feature Scaling
Aug 11, 2024



Magnetic Resonance Imaging (MRI) has become essential in clinical diagnosis due to its high resolution and multiple contrast mechanisms. However, the relatively long acquisition time limits its broader application. To address this issue, this study presents an innovative conditional guided diffusion model, named as TC-KANRecon, which incorporates the Multi-Free U-KAN (MF-UKAN) module and a dynamic clipping strategy. TC-KANRecon model aims to accelerate the MRI reconstruction process through deep learning methods while maintaining the quality of the reconstructed images. The MF-UKAN module can effectively balance the tradeoff between image denoising and structure preservation. Specifically, it presents the multi-head attention mechanisms and scalar modulation factors, which significantly enhances the model's robustness and structure preservation capabilities in complex noise environments. Moreover, the dynamic clipping strategy in TC-KANRecon adjusts the cropping interval according to the sampling steps, thereby mitigating image detail loss typically caused by traditional cropping methods and enriching the visual features of the images. Furthermore, the MC-Model module incorporates full-sampling k-space information, realizing efficient fusion of conditional information, enhancing the model's ability to process complex data, and improving the realism and detail richness of reconstructed images. Experimental results demonstrate that the proposed method outperforms other MRI reconstruction methods in both qualitative and quantitative evaluations. Notably, TC-KANRecon method exhibits excellent reconstruction results when processing high-noise, low-sampling-rate MRI data. Our source code is available at https://github.com/lcbkmm/TC-KANRecon.
Don't Fear Peculiar Activation Functions: EUAF and Beyond
Jul 12, 2024



In this paper, we propose a new super-expressive activation function called the Parametric Elementary Universal Activation Function (PEUAF). We demonstrate the effectiveness of PEUAF through systematic and comprehensive experiments on various industrial and image datasets, including CIFAR10, Tiny-ImageNet, and ImageNet. Moreover, we significantly generalize the family of super-expressive activation functions, whose existence has been demonstrated in several recent works by showing that any continuous function can be approximated to any desired accuracy by a fixed-size network with a specific super-expressive activation function. Specifically, our work addresses two major bottlenecks in impeding the development of super-expressive activation functions: the limited identification of super-expressive functions, which raises doubts about their broad applicability, and their often peculiar forms, which lead to skepticism regarding their scalability and practicality in real-world applications.
TC-DiffRecon: Texture coordination MRI reconstruction method based on diffusion model and modified MF-UNet method
Feb 17, 2024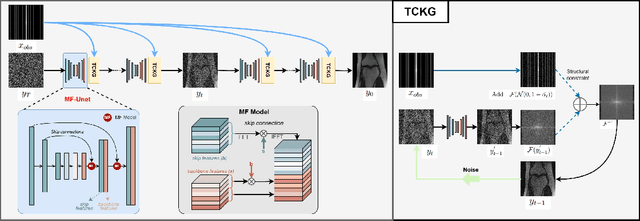


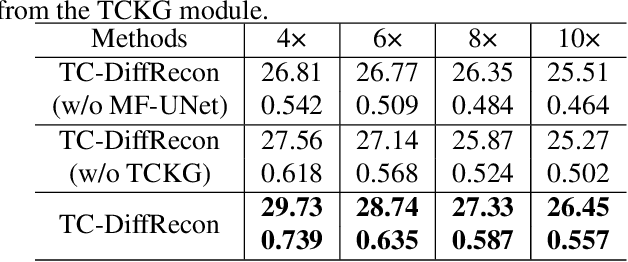
Recently, diffusion models have gained significant attention as a novel set of deep learning-based generative methods. These models attempt to sample data from a Gaussian distribution that adheres to a target distribution, and have been successfully adapted to the reconstruction of MRI data. However, as an unconditional generative model, the diffusion model typically disrupts image coordination because of the consistent projection of data introduced by conditional bootstrap. This often results in image fragmentation and incoherence. Furthermore, the inherent limitations of the diffusion model often lead to excessive smoothing of the generated images. In the same vein, some deep learning-based models often suffer from poor generalization performance, meaning their effectiveness is greatly affected by different acceleration factors. To address these challenges, we propose a novel diffusion model-based MRI reconstruction method, named TC-DiffRecon, which does not rely on a specific acceleration factor for training. We also suggest the incorporation of the MF-UNet module, designed to enhance the quality of MRI images generated by the model while mitigating the over-smoothing issue to a certain extent. During the image generation sampling process, we employ a novel TCKG module and a Coarse-to-Fine sampling scheme. These additions aim to harmonize image texture, expedite the sampling process, while achieving data consistency. Our source code is available at https://github.com/JustlfC03/TC-DiffRecon.
* 5 pages, 2 figures, accept ISBI2024
A Peer-to-peer Federated Continual Learning Network for Improving CT Imaging from Multiple Institutions
Jun 03, 2023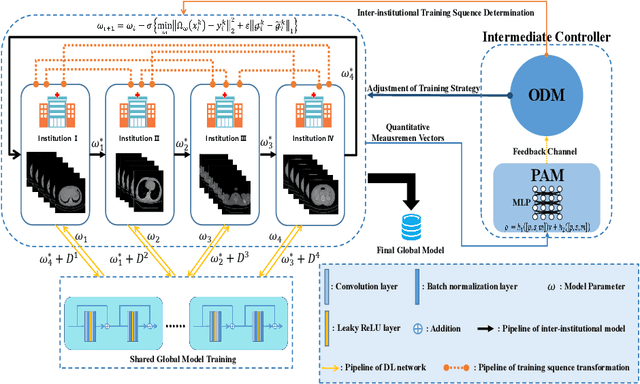

