 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTC-KANRecon: High-Quality and Accelerated MRI Reconstruction via Adaptive KAN Mechanisms and Intelligent Feature Scaling
Aug 11, 2024



Magnetic Resonance Imaging (MRI) has become essential in clinical diagnosis due to its high resolution and multiple contrast mechanisms. However, the relatively long acquisition time limits its broader application. To address this issue, this study presents an innovative conditional guided diffusion model, named as TC-KANRecon, which incorporates the Multi-Free U-KAN (MF-UKAN) module and a dynamic clipping strategy. TC-KANRecon model aims to accelerate the MRI reconstruction process through deep learning methods while maintaining the quality of the reconstructed images. The MF-UKAN module can effectively balance the tradeoff between image denoising and structure preservation. Specifically, it presents the multi-head attention mechanisms and scalar modulation factors, which significantly enhances the model's robustness and structure preservation capabilities in complex noise environments. Moreover, the dynamic clipping strategy in TC-KANRecon adjusts the cropping interval according to the sampling steps, thereby mitigating image detail loss typically caused by traditional cropping methods and enriching the visual features of the images. Furthermore, the MC-Model module incorporates full-sampling k-space information, realizing efficient fusion of conditional information, enhancing the model's ability to process complex data, and improving the realism and detail richness of reconstructed images. Experimental results demonstrate that the proposed method outperforms other MRI reconstruction methods in both qualitative and quantitative evaluations. Notably, TC-KANRecon method exhibits excellent reconstruction results when processing high-noise, low-sampling-rate MRI data. Our source code is available at https://github.com/lcbkmm/TC-KANRecon.
GFE-Mamba: Mamba-based AD Multi-modal Progression Assessment via Generative Feature Extraction from MCI
Jul 22, 2024Alzheimer's Disease (AD) is an irreversible neurodegenerative disorder that often progresses from Mild Cognitive Impairment (MCI), leading to memory loss and significantly impacting patients' lives. Clinical trials indicate that early targeted interventions for MCI patients can potentially slow or halt the development and progression of AD. Previous research has shown that accurate medical classification requires the inclusion of extensive multimodal data, such as assessment scales and various neuroimaging techniques like Magnetic Resonance Imaging (MRI) and Positron Emission Tomography (PET). However, consistently tracking the diagnosis of the same individual over time and simultaneously collecting multimodal data poses significant challenges. To address this issue, we introduce GFE-Mamba, a classifier based on Generative Feature Extraction (GFE). This classifier effectively integrates data from assessment scales, MRI, and PET, enabling deeper multimodal fusion. It efficiently extracts both long and short sequence information and incorporates additional information beyond the pixel space. This approach not only improves classification accuracy but also enhances the interpretability and stability of the model. We constructed datasets of over 3000 samples based on the Alzheimer's Disease Neuroimaging Initiative (ADNI) for a two-step training process. Our experimental results demonstrate that the GFE-Mamba model is effective in predicting the conversion from MCI to AD and outperforms several state-of-the-art methods. Our source code and ADNI dataset processing code are available at https://github.com/Tinysqua/GFE-Mamba.
TC-DiffRecon: Texture coordination MRI reconstruction method based on diffusion model and modified MF-UNet method
Feb 17, 2024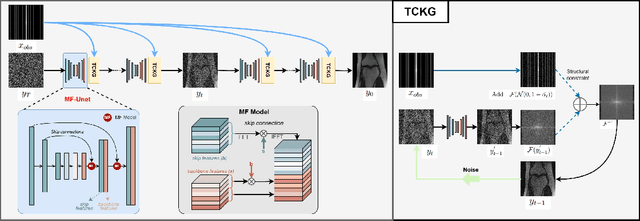


