 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAME: A Trustworthy Test-Time Evolution of Agent Memory with Systematic Benchmarking
Feb 03, 2026Test-time evolution of agent memory serves as a pivotal paradigm for achieving AGI by bolstering complex reasoning through experience accumulation. However, even during benign task evolution, agent safety alignment remains vulnerable-a phenomenon known as Agent Memory Misevolution. To evaluate this phenomenon, we construct the Trust-Memevo benchmark to assess multi-dimensional trustworthiness during benign task evolution, revealing an overall decline in trustworthiness across various task domains and evaluation settings. To address this issue, we propose TAME, a dual-memory evolutionary framework that separately evolves executor memory to improve task performance by distilling generalizable methodologies, and evaluator memory to refine assessments of both safety and task utility based on historical feedback. Through a closed loop of memory filtering, draft generation, trustworthy refinement, execution, and dual-track memory updating, TAME preserves trustworthiness without sacrificing utility. Experiments demonstrate that TAME mitigates misevolution, achieving a joint improvement in both trustworthiness and task performance.
EscherVerse: An Open World Benchmark and Dataset for Teleo-Spatial Intelligence with Physical-Dynamic and Intent-Driven Understanding
Jan 04, 2026The ability to reason about spatial dynamics is a cornerstone of intelligence, yet current research overlooks the human intent behind spatial changes. To address these limitations, we introduce Teleo-Spatial Intelligence (TSI), a new paradigm that unifies two critical pillars: Physical-Dynamic Reasoning--understanding the physical principles of object interactions--and Intent-Driven Reasoning--inferring the human goals behind these actions. To catalyze research in TSI, we present EscherVerse, consisting of a large-scale, open-world benchmark (Escher-Bench), a dataset (Escher-35k), and models (Escher series). Derived from real-world videos, EscherVerse moves beyond constrained settings to explicitly evaluate an agent's ability to reason about object permanence, state transitions, and trajectory prediction in dynamic, human-centric scenarios. Crucially, it is the first benchmark to systematically assess Intent-Driven Reasoning, challenging models to connect physical events to their underlying human purposes. Our work, including a novel data curation pipeline, provides a foundational resource to advance spatial intelligence from passive scene description toward a holistic, purpose-driven understanding of the world.
Robust and Secure Transmission for Movable-RIS Assisted ISAC with Imperfect Sense Estimation
Dec 23, 2025Reconfigurable intelligent surfaces (RISs) have been extensively applied in integrated sensing and communication (ISAC) systems due to the capability of enhancing physical layer security (PLS). However, conventional static RIS architectures lack the flexibility required for adaptive beam control in multi-user and multifunctional scenarios. To address this issue without introducing additional hardware complexity and power consumption, in this paper, we exploit a movable RIS (MRIS) architecture, which consists of a large fixed sub-surface and a smaller movable sub-surface that slides on the fixed sub-surface to achieve dynamic beam reconfiguration with static phase shifts. This paper investigates an MRIS-assisted ISAC system under imperfect sensing estimation, where dedicated radar signals serve as artificial noise to enhance secure transmission against potential eavesdroppers (Eves). The transmit beamforming vectors, MRIS phase shifts, and relative positions of the two sub-surfaces are jointly optimized to maximize the minimum secrecy rate, ensuring robust secrecy performance for the weakest user under the uncertainty of the Eves' channels. To handle the non-convexity, a convex bound is derived for the Eve channel uncertainty, and the S-procedure is employed to reformulate semi-infinite constraints as linear matrix inequalities. An efficient alternating optimization and penalty dual decomposition-based algorithm is developed. Simulation results demonstrate that the proposed MRIS architecture substantially improves secrecy performance, especially when only a small number of elements are allocated to the movable sub-surface.
Switchable Token-Specific Codebook Quantization For Face Image Compression
Oct 27, 2025With the ever-increasing volume of visual data, the efficient and lossless transmission, along with its subsequent interpretation and understanding, has become a critical bottleneck in modern information systems. The emerged codebook-based solution utilize a globally shared codebook to quantize and dequantize each token, controlling the bpp by adjusting the number of tokens or the codebook size. However, for facial images, which are rich in attributes, such global codebook strategies overlook both the category-specific correlations within images and the semantic differences among tokens, resulting in suboptimal performance, especially at low bpp. Motivated by these observations, we propose a Switchable Token-Specific Codebook Quantization for face image compression, which learns distinct codebook groups for different image categories and assigns an independent codebook to each token. By recording the codebook group to which each token belongs with a small number of bits, our method can reduce the loss incurred when decreasing the size of each codebook group. This enables a larger total number of codebooks under a lower overall bpp, thereby enhancing the expressive capability and improving reconstruction performance. Owing to its generalizable design, our method can be integrated into any existing codebook-based representation learning approach and has demonstrated its effectiveness on face recognition datasets, achieving an average accuracy of 93.51% for reconstructed images at 0.05 bpp.
