 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradMAP: Faster Layer Pruning with Gradient Metric and Projection Compensation
Feb 16, 2026Large Language Models (LLMs) exhibit strong reasoning abilities, but their high computational costs limit their practical deployment. Recent studies reveal significant redundancy in LLMs layers, making layer pruning an active research topic. Layer pruning research primarily focuses on two aspects: measuring layer importance and recovering performance after pruning. Unfortunately, the present works fail to simultaneously maintain pruning performance and efficiency. In this study, we propose GradMAP, a faster layer pruning method with \textbf{Grad}ient \textbf{M}etric \textbf{A}nd \textbf{P}rojection compensation, which consists of two stages. In the first stage, we introduce a novel metric based on gradient magnitudes, enabling a global assessment of layer importance. Note that, it requires only a single backward propagation step per pruning decision, substantially enhancing pruning efficiency. In the second stage, we first analyze the layers with the largest mean shift resulting from pruning, and then incorporate a simple yet effective projection compensation matrix to correct this drift in one step. In this way, the degradation of model performance caused by layer pruning is effectively alleviated. Extensive experiments show that GradMAP outperforms previous layer pruning methods in both pruning speed (achieving an average $4\times$ speedup) and performance.
AdaptGCD: Multi-Expert Adapter Tuning for Generalized Category Discovery
Oct 29, 2024Different from the traditional semi-supervised learning paradigm that is constrained by the close-world assumption, Generalized Category Discovery (GCD) presumes that the unlabeled dataset contains new categories not appearing in the labeled set, and aims to not only classify old categories but also discover new categories in the unlabeled data. Existing studies on GCD typically devote to transferring the general knowledge from the self-supervised pretrained model to the target GCD task via some fine-tuning strategies, such as partial tuning and prompt learning. Nevertheless, these fine-tuning methods fail to make a sound balance between the generalization capacity of pretrained backbone and the adaptability to the GCD task. To fill this gap, in this paper, we propose a novel adapter-tuning-based method named AdaptGCD, which is the first work to introduce the adapter tuning into the GCD task and provides some key insights expected to enlighten future research. Furthermore, considering the discrepancy of supervision information between the old and new classes, a multi-expert adapter structure equipped with a route assignment constraint is elaborately devised, such that the data from old and new classes are separated into different expert groups. Extensive experiments are conducted on 7 widely-used datasets. The remarkable improvements in performance highlight the effectiveness of our proposals.
LoRAP: Transformer Sub-Layers Deserve Differentiated Structured Compression for Large Language Models
Apr 15, 2024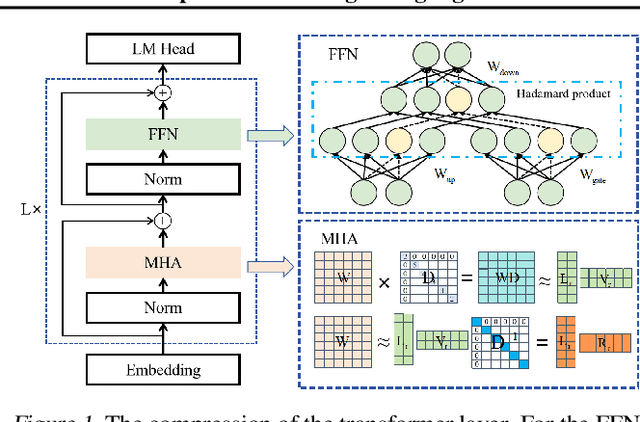



Large language models (LLMs) show excellent performance in difficult tasks, but they often require massive memories and computational resources. How to reduce the parameter scale of LLMs has become research hotspots. In this study, we make an important observation that the multi-head self-attention (MHA) sub-layer of Transformer exhibits noticeable low-rank structure, while the feed-forward network (FFN) sub-layer does not. With this regard, we design a mixed compression model, which organically combines Low-Rank matrix approximation And structured Pruning (LoRAP). For the MHA sub-layer, we propose an input activation weighted singular value decomposition method to strengthen the low-rank characteristic. Furthermore, we discover that the weight matrices in MHA sub-layer have different low-rank degrees. Thus, a novel parameter allocation scheme according to the discrepancy of low-rank degrees is devised. For the FFN sub-layer, we propose a gradient-free structured channel pruning method. During the pruning, we get an interesting finding that the least important 1% of parameter actually play a vital role in model performance. Extensive evaluations on zero-shot perplexity and zero-shot task classification indicate that our proposal is superior to previous structured compression rivals under multiple compression ratios.
