 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSFADNet: Spatio-temporal Fused Graph based on Attention Decoupling Network for Traffic Prediction
Jan 07, 2025



In recent years, traffic flow prediction has played a crucial role in the management of intelligent transportation systems. However, traditional prediction methods are often limited by static spatial modeling, making it difficult to accurately capture the dynamic and complex relationships between time and space, thereby affecting prediction accuracy. This paper proposes an innovative traffic flow prediction network, SFADNet, which categorizes traffic flow into multiple traffic patterns based on temporal and spatial feature matrices. For each pattern, we construct an independent adaptive spatio-temporal fusion graph based on a cross-attention mechanism, employing residual graph convolution modules and time series modules to better capture dynamic spatio-temporal relationships under different fine-grained traffic patterns. Extensive experimental results demonstrate that SFADNet outperforms current state-of-the-art baselines across four large-scale datasets.
MHGNet: Multi-Heterogeneous Graph Neural Network for Traffic Prediction
Jan 07, 2025



In recent years, traffic flow prediction has played a crucial role in the management of intelligent transportation systems. However, traditional forecasting methods often model non-Euclidean low-dimensional traffic data as a simple graph with single-type nodes and edges, failing to capture similar trends among nodes of the same type. To address this limitation, this paper proposes MHGNet, a novel framework for modeling spatiotemporal multi-heterogeneous graphs. Within this framework, the STD Module decouples single-pattern traffic data into multi-pattern traffic data through feature mappings of timestamp embedding matrices and node embedding matrices. Subsequently, the Node Clusterer leverages the Euclidean distance between nodes and different types of limit points to perform clustering with O(N) time complexity. The nodes within each cluster undergo residual subgraph convolution within the spatiotemporal fusion subgraphs generated by the DSTGG Module, followed by processing in the SIE Module for node repositioning and redistribution of weights. To validate the effectiveness of MHGNet, this paper conducts extensive ablation studies and quantitative evaluations on four widely used benchmarks, demonstrating its superior performance.
Pattern-Matching Dynamic Memory Network for Dual-Mode Traffic Prediction
Aug 12, 2024



In recent years, deep learning has increasingly gained attention in the field of traffic prediction. Existing traffic prediction models often rely on GCNs or attention mechanisms with O(N^2) complexity to dynamically extract traffic node features, which lack efficiency and are not lightweight. Additionally, these models typically only utilize historical data for prediction, without considering the impact of the target information on the prediction. To address these issues, we propose a Pattern-Matching Dynamic Memory Network (PM-DMNet). PM-DMNet employs a novel dynamic memory network to capture traffic pattern features with only O(N) complexity, significantly reducing computational overhead while achieving excellent performance. The PM-DMNet also introduces two prediction methods: Recursive Multi-step Prediction (RMP) and Parallel Multi-step Prediction (PMP), which leverage the time features of the prediction targets to assist in the forecasting process. Furthermore, a transfer attention mechanism is integrated into PMP, transforming historical data features to better align with the predicted target states, thereby capturing trend changes more accurately and reducing errors. Extensive experiments demonstrate the superiority of the proposed model over existing benchmarks. The source codes are available at: https://github.com/wengwenchao123/PM-DMNet.
TC-DiffRecon: Texture coordination MRI reconstruction method based on diffusion model and modified MF-UNet method
Feb 17, 2024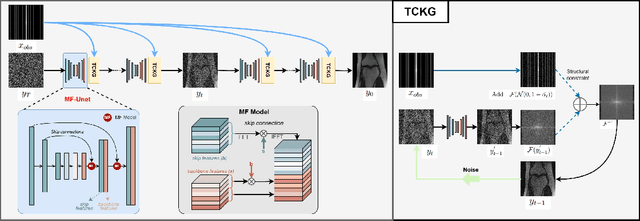


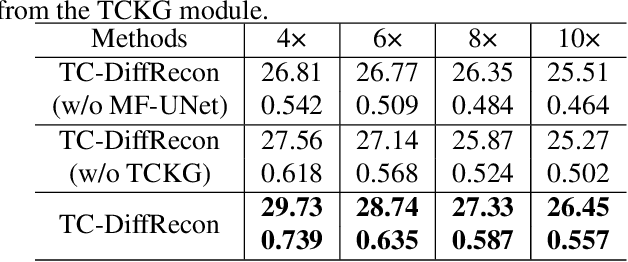
Recently, diffusion models have gained significant attention as a novel set of deep learning-based generative methods. These models attempt to sample data from a Gaussian distribution that adheres to a target distribution, and have been successfully adapted to the reconstruction of MRI data. However, as an unconditional generative model, the diffusion model typically disrupts image coordination because of the consistent projection of data introduced by conditional bootstrap. This often results in image fragmentation and incoherence. Furthermore, the inherent limitations of the diffusion model often lead to excessive smoothing of the generated images. In the same vein, some deep learning-based models often suffer from poor generalization performance, meaning their effectiveness is greatly affected by different acceleration factors. To address these challenges, we propose a novel diffusion model-based MRI reconstruction method, named TC-DiffRecon, which does not rely on a specific acceleration factor for training. We also suggest the incorporation of the MF-UNet module, designed to enhance the quality of MRI images generated by the model while mitigating the over-smoothing issue to a certain extent. During the image generation sampling process, we employ a novel TCKG module and a Coarse-to-Fine sampling scheme. These additions aim to harmonize image texture, expedite the sampling process, while achieving data consistency. Our source code is available at https://github.com/JustlfC03/TC-DiffRecon.
* 5 pages, 2 figures, accept ISBI2024