 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFM-Recon: Unlocking Cross-Domain Scene-Level Neural Reconstruction with Scale-Aligned Foundation Priors
Mar 13, 2026Scene-level neural volumetric reconstruction from monocular videos remains challenging, especially under severe domain shifts. Although recent advances in vision foundation models (VFMs) provide transferable generalized priors learned from large-scale data, their scaleambiguous predictions are incompatible with the scale consistency required by volumetric fusion. To address this gap, we present VFMRecon, the first attempt to bridge transferable VFM priors with scaleconsistent requirements in scene-level neural reconstruction. Specifically, we first introduce a lightweight scale alignment stage that restores multiview scale coherence. We then integrate pretrained VFM features into the neural volumetric reconstruction pipeline via lightweight task-specific adapters, which are trained for reconstruction while preserving the crossdomain robustness of pretrained representations. We train our model on ScanNet train split and evaluate on both in-distribution ScanNet test split and out-of-distribution TUM RGB-D and Tanks and Temples datasets. The results demonstrate that our model achieves state-of-theart performance across all datasets domains. In particular, on the challenging outdoor Tanks and Temples dataset, our model achieves an F1 score of 70.1 in reconstructed mesh evaluation, substantially outperforming the closest competitor, VGGT, which only attains 51.8.
Brain-HGCN: A Hyperbolic Graph Convolutional Network for Brain Functional Network Analysis
Sep 18, 2025Functional magnetic resonance imaging (fMRI) provides a powerful non-invasive window into the brain's functional organization by generating complex functional networks, typically modeled as graphs. These brain networks exhibit a hierarchical topology that is crucial for cognitive processing. However, due to inherent spatial constraints, standard Euclidean GNNs struggle to represent these hierarchical structures without high distortion, limiting their clinical performance. To address this limitation, we propose Brain-HGCN, a geometric deep learning framework based on hyperbolic geometry, which leverages the intrinsic property of negatively curved space to model the brain's network hierarchy with high fidelity. Grounded in the Lorentz model, our model employs a novel hyperbolic graph attention layer with a signed aggregation mechanism to distinctly process excitatory and inhibitory connections, ultimately learning robust graph-level representations via a geometrically sound Fr\'echet mean for graph readout. Experiments on two large-scale fMRI datasets for psychiatric disorder classification demonstrate that our approach significantly outperforms a wide range of state-of-the-art Euclidean baselines. This work pioneers a new geometric deep learning paradigm for fMRI analysis, highlighting the immense potential of hyperbolic GNNs in the field of computational psychiatry.
Towards Practical Alzheimer's Disease Diagnosis: A Lightweight and Interpretable Spiking Neural Model
Jun 11, 2025Early diagnosis of Alzheimer's Disease (AD), especially at the mild cognitive impairment (MCI) stage, is vital yet hindered by subjective assessments and the high cost of multimodal imaging modalities. Although deep learning methods offer automated alternatives, their energy inefficiency and computational demands limit real-world deployment, particularly in resource-constrained settings. As a brain-inspired paradigm, spiking neural networks (SNNs) are inherently well-suited for modeling the sparse, event-driven patterns of neural degeneration in AD, offering a promising foundation for interpretable and low-power medical diagnostics. However, existing SNNs often suffer from weak expressiveness and unstable training, which restrict their effectiveness in complex medical tasks. To address these limitations, we propose FasterSNN, a hybrid neural architecture that integrates biologically inspired LIF neurons with region-adaptive convolution and multi-scale spiking attention. This design enables sparse, efficient processing of 3D MRI while preserving diagnostic accuracy. Experiments on benchmark datasets demonstrate that FasterSNN achieves competitive performance with substantially improved efficiency and stability, supporting its potential for practical AD screening. Our source code is available at https://github.com/wuchangw/FasterSNN.
