 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedCausalX: Adaptive Causal Reasoning with Self-Reflection for Trustworthy Medical Vision-Language Models
Mar 24, 2026Vision-Language Models (VLMs) have enabled interpretable medical diagnosis by integrating visual perception with linguistic reasoning. Yet, existing medical chain-of-thought (CoT) models lack explicit mechanisms to represent and enforce causal reasoning, leaving them vulnerable to spurious correlations and limiting their clinical reliability. We pinpoint three core challenges in medical CoT reasoning: how to adaptively trigger causal correction, construct high-quality causal-spurious contrastive samples, and maintain causal consistency across reasoning trajectories. To address these challenges, we propose MedCausalX, an end-to-end framework explicitly models causal reasoning chains in medical VLMs. We first introduce the CRMed dataset providing fine-grained anatomical annotations, structured causal reasoning chains, and counterfactual variants that guide the learning of causal relationships beyond superficial correlations. Building upon CRMed, MedCausalX employs a two-stage adaptive reflection architecture equipped with $\langle$causal$\rangle$ and $\langle$verify$\rangle$ tokens, enabling the model to autonomously determine when and how to perform causal analysis and verification. Finally, a trajectory-level causal correction objective optimized through error-attributed reinforcement learning refines the reasoning chain, allowing the model to distinguish genuine causal dependencies from shortcut associations. Extensive experiments on multiple benchmarks show that MedCausalX consistently outperforms state-of-the-art methods, improving diagnostic consistency by +5.4 points, reducing hallucination by over 10 points, and attaining top spatial grounding IoU, thereby setting a new standard for causally grounded medical reasoning.
Restoring Real-World Images with an Internal Detail Enhancement Diffusion Model
May 24, 2025Restoring real-world degraded images, such as old photographs or low-resolution images, presents a significant challenge due to the complex, mixed degradations they exhibit, such as scratches, color fading, and noise. Recent data-driven approaches have struggled with two main challenges: achieving high-fidelity restoration and providing object-level control over colorization. While diffusion models have shown promise in generating high-quality images with specific controls, they often fail to fully preserve image details during restoration. In this work, we propose an internal detail-preserving diffusion model for high-fidelity restoration of real-world degraded images. Our method utilizes a pre-trained Stable Diffusion model as a generative prior, eliminating the need to train a model from scratch. Central to our approach is the Internal Image Detail Enhancement (IIDE) technique, which directs the diffusion model to preserve essential structural and textural information while mitigating degradation effects. The process starts by mapping the input image into a latent space, where we inject the diffusion denoising process with degradation operations that simulate the effects of various degradation factors. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art models in both qualitative assessments and perceptual quantitative evaluations. Additionally, our approach supports text-guided restoration, enabling object-level colorization control that mimics the expertise of professional photo editing.
HR-Extreme: A High-Resolution Dataset for Extreme Weather Forecasting
Sep 27, 2024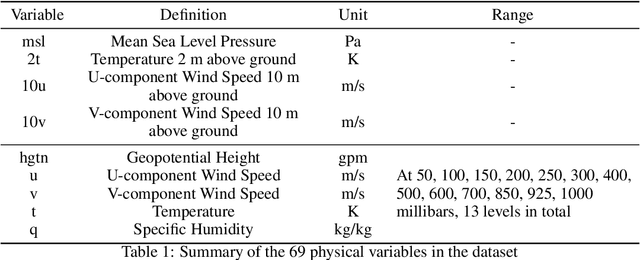


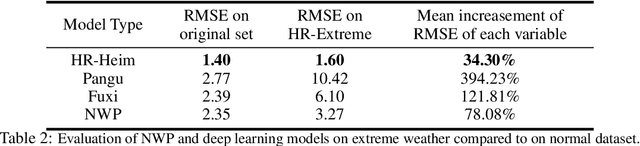
The application of large deep learning models in weather forecasting has led to significant advancements in the field, including higher-resolution forecasting and extended prediction periods exemplified by models such as Pangu and Fuxi. Despite these successes, previous research has largely been characterized by the neglect of extreme weather events, and the availability of datasets specifically curated for such events remains limited. Given the critical importance of accurately forecasting extreme weather, this study introduces a comprehensive dataset that incorporates high-resolution extreme weather cases derived from the High-Resolution Rapid Refresh (HRRR) data, a 3-km real-time dataset provided by NOAA. We also evaluate the current state-of-the-art deep learning models and Numerical Weather Prediction (NWP) systems on HR-Extreme, and provide a improved baseline deep learning model called HR-Heim which has superior performance on both general loss and HR-Extreme compared to others. Our results reveal that the errors of extreme weather cases are significantly larger than overall forecast error, highlighting them as an crucial source of loss in weather prediction. These findings underscore the necessity for future research to focus on improving the accuracy of extreme weather forecasts to enhance their practical utility.