DORAEMON: Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation
May 29, 2025Adaptive navigation in unfamiliar environments is crucial for household service robots but remains challenging due to the need for both low-level path planning and high-level scene understanding. While recent vision-language model (VLM) based zero-shot approaches reduce dependence on prior maps and scene-specific training data, they face significant limitations: spatiotemporal discontinuity from discrete observations, unstructured memory representations, and insufficient task understanding leading to navigation failures. We propose DORAEMON (Decentralized Ontology-aware Reliable Agent with Enhanced Memory Oriented Navigation), a novel cognitive-inspired framework consisting of Ventral and Dorsal Streams that mimics human navigation capabilities. The Dorsal Stream implements the Hierarchical Semantic-Spatial Fusion and Topology Map to handle spatiotemporal discontinuities, while the Ventral Stream combines RAG-VLM and Policy-VLM to improve decision-making. Our approach also develops Nav-Ensurance to ensure navigation safety and efficiency. We evaluate DORAEMON on the HM3D, MP3D, and GOAT datasets, where it achieves state-of-the-art performance on both success rate (SR) and success weighted by path length (SPL) metrics, significantly outperforming existing methods. We also introduce a new evaluation metric (AORI) to assess navigation intelligence better. Comprehensive experiments demonstrate DORAEMON's effectiveness in zero-shot autonomous navigation without requiring prior map building or pre-training.
Hydra-MDP++: Advancing End-to-End Driving via Expert-Guided Hydra-Distillation
Mar 17, 2025Hydra-MDP++ introduces a novel teacher-student knowledge distillation framework with a multi-head decoder that learns from human demonstrations and rule-based experts. Using a lightweight ResNet-34 network without complex components, the framework incorporates expanded evaluation metrics, including traffic light compliance (TL), lane-keeping ability (LK), and extended comfort (EC) to address unsafe behaviors not captured by traditional NAVSIM-derived teachers. Like other end-to-end autonomous driving approaches, \hydra processes raw images directly without relying on privileged perception signals. Hydra-MDP++ achieves state-of-the-art performance by integrating these components with a 91.0% drive score on NAVSIM through scaling to a V2-99 image encoder, demonstrating its effectiveness in handling diverse driving scenarios while maintaining computational efficiency.
One-for-More: Continual Diffusion Model for Anomaly Detection
Feb 27, 2025With the rise of generative models, there is a growing interest in unifying all tasks within a generative framework. Anomaly detection methods also fall into this scope and utilize diffusion models to generate or reconstruct normal samples when given arbitrary anomaly images. However, our study found that the diffusion model suffers from severe ``faithfulness hallucination'' and ``catastrophic forgetting'', which can't meet the unpredictable pattern increments. To mitigate the above problems, we propose a continual diffusion model that uses gradient projection to achieve stable continual learning. Gradient projection deploys a regularization on the model updating by modifying the gradient towards the direction protecting the learned knowledge. But as a double-edged sword, it also requires huge memory costs brought by the Markov process. Hence, we propose an iterative singular value decomposition method based on the transitive property of linear representation, which consumes tiny memory and incurs almost no performance loss. Finally, considering the risk of ``over-fitting'' to normal images of the diffusion model, we propose an anomaly-masked network to enhance the condition mechanism of the diffusion model. For continual anomaly detection, ours achieves first place in 17/18 settings on MVTec and VisA. Code is available at https://github.com/FuNz-0/One-for-More
Diffusion Implicit Policy for Unpaired Scene-aware Motion Synthesis
Dec 03, 2024
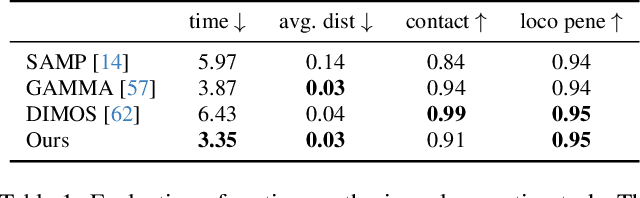


