 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured interactions improve distributed coordination beyond model scaling in a real-world multi-robot system
May 28, 2026Scaling individual robot capabilities is common but costly. Here we investigate a system-level design question in real-world multi-robot coordination: given matched hardware budgets, does restructuring communication among robots yield larger gains than increasing onboard model size? Using a representative transport-and-mapping task with 10 physical robots (5 runs per condition, 60 runs total), we find that switching from fully connected to modular hierarchical interactions improves normalised performance by 47 points (0--100), whereas doubling neural network hidden size yields at most 9 points. Nested mixed-effects model comparisons show a substantially larger improvement in model fit for topology than for scale. The pattern is confirmed in independent SMAC replications; heterogeneous benchmark reanalyses provide secondary supporting consistency checks rather than primary evidence. Performance saturation beyond 1024 hidden units is observed in simulation-calibrated extrapolation, not directly on hardware. These results indicate that interaction structure can play a dominant role within the tested system and task setting, while broader quantitative generalisation remains to be established.
Mutual Information Guided Optimal Transport for Unsupervised Visible-Infrared Person Re-identification
Jul 17, 2024



Unsupervised visible infrared person re-identification (USVI-ReID) is a challenging retrieval task that aims to retrieve cross-modality pedestrian images without using any label information. In this task, the large cross-modality variance makes it difficult to generate reliable cross-modality labels, and the lack of annotations also provides additional difficulties for learning modality-invariant features. In this paper, we first deduce an optimization objective for unsupervised VI-ReID based on the mutual information between the model's cross-modality input and output. With equivalent derivation, three learning principles, i.e., "Sharpness" (entropy minimization), "Fairness" (uniform label distribution), and "Fitness" (reliable cross-modality matching) are obtained. Under their guidance, we design a loop iterative training strategy alternating between model training and cross-modality matching. In the matching stage, a uniform prior guided optimal transport assignment ("Fitness", "Fairness") is proposed to select matched visible and infrared prototypes. In the training stage, we utilize this matching information to introduce prototype-based contrastive learning for minimizing the intra- and cross-modality entropy ("Sharpness"). Extensive experimental results on benchmarks demonstrate the effectiveness of our method, e.g., 60.6% and 90.3% of Rank-1 accuracy on SYSU-MM01 and RegDB without any annotations.
EMIE-MAP: Large-Scale Road Surface Reconstruction Based on Explicit Mesh and Implicit Encoding
Mar 18, 2024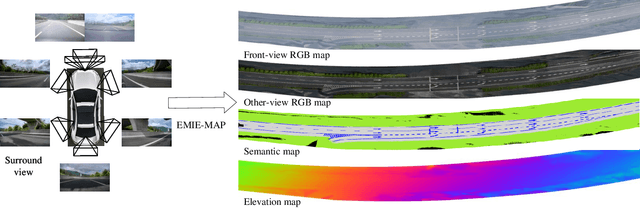