KGExplainer: Towards Exploring Connected Subgraph Explanations for Knowledge Graph Completion
Apr 05, 2024


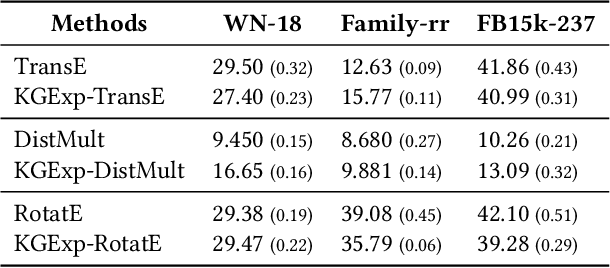
Knowledge graph completion (KGC) aims to alleviate the inherent incompleteness of knowledge graphs (KGs), which is a critical task for various applications, such as recommendations on the web. Although knowledge graph embedding (KGE) models have demonstrated superior predictive performance on KGC tasks, these models infer missing links in a black-box manner that lacks transparency and accountability, preventing researchers from developing accountable models. Existing KGE-based explanation methods focus on exploring key paths or isolated edges as explanations, which is information-less to reason target prediction. Additionally, the missing ground truth leads to these explanation methods being ineffective in quantitatively evaluating explored explanations. To overcome these limitations, we propose KGExplainer, a model-agnostic method that identifies connected subgraph explanations and distills an evaluator to assess them quantitatively. KGExplainer employs a perturbation-based greedy search algorithm to find key connected subgraphs as explanations within the local structure of target predictions. To evaluate the quality of the explored explanations, KGExplainer distills an evaluator from the target KGE model. By forwarding the explanations to the evaluator, our method can examine the fidelity of them. Extensive experiments on benchmark datasets demonstrate that KGExplainer yields promising improvement and achieves an optimal ratio of 83.3% in human evaluation.
Instruction Multi-Constraint Molecular Generation Using a Teacher-Student Large Language Model
Mar 20, 2024While various models and computational tools have been proposed for structure and property analysis of molecules, generating molecules that conform to all desired structures and properties remains a challenge. Here, we introduce a multi-constraint molecular generation large language model, TSMMG, which, akin to a student, incorporates knowledge from various small models and tools, namely, the 'teachers'. To train TSMMG, we construct a large set of text-molecule pairs by extracting molecular knowledge from these 'teachers', enabling it to generate novel molecules that conform to the descriptions through various text prompts. We experimentally show that TSMMG remarkably performs in generating molecules meeting complex, natural language-described property requirements across two-, three-, and four-constraint tasks, with an average molecular validity of over 99% and success ratio of 88.08%, 65.27%, and 61.44%, respectively. The model also exhibits adaptability through zero-shot testing, creating molecules that satisfy combinations of properties that have not been encountered. It can comprehend text inputs with various language styles, extending beyond the confines of outlined prompts, as confirmed through empirical validation. Additionally, the knowledge distillation feature of TSMMG contributes to the continuous enhancement of small models, while the innovative approach to dataset construction effectively addresses the issues of data scarcity and quality, which positions TSMMG as a promising tool in the domains of drug discovery and materials science. Code is available at https://github.com/HHW-zhou/TSMMG.