Uncertainty Aware Human-machine Collaboration in Camouflaged Object Detection
Feb 12, 2025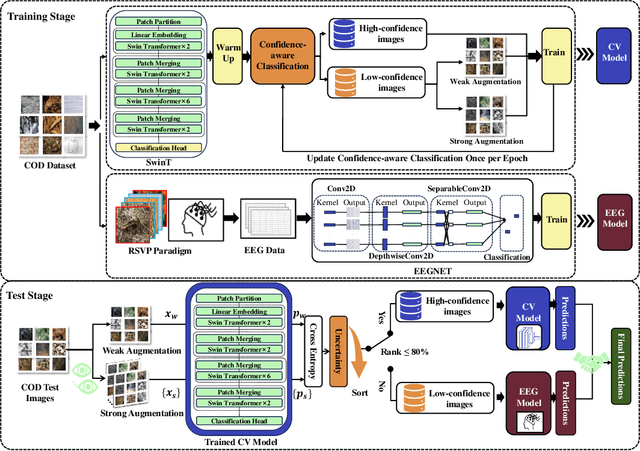
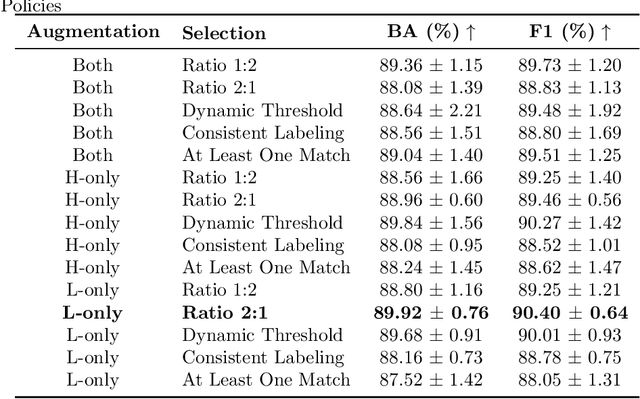
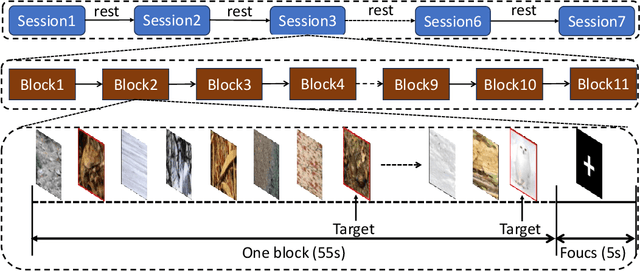
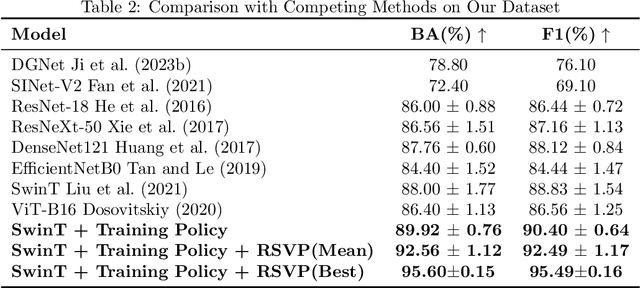
Camouflaged Object Detection (COD), the task of identifying objects concealed within their environments, has seen rapid growth due to its wide range of practical applications. A key step toward developing trustworthy COD systems is the estimation and effective utilization of uncertainty. In this work, we propose a human-machine collaboration framework for classifying the presence of camouflaged objects, leveraging the complementary strengths of computer vision (CV) models and noninvasive brain-computer interfaces (BCIs). Our approach introduces a multiview backbone to estimate uncertainty in CV model predictions, utilizes this uncertainty during training to improve efficiency, and defers low-confidence cases to human evaluation via RSVP-based BCIs during testing for more reliable decision-making. We evaluated the framework in the CAMO dataset, achieving state-of-the-art results with an average improvement of 4.56\% in balanced accuracy (BA) and 3.66\% in the F1 score compared to existing methods. For the best-performing participants, the improvements reached 7.6\% in BA and 6.66\% in the F1 score. Analysis of the training process revealed a strong correlation between our confidence measures and precision, while an ablation study confirmed the effectiveness of the proposed training policy and the human-machine collaboration strategy. In general, this work reduces human cognitive load, improves system reliability, and provides a strong foundation for advancements in real-world COD applications and human-computer interaction. Our code and data are available at: https://github.com/ziyuey/Uncertainty-aware-human-machine-collaboration-in-camouflaged-object-identification.