Human motion generation is a long-standing problem, and scene-aware motion synthesis has been widely researched recently due to its numerous applications. Prevailing methods rely heavily on paired motion-scene data whose quantity is limited. Meanwhile, it is difficult to generalize to diverse scenes when trained only on a few specific ones. Thus, we propose a unified framework, termed Diffusion Implicit Policy (DIP), for scene-aware motion synthesis, where paired motion-scene data are no longer necessary. In this framework, we disentangle human-scene interaction from motion synthesis during training and then introduce an interaction-based implicit policy into motion diffusion during inference. Synthesized motion can be derived through iterative diffusion denoising and implicit policy optimization, thus motion naturalness and interaction plausibility can be maintained simultaneously. The proposed implicit policy optimizes the intermediate noised motion in a GAN Inversion manner to maintain motion continuity and control keyframe poses though the ControlNet branch and motion inpainting. For long-term motion synthesis, we introduce motion blending for stable transitions between multiple sub-tasks, where motions are fused in rotation power space and translation linear space. The proposed method is evaluated on synthesized scenes with ShapeNet furniture, and real scenes from PROX and Replica. Results show that our framework presents better motion naturalness and interaction plausibility than cutting-edge methods. This also indicates the feasibility of utilizing the DIP for motion synthesis in more general tasks and versatile scenes. https://jingyugong.github.io/DiffusionImplicitPolicy/
LLaCA: Multimodal Large Language Continual Assistant
Oct 08, 2024Instruction tuning guides the Multimodal Large Language Models (MLLMs) in aligning different modalities by designing text instructions, which seems to be an essential technique to enhance the capabilities and controllability of foundation models. In this framework, Multimodal Continual Instruction Tuning (MCIT) is adopted to continually instruct MLLMs to follow human intent in sequential datasets. We observe existing gradient update would heavily destroy the tuning performance on previous datasets and the zero-shot ability during continual instruction tuning. Exponential Moving Average (EMA) update policy owns the ability to trace previous parameters, which can aid in decreasing forgetting. However, its stable balance weight cannot deal with the ever-changing datasets, leading to the out-of-balance between plasticity and stability of MLLMs. In this paper, we propose a method called Multimodal Large Language Continual Assistant (LLaCA) to address the challenge. Starting from the trade-off prerequisite and EMA update, we propose the plasticity and stability ideal condition. Based on Taylor expansion in the loss function, we find the optimal balance weight is basically according to the gradient information and previous parameters. We automatically determine the balance weight and significantly improve the performance. Through comprehensive experiments on LLaVA-1.5 in a continual visual-question-answering benchmark, compared with baseline, our approach not only highly improves anti-forgetting ability (with reducing forgetting from 22.67 to 2.68), but also significantly promotes continual tuning performance (with increasing average accuracy from 41.31 to 61.89). Our code will be published soon.
Harmonizing Visual Text Comprehension and Generation
Jul 23, 2024



In this work, we present TextHarmony, a unified and versatile multimodal generative model proficient in comprehending and generating visual text. Simultaneously generating images and texts typically results in performance degradation due to the inherent inconsistency between vision and language modalities. To overcome this challenge, existing approaches resort to modality-specific data for supervised fine-tuning, necessitating distinct model instances. We propose Slide-LoRA, which dynamically aggregates modality-specific and modality-agnostic LoRA experts, partially decoupling the multimodal generation space. Slide-LoRA harmonizes the generation of vision and language within a singular model instance, thereby facilitating a more unified generative process. Additionally, we develop a high-quality image caption dataset, DetailedTextCaps-100K, synthesized with a sophisticated closed-source MLLM to enhance visual text generation capabilities further. Comprehensive experiments across various benchmarks demonstrate the effectiveness of the proposed approach. Empowered by Slide-LoRA, TextHarmony achieves comparable performance to modality-specific fine-tuning results with only a 2% increase in parameters and shows an average improvement of 2.5% in visual text comprehension tasks and 4.0% in visual text generation tasks. Our work delineates the viability of an integrated approach to multimodal generation within the visual text domain, setting a foundation for subsequent inquiries.