Breathing Life into Faces: Speech-driven 3D Facial Animation with Natural Head Pose and Detailed Shape
Oct 31, 2023



The creation of lifelike speech-driven 3D facial animation requires a natural and precise synchronization between audio input and facial expressions. However, existing works still fail to render shapes with flexible head poses and natural facial details (e.g., wrinkles). This limitation is mainly due to two aspects: 1) Collecting training set with detailed 3D facial shapes is highly expensive. This scarcity of detailed shape annotations hinders the training of models with expressive facial animation. 2) Compared to mouth movement, the head pose is much less correlated to speech content. Consequently, concurrent modeling of both mouth movement and head pose yields the lack of facial movement controllability. To address these challenges, we introduce VividTalker, a new framework designed to facilitate speech-driven 3D facial animation characterized by flexible head pose and natural facial details. Specifically, we explicitly disentangle facial animation into head pose and mouth movement and encode them separately into discrete latent spaces. Then, these attributes are generated through an autoregressive process leveraging a window-based Transformer architecture. To augment the richness of 3D facial animation, we construct a new 3D dataset with detailed shapes and learn to synthesize facial details in line with speech content. Extensive quantitative and qualitative experiments demonstrate that VividTalker outperforms state-of-the-art methods, resulting in vivid and realistic speech-driven 3D facial animation.
Towards Better Multi-modal Keyphrase Generation via Visual Entity Enhancement and Multi-granularity Image Noise Filtering
Sep 09, 2023
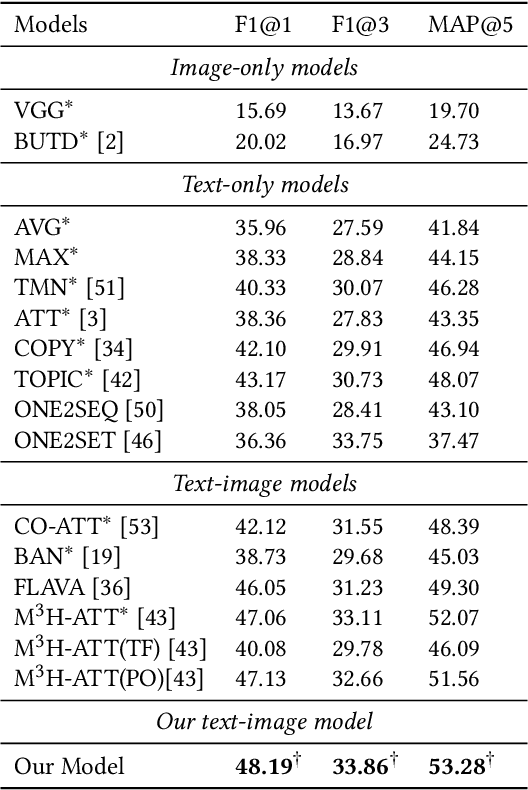
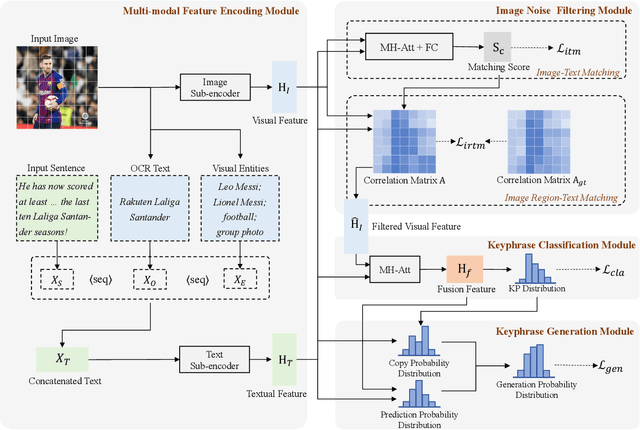
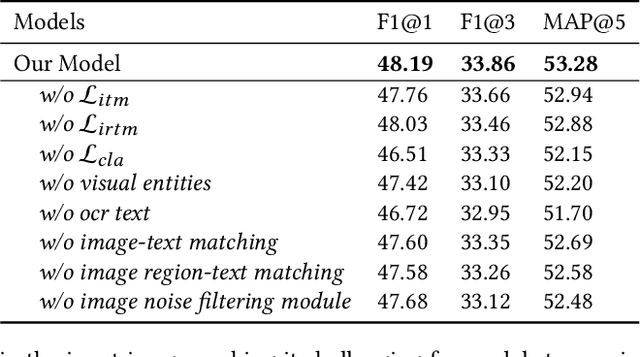
Multi-modal keyphrase generation aims to produce a set of keyphrases that represent the core points of the input text-image pair. In this regard, dominant methods mainly focus on multi-modal fusion for keyphrase generation. Nevertheless, there are still two main drawbacks: 1) only a limited number of sources, such as image captions, can be utilized to provide auxiliary information. However, they may not be sufficient for the subsequent keyphrase generation. 2) the input text and image are often not perfectly matched, and thus the image may introduce noise into the model. To address these limitations, in this paper, we propose a novel multi-modal keyphrase generation model, which not only enriches the model input with external knowledge, but also effectively filters image noise. First, we introduce external visual entities of the image as the supplementary input to the model, which benefits the cross-modal semantic alignment for keyphrase generation. Second, we simultaneously calculate an image-text matching score and image region-text correlation scores to perform multi-granularity image noise filtering. Particularly, we introduce the correlation scores between image regions and ground-truth keyphrases to refine the calculation of the previously-mentioned correlation scores. To demonstrate the effectiveness of our model, we conduct several groups of experiments on the benchmark dataset. Experimental results and in-depth analyses show that our model achieves the state-of-the-art performance. Our code is available on https://github.com/DeepLearnXMU/MM-MKP.