Toward Robust Early Detection of Alzheimer's Disease via an Integrated Multimodal Learning Approach
Aug 29, 2024


Alzheimer's Disease (AD) is a complex neurodegenerative disorder marked by memory loss, executive dysfunction, and personality changes. Early diagnosis is challenging due to subtle symptoms and varied presentations, often leading to misdiagnosis with traditional unimodal diagnostic methods due to their limited scope. This study introduces an advanced multimodal classification model that integrates clinical, cognitive, neuroimaging, and EEG data to enhance diagnostic accuracy. The model incorporates a feature tagger with a tabular data coding architecture and utilizes the TimesBlock module to capture intricate temporal patterns in Electroencephalograms (EEG) data. By employing Cross-modal Attention Aggregation module, the model effectively fuses Magnetic Resonance Imaging (MRI) spatial information with EEG temporal data, significantly improving the distinction between AD, Mild Cognitive Impairment, and Normal Cognition. Simultaneously, we have constructed the first AD classification dataset that includes three modalities: EEG, MRI, and tabular data. Our innovative approach aims to facilitate early diagnosis and intervention, potentially slowing the progression of AD. The source code and our private ADMC dataset are available at https://github.com/JustlfC03/MSTNet.
VIPeR: Visual Incremental Place Recognition with Adaptive Mining and Lifelong Learning
Jul 31, 2024Visual place recognition (VPR) is an essential component of many autonomous and augmented/virtual reality systems. It enables the systems to robustly localize themselves in large-scale environments. Existing VPR methods demonstrate attractive performance at the cost of heavy pre-training and limited generalizability. When deployed in unseen environments, these methods exhibit significant performance drops. Targeting this issue, we present VIPeR, a novel approach for visual incremental place recognition with the ability to adapt to new environments while retaining the performance of previous environments. We first introduce an adaptive mining strategy that balances the performance within a single environment and the generalizability across multiple environments. Then, to prevent catastrophic forgetting in lifelong learning, we draw inspiration from human memory systems and design a novel memory bank for our VIPeR. Our memory bank contains a sensory memory, a working memory and a long-term memory, with the first two focusing on the current environment and the last one for all previously visited environments. Additionally, we propose a probabilistic knowledge distillation to explicitly safeguard the previously learned knowledge. We evaluate our proposed VIPeR on three large-scale datasets, namely Oxford Robotcar, Nordland, and TartanAir. For comparison, we first set a baseline performance with naive finetuning. Then, several more recent lifelong learning methods are compared. Our VIPeR achieves better performance in almost all aspects with the biggest improvement of 13.65% in average performance.