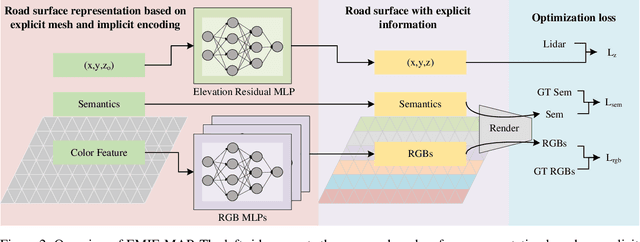

Road surface reconstruction plays a vital role in autonomous driving systems, enabling road lane perception and high-precision mapping. Recently, neural implicit encoding has achieved remarkable results in scene representation, particularly in the realistic rendering of scene textures. However, it faces challenges in directly representing geometric information for large-scale scenes. To address this, we propose EMIE-MAP, a novel method for large-scale road surface reconstruction based on explicit mesh and implicit encoding. The road geometry is represented using explicit mesh, where each vertex stores implicit encoding representing the color and semantic information. To overcome the difficulty in optimizing road elevation, we introduce a trajectory-based elevation initialization and an elevation residual learning method based on Multi-Layer Perceptron (MLP). Additionally, by employing implicit encoding and multi-camera color MLPs decoding, we achieve separate modeling of scene physical properties and camera characteristics, allowing surround-view reconstruction compatible with different camera models. Our method achieves remarkable road surface reconstruction performance in a variety of real-world challenging scenarios.
Constrained Maximum Cross-Domain Likelihood for Domain Generalization
Oct 09, 2022
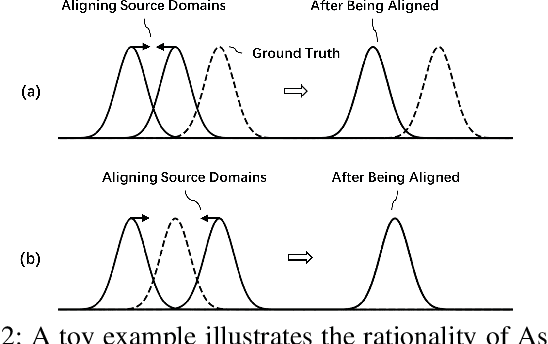
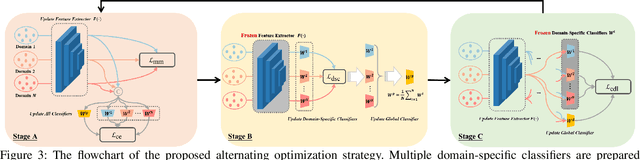
As a recent noticeable topic, domain generalization aims to learn a generalizable model on multiple source domains, which is expected to perform well on unseen test domains. Great efforts have been made to learn domain-invariant features by aligning distributions across domains. However, existing works are often designed based on some relaxed conditions which are generally hard to satisfy and fail to realize the desired joint distribution alignment. In this paper, we propose a novel domain generalization method, which originates from an intuitive idea that a domain-invariant classifier can be learned by minimizing the KL-divergence between posterior distributions from different domains. To enhance the generalizability of the learned classifier, we formalize the optimization objective as an expectation computed on the ground-truth marginal distribution. Nevertheless, it also presents two obvious deficiencies, one of which is the side-effect of entropy increase in KL-divergence and the other is the unavailability of ground-truth marginal distributions. For the former, we introduce a term named maximum in-domain likelihood to maintain the discrimination of the learned domain-invariant representation space. For the latter, we approximate the ground-truth marginal distribution with source domains under a reasonable convex hull assumption. Finally, a Constrained Maximum Cross-domain Likelihood (CMCL) optimization problem is deduced, by solving which the joint distributions are naturally aligned. An alternating optimization strategy is carefully designed to approximately solve this optimization problem. Extensive experiments on four standard benchmark datasets, i.e., Digits-DG, PACS, Office-Home and miniDomainNet, highlight the superior performance of our method.
Mitigating Both Covariate and Conditional Shift for Domain Generalization
Sep 17, 2022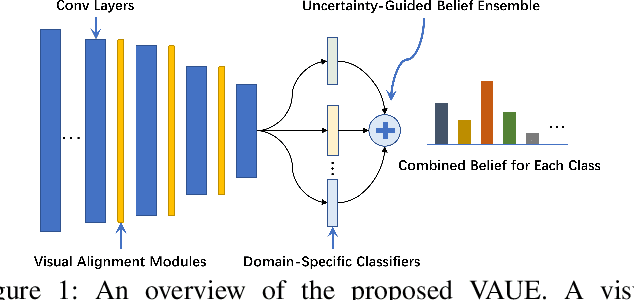
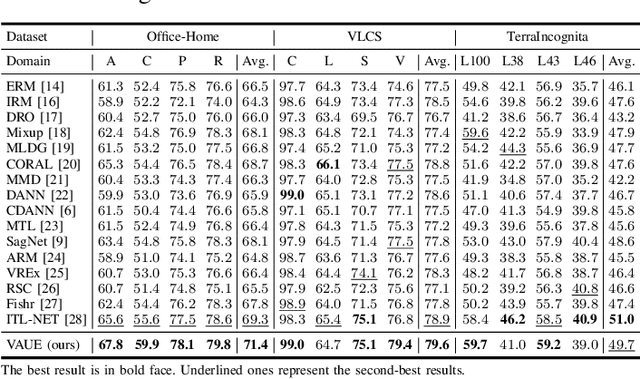
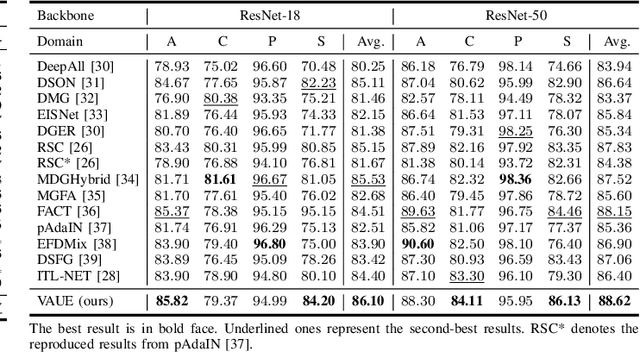
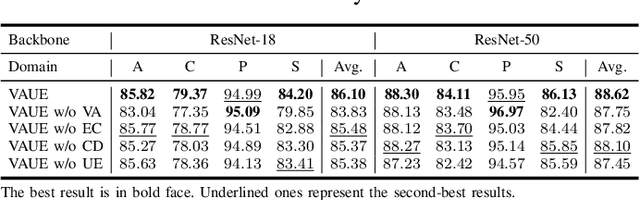
Domain generalization (DG) aims to learn a model on several source domains, hoping that the model can generalize well to unseen target domains. The distribution shift between domains contains the covariate shift and conditional shift, both of which the model must be able to handle for better generalizability. In this paper, a novel DG method is proposed to deal with the distribution shift via Visual Alignment and Uncertainty-guided belief Ensemble (VAUE). Specifically, for the covariate shift, a visual alignment module is designed to align the distribution of image style to a common empirical Gaussian distribution so that the covariate shift can be eliminated in the visual space. For the conditional shift, we adopt an uncertainty-guided belief ensemble strategy based on the subjective logic and Dempster-Shafer theory. The conditional distribution given a test sample is estimated by the dynamic combination of that of source domains. Comprehensive experiments are conducted to demonstrate the superior performance of the proposed method on four widely used datasets, i.e., Office-Home, VLCS, TerraIncognita, and PACS.