DiffColor: Toward High Fidelity Text-Guided Image Colorization with Diffusion Models
Aug 03, 2023



Recent data-driven image colorization methods have enabled automatic or reference-based colorization, while still suffering from unsatisfactory and inaccurate object-level color control. To address these issues, we propose a new method called DiffColor that leverages the power of pre-trained diffusion models to recover vivid colors conditioned on a prompt text, without any additional inputs. DiffColor mainly contains two stages: colorization with generative color prior and in-context controllable colorization. Specifically, we first fine-tune a pre-trained text-to-image model to generate colorized images using a CLIP-based contrastive loss. Then we try to obtain an optimized text embedding aligning the colorized image and the text prompt, and a fine-tuned diffusion model enabling high-quality image reconstruction. Our method can produce vivid and diverse colors with a few iterations, and keep the structure and background intact while having colors well-aligned with the target language guidance. Moreover, our method allows for in-context colorization, i.e., producing different colorization results by modifying prompt texts without any fine-tuning, and can achieve object-level controllable colorization results. Extensive experiments and user studies demonstrate that DiffColor outperforms previous works in terms of visual quality, color fidelity, and diversity of colorization options.
EMoG: Synthesizing Emotive Co-speech 3D Gesture with Diffusion Model
Jun 20, 2023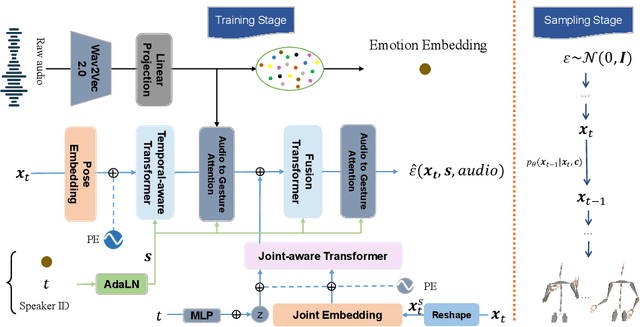
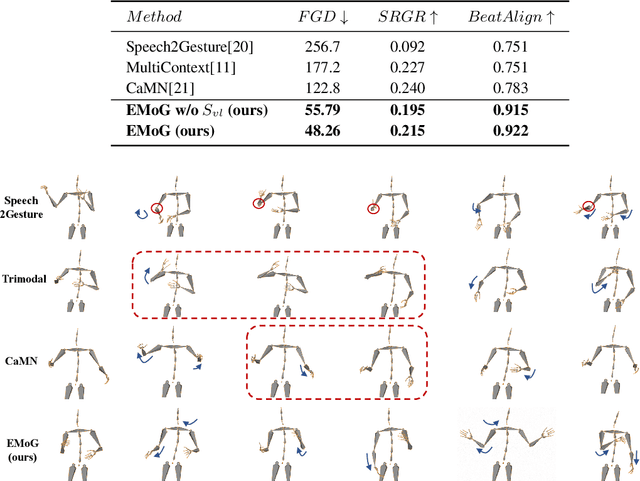
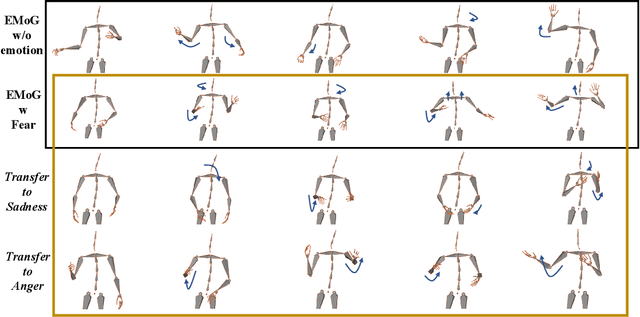
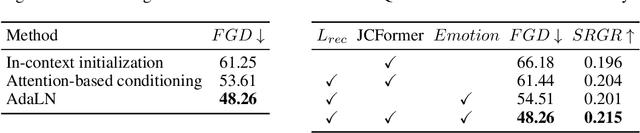
Although previous co-speech gesture generation methods are able to synthesize motions in line with speech content, it is still not enough to handle diverse and complicated motion distribution. The key challenges are: 1) the one-to-many nature between the speech content and gestures; 2) the correlation modeling between the body joints. In this paper, we present a novel framework (EMoG) to tackle the above challenges with denoising diffusion models: 1) To alleviate the one-to-many problem, we incorporate emotion clues to guide the generation process, making the generation much easier; 2) To model joint correlation, we