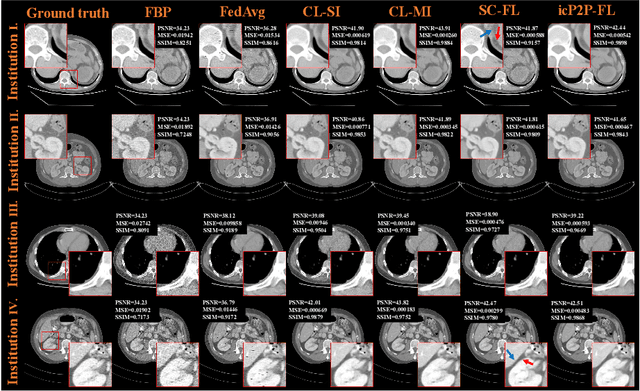
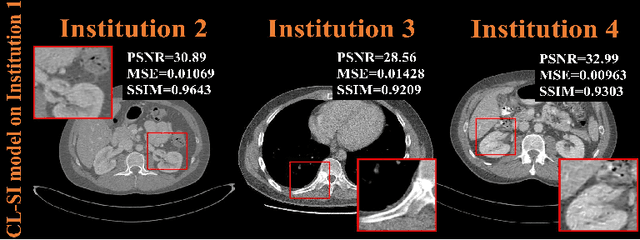
Deep learning techniques have been widely used in computed tomography (CT) but require large data sets to train networks. Moreover, data sharing among multiple institutions is limited due to data privacy constraints, which hinders the development of high-performance DL-based CT imaging models from multi-institutional collaborations. Federated learning (FL) strategy is an alternative way to train the models without centralizing data from multi-institutions. In this work, we propose a novel peer-to-peer federated continual learning strategy to improve low-dose CT imaging performance from multiple institutions. The newly proposed method is called peer-to-peer continual FL with intermediate controllers, i.e., icP2P-FL. Specifically, different from the conventional FL model, the proposed icP2P-FL does not require a central server that coordinates training information for a global model. In the proposed icP2P-FL method, the peer-to-peer federated continual learning is introduced wherein the DL-based model is continually trained one client after another via model transferring and inter institutional parameter sharing due to the common characteristics of CT data among the clients. Furthermore, an intermediate controller is developed to make the overall training more flexible. Numerous experiments were conducted on the AAPM low-dose CT Grand Challenge dataset and local datasets, and the experimental results showed that the proposed icP2P-FL method outperforms the other comparative methods both qualitatively and quantitatively, and reaches an accuracy similar to a model trained with pooling data from all the institutions.
Direct Energy-resolving CT Imaging via Energy-integrating CT images using a Unified Generative Adversarial Network
Oct 14, 2019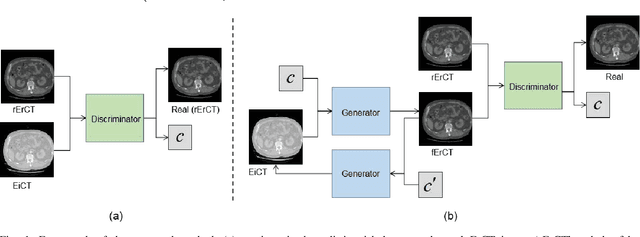
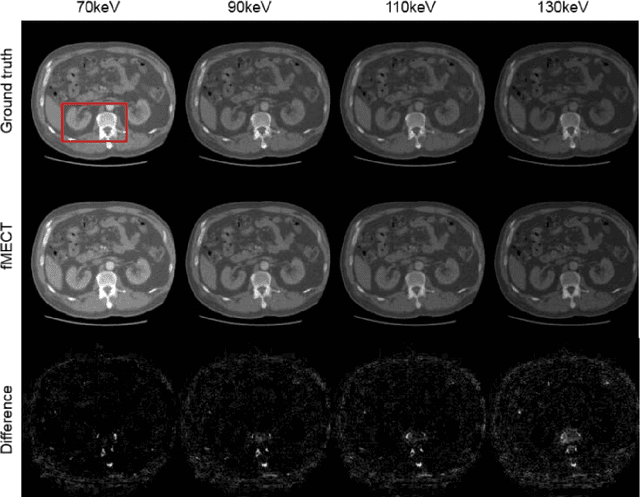
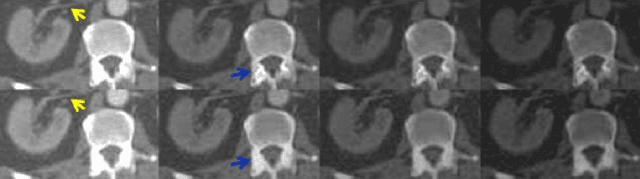
Energy-resolving computed tomography (ErCT) has the ability to acquire energy-dependent measurements simultaneously and quantitative material information with improved contrast-to-noise ratio. Meanwhile, ErCT imaging system is usually equipped with an advanced photon counting detector, which is expensive and technically complex. Therefore, clinical ErCT scanners are not yet commercially available, and they are in various stage of completion. This makes the researchers less accessible to the ErCT images. In this work, we investigate to produce ErCT images directly from existing energy-integrating CT (EiCT) images via deep neural network. Specifically, different from other networks that produce ErCT images at one specific energy, this model employs a unified generative adversarial network (uGAN) to concurrently train EiCT datasets and ErCT datasets with different energies and then performs image-to-image translation from existing EiCT images to multiple ErCT image outputs at various energy bins. In this study, the present uGAN generates ErCT images at 70keV, 90keV, 110keV, and 130keV simultaneously from EiCT images at140kVp. We evaluate the present uGAN model on a set of over 1380 CT image slices and show that the present uGAN model can produce promising ErCT estimation results compared with the ground truth qualitatively and quantitatively.
Unsupervised/Semi-supervised Deep Learning for Low-dose CT Enhancement
Aug 08, 2018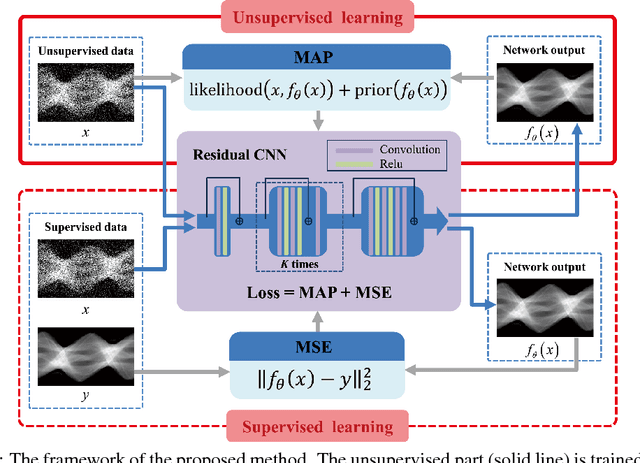
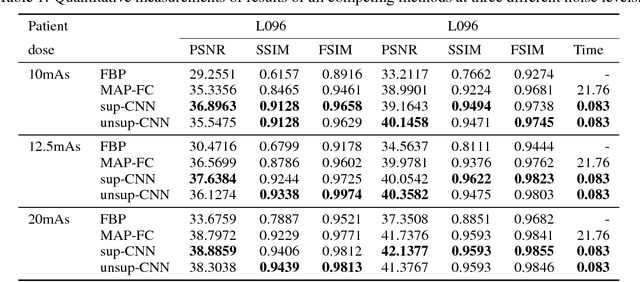