A high-performance reconstruction method for partially coherent ptychography
Jun 09, 2024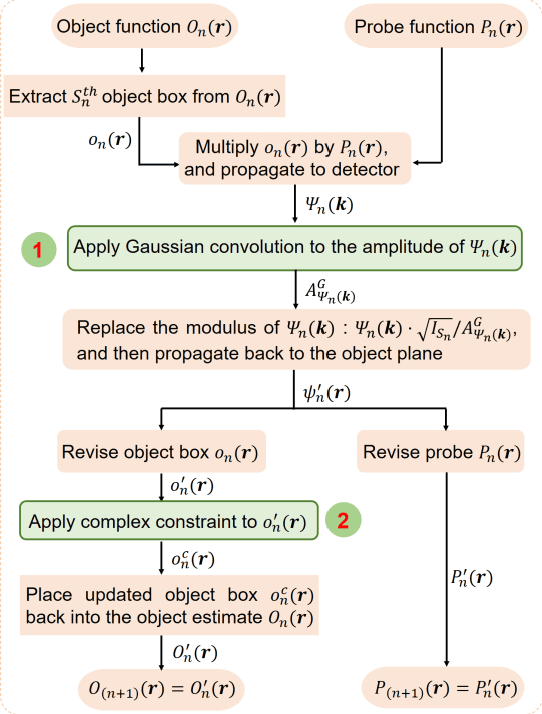
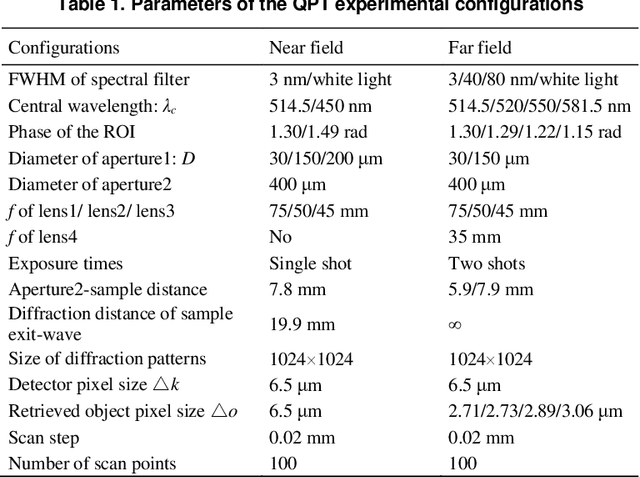

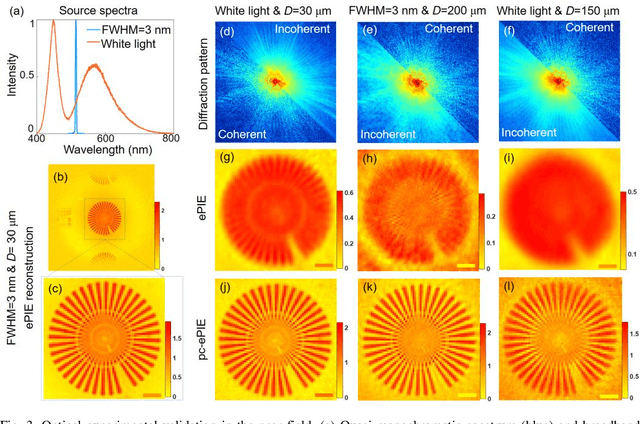
Ptychography is now integrated as a tool in mainstream microscopy allowing quantitative and high-resolution imaging capabilities over a wide field of view. However, its ultimate performance is inevitably limited by the available coherent flux when implemented using electrons or laboratory X-ray sources. We present a universal reconstruction algorithm with high tolerance to low coherence for both far-field and near-field ptychography. The approach is practical for partial temporal and spatial coherence and requires no prior knowledge of the source properties. Our initial visible-light and electron data show that the method can dramatically improve the reconstruction quality and accelerate the convergence rate of the reconstruction. The approach also integrates well into existing ptychographic engines. It can also improve mixed-state and numerical monochromatisation methods, requiring a smaller number of coherent modes or lower dimensionality of Krylov subspace while providing more stable and faster convergence. We propose that this approach could have significant impact on ptychography of weakly scattering samples.
GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
May 17, 2024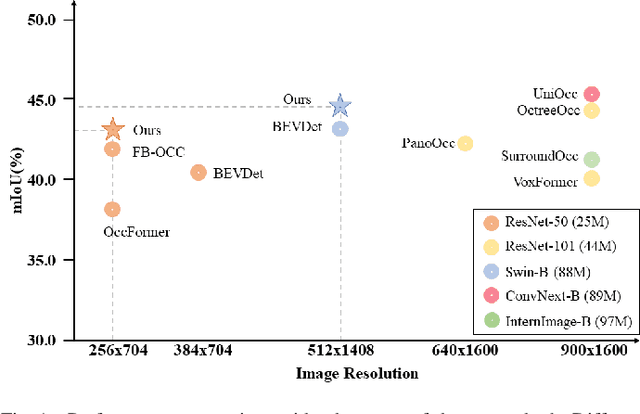



3D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
VQ-NeRV: A Vector Quantized Neural Representation for Videos
Mar 19, 2024



Implicit neural representations (INR) excel in encoding videos within neural networks, showcasing promise in computer vision tasks like video compression and denoising. INR-based approaches reconstruct video frames from content-agnostic embeddings, which hampers their efficacy in video frame regression and restricts their generalization ability for video interpolation. To address these deficiencies, Hybrid Neural Representation for Videos (HNeRV) was introduced with content-adaptive embeddings. Nevertheless, HNeRV's compression ratios remain relatively low, attributable to an oversight in leveraging the network's shallow features and inter-frame residual information. In this work, we introduce an advanced U-shaped architecture, Vector Quantized-NeRV (VQ-NeRV), which integrates a novel component--the VQ-NeRV Block. This block incorporates a codebook mechanism to discretize the network's shallow residual features and inter-frame residual information effectively. This approach proves particularly advantageous in video compression, as it results in smaller size compared to quantized features. Furthermore, we introduce an original codebook optimization technique, termed shallow codebook optimization, designed to refine the utility and efficiency of the codebook. The experimental evaluations indicate that VQ-NeRV outperforms HNeRV on video regression tasks, delivering superior reconstruction quality (with an increase of 1-2 dB in Peak Signal-to-Noise Ratio (PSNR)), better bit per pixel (bpp) efficiency, and improved video inpainting outcomes.