propose to decompose the difficult gesture generation into two sub-problems: joint correlation modeling and temporal dynamics modeling. Then, the two sub-problems are explicitly tackled with our proposed Joint Correlation-aware transFormer (JCFormer). Through extensive evaluations, we demonstrate that our proposed method surpasses previous state-of-the-art approaches, offering substantial superiority in gesture synthesis.
Constrained Maximum Cross-Domain Likelihood for Domain Generalization
Oct 09, 2022
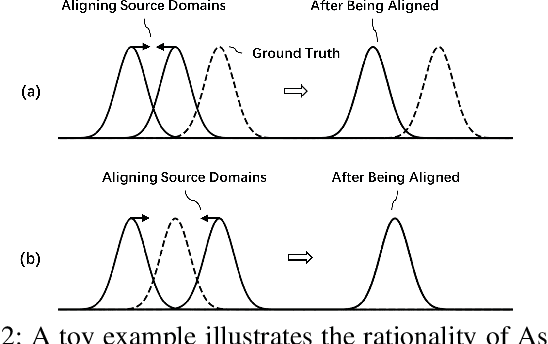
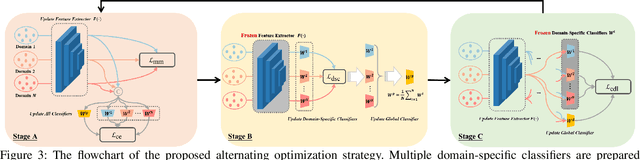
As a recent noticeable topic, domain generalization aims to learn a generalizable model on multiple source domains, which is expected to perform well on unseen test domains. Great efforts have been made to learn domain-invariant features by aligning distributions across domains. However, existing works are often designed based on some relaxed conditions which are generally hard to satisfy and fail to realize the desired joint distribution alignment. In this paper, we propose a novel domain generalization method, which originates from an intuitive idea that a domain-invariant classifier can be learned by minimizing the KL-divergence between posterior distributions from different domains. To enhance the generalizability of the learned classifier, we formalize the optimization objective as an expectation computed on the ground-truth marginal distribution. Nevertheless, it also presents two obvious deficiencies, one of which is the side-effect of entropy increase in KL-divergence and the other is the unavailability of ground-truth marginal distributions. For the former, we introduce a term named maximum in-domain likelihood to maintain the discrimination of the learned domain-invariant representation space. For the latter, we approximate the ground-truth marginal distribution with source domains under a reasonable convex hull assumption. Finally, a Constrained Maximum Cross-domain Likelihood (CMCL) optimization problem is deduced, by solving which the joint distributions are naturally aligned. An alternating optimization strategy is carefully designed to approximately solve this optimization problem. Extensive experiments on four standard benchmark datasets, i.e., Digits-DG, PACS, Office-Home and miniDomainNet, highlight the superior performance of our method.