Cross-Stream Contrastive Learning for Self-Supervised Skeleton-Based Action Recognition
May 03, 2023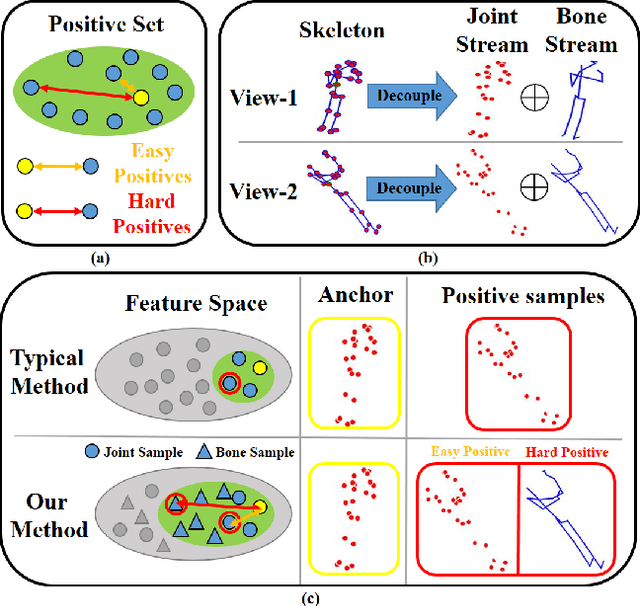
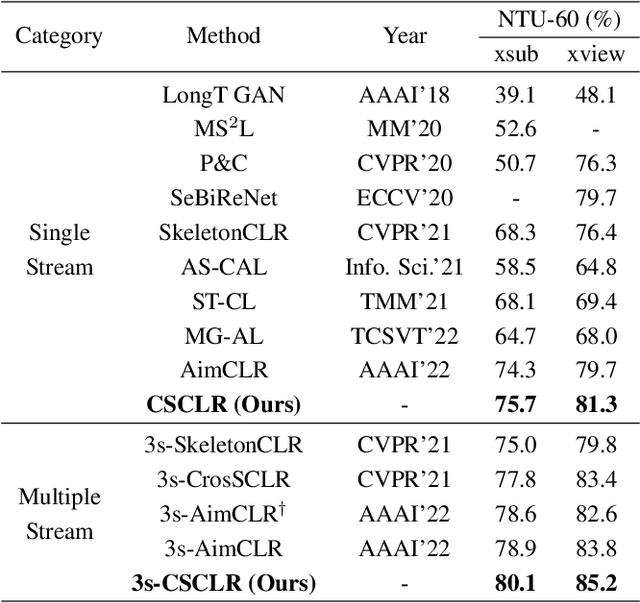
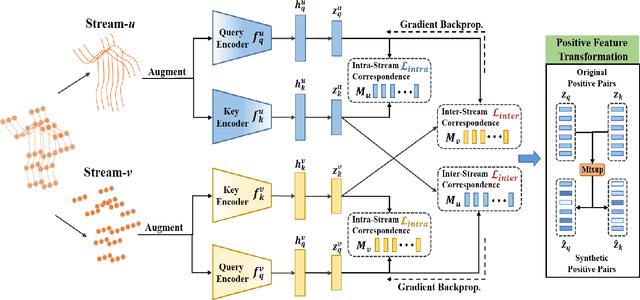
