 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Maximum Cross-Domain Likelihood for Domain Generalization
Paper and Code
Oct 09, 2022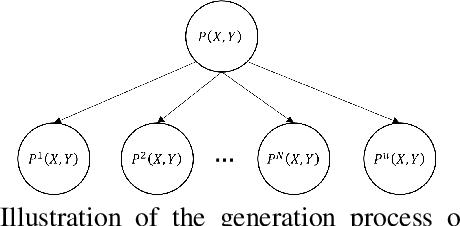
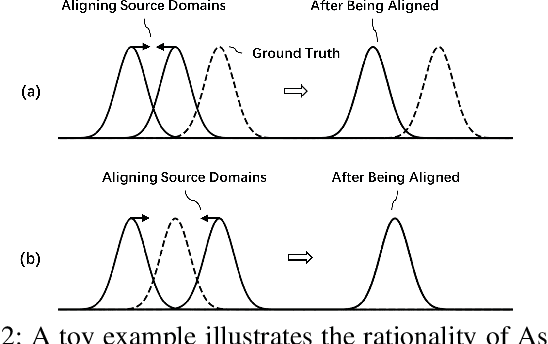
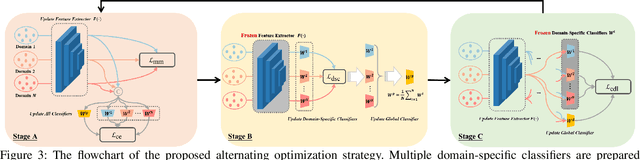
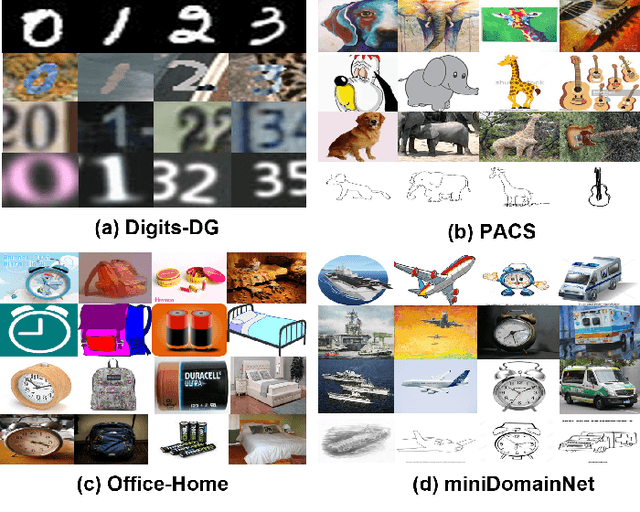
As a recent noticeable topic, domain generalization aims to learn a generalizable model on multiple source domains, which is expected to perform well on unseen test domains. Great efforts have been made to learn domain-invariant features by aligning distributions across domains. However, existing works are often designed based on some relaxed conditions which are generally hard to satisfy and fail to realize the desired joint distribution alignment. In this paper, we propose a novel domain generalization method, which originates from an intuitive idea that a domain-invariant classifier can be learned by minimizing the KL-divergence between posterior distributions from different domains. To enhance the generalizability of the learned classifier, we formalize the optimization objective as an expectation computed on the ground-truth marginal distribution. Nevertheless, it also presents two obvious deficiencies, one of which is the side-effect of entropy increase in KL-divergence and the other is the unavailability of ground-truth marginal distributions. For the former, we introduce a term named maximum in-domain likelihood to maintain the discrimination of the learned domain-invariant representation space. For the latter, we approximate the ground-truth marginal distribution with source domains under a reasonable convex hull assumption. Finally, a Constrained Maximum Cross-domain Likelihood (CMCL) optimization problem is deduced, by solving which the joint distributions are naturally aligned. An alternating optimization strategy is carefully designed to approximately solve this optimization problem. Extensive experiments on four standard benchmark datasets, i.e., Digits-DG, PACS, Office-Home and miniDomainNet, highlight the superior performance of our method.