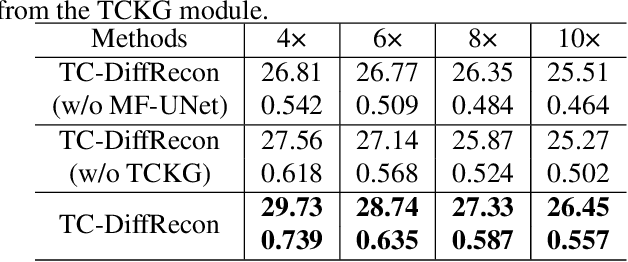
Recently, diffusion models have gained significant attention as a novel set of deep learning-based generative methods. These models attempt to sample data from a Gaussian distribution that adheres to a target distribution, and have been successfully adapted to the reconstruction of MRI data. However, as an unconditional generative model, the diffusion model typically disrupts image coordination because of the consistent projection of data introduced by conditional bootstrap. This often results in image fragmentation and incoherence. Furthermore, the inherent limitations of the diffusion model often lead to excessive smoothing of the generated images. In the same vein, some deep learning-based models often suffer from poor generalization performance, meaning their effectiveness is greatly affected by different acceleration factors. To address these challenges, we propose a novel diffusion model-based MRI reconstruction method, named TC-DiffRecon, which does not rely on a specific acceleration factor for training. We also suggest the incorporation of the MF-UNet module, designed to enhance the quality of MRI images generated by the model while mitigating the over-smoothing issue to a certain extent. During the image generation sampling process, we employ a novel TCKG module and a Coarse-to-Fine sampling scheme. These additions aim to harmonize image texture, expedite the sampling process, while achieving data consistency. Our source code is available at https://github.com/JustlfC03/TC-DiffRecon.
* 5 pages, 2 figures, accept ISBI2024
Semi-supervised Medical Image Segmentation Method Based on Cross-pseudo Labeling Leveraging Strong and Weak Data Augmentation Strategies
Feb 17, 2024Traditional supervised learning methods have historically encountered certain constraints in medical image segmentation due to the challenging collection process, high labeling cost, low signal-to-noise ratio, and complex features characterizing biomedical images. This paper proposes a semi-supervised model, DFCPS, which innovatively incorporates the Fixmatch concept. This significantly enhances the model's performance and generalizability through data augmentation processing, employing varied strategies for unlabeled data. Concurrently, the model design gives appropriate emphasis to the generation, filtration, and refinement processes of pseudo-labels. The novel concept of cross-pseudo-supervision is introduced, integrating consistency learning with self-training. This enables the model to fully leverage pseudo-labels from multiple perspectives, thereby enhancing training diversity. The DFCPS model is compared with both baseline and advanced models using the publicly accessible Kvasir-SEG dataset. Across all four subdivisions containing different proportions of unlabeled data, our model consistently exhibits superior performance. Our source code is available at https://github.com/JustlfC03/DFCPS.
* 5 pages, 2 figures, accept ISBI2024
Accurate Leukocyte Detection Based on Deformable-DETR and Multi-Level Feature Fusion for Aiding Diagnosis of Blood Diseases
Jan 10, 2024



In standard hospital blood tests, the traditional process requires doctors to manually isolate leukocytes from microscopic images of patients' blood using microscopes. These isolated leukocytes are then categorized via automatic leukocyte classifiers to determine the proportion and volume of different types of leukocytes present in the blood samples, aiding disease diagnosis. This methodology is not only time-consuming and labor-intensive, but it also has a high propensity for errors due to factors such as image quality and environmental conditions, which could potentially lead to incorrect subsequent classifications and misdiagnosis. To address these issues, this paper proposes an innovative method of leukocyte detection: the Multi-level Feature Fusion and Deformable Self-attention DETR (MFDS-DETR). To tackle the issue of leukocyte scale disparity, we designed the High-level Screening-feature Fusion Pyramid (HS-FPN), enabling multi-level fusion. This model uses high-level features as weights to filter low-level feature information via a channel attention module and then merges the screened information with the high-level features, thus enhancing the model's feature expression capability. Further, we address the issue of leukocyte feature scarcity by incorporating a multi-scale deformable self-attention module in the encoder and using the self-attention and cross-deformable attention mechanisms in the decoder, which aids in the extraction of the global features of the leukocyte feature maps. The effectiveness, superiority, and generalizability of the proposed MFDS-DETR method are confirmed through comparisons with other cutting-edge leukocyte detection models using the private WBCDD, public LISC and BCCD datasets. Our source code and private WBCCD dataset are available at https://github.com/JustlfC03/MFDS-DETR.
* 15 pages, 11 figures, accept Computers in Biology and Medicine 2024
SCUNet++: Swin-UNet and CNN Bottleneck Hybrid Architecture with Multi-Fusion Dense Skip Connection for Pulmonary Embolism CT Image Segmentation
Jan 03, 2024Pulmonary embolism (PE) is a prevalent lung disease that can lead to right ventricular hypertrophy and failure in severe cases, ranking second in severity only to myocardial infarction and sudden death. Pulmonary artery CT angiography (CTPA) is a widely used diagnostic method for PE. However, PE detection presents challenges in clinical practice due to limitations in imaging technology. CTPA can produce noises similar to PE, making confirmation of its presence time-consuming and prone to overdiagnosis. Nevertheless, the traditional segmentation method of PE can not fully consider the hierarchical structure of features, local and global spatial features of PE CT images. In this paper, we propose an automatic PE segmentation method called SCUNet++ (Swin Conv UNet++). This method incorporates multiple fusion dense skip connections between the encoder and decoder, utilizing the Swin Transformer as the encoder. And fuses features of different scales in the decoder subnetwork to compensate for spatial information loss caused by the inevitable downsampling in Swin-UNet or other state-of-the-art methods, effectively solving the above problem. We provide a theoretical analysis of this method in detail and validate it on publicly available PE CT image datasets FUMPE and CAD-PE. The experimental results indicate that our proposed method achieved a Dice similarity coefficient (DSC) of 83.47% and a Hausdorff distance 95th percentile (HD95) of 3.83 on the FUMPE dataset, as well as a DSC of 83.42% and an HD95 of 5.10 on the CAD-PE dataset. These findings demonstrate that our method exhibits strong performance in PE segmentation tasks, potentially enhancing the accuracy of automatic segmentation of PE and providing a powerful diagnostic tool for clinical physicians. Our source code and new FUMPE dataset are available at https://github.com/JustlfC03/SCUNet-plusplus.
* 10 pages, 7 figures, accept WACV2024