LKFormer: Large Kernel Transformer for Infrared Image Super-Resolution
Jan 24, 2024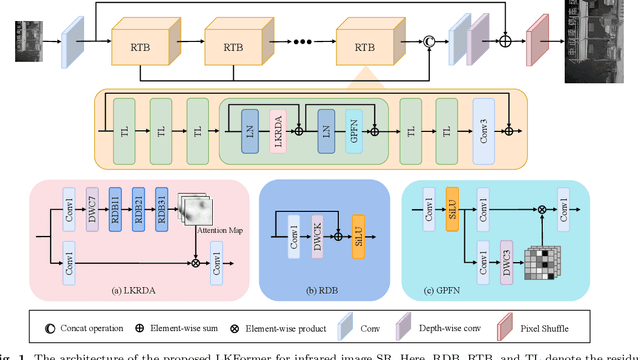
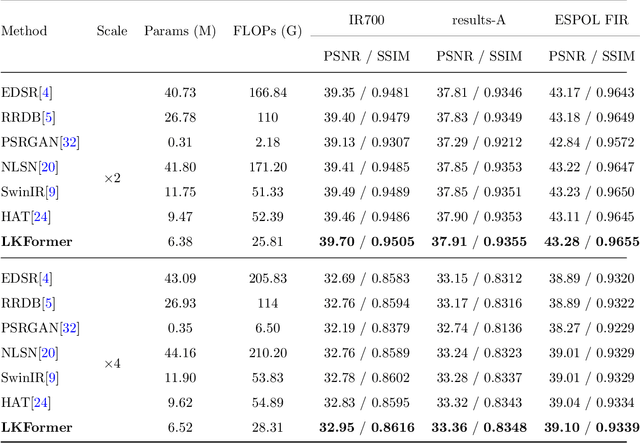


Given the broad application of infrared technology across diverse fields, there is an increasing emphasis on investigating super-resolution techniques for infrared images within the realm of deep learning. Despite the impressive results of current Transformer-based methods in image super-resolution tasks, their reliance on the self-attentive mechanism intrinsic to the Transformer architecture results in images being treated as one-dimensional sequences, thereby neglecting their inherent two-dimensional structure. Moreover, infrared images exhibit a uniform pixel distribution and a limited gradient range, posing challenges for the model to capture effective feature information. Consequently, we suggest a potent Transformer model, termed Large Kernel Transformer (LKFormer), to address this issue. Specifically, we have designed a Large Kernel Residual Attention (LKRA) module with linear complexity. This mainly employs depth-wise convolution with large kernels to execute non-local feature modeling, thereby substituting the standard self-attentive layer. Additionally, we have devised a novel feed-forward network structure called Gated-Pixel Feed-Forward Network (GPFN) to augment the LKFormer's capacity to manage the information flow within the network. Comprehensive experimental results reveal that our method surpasses the most advanced techniques available, using fewer parameters and yielding considerably superior performance.The source code will be available at https://github.com/sad192/large-kernel-Transformer.