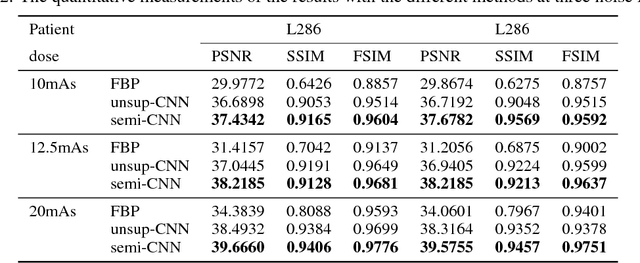
Recently, deep learning(DL) methods have been proposed for the low-dose computed tomography(LdCT) enhancement, and obtain good trade-off between computational efficiency and image quality. Most of them need large number of pre-collected ground-truth/high-dose sinograms with less noise, and train the network in a supervised end-to-end manner. This may bring major limitations on these methods because the number of such low-dose/high-dose training sinogram pairs would affect the network's capability and sometimes the ground-truth sinograms are hard to be obtained in large scale. Since large number of low-dose ones are relatively easy to obtain, it should be critical to make these sources play roles in network training in an unsupervised learning manner. To address this issue, we propose an unsupervised DL method for LdCT enhancement that incorporates unlabeled LdCT sinograms directly into the network training. The proposed method effectively considers the structure characteristics and noise distribution in the measured LdCT sinogram, and then learns the proper gradient of the LdCT sinogram in a pure unsupervised manner. Similar to the labeled ground-truth, the gradient information in an unlabeled LdCT sinogram can be used for sufficient network training. The experiments on the patient data show effectiveness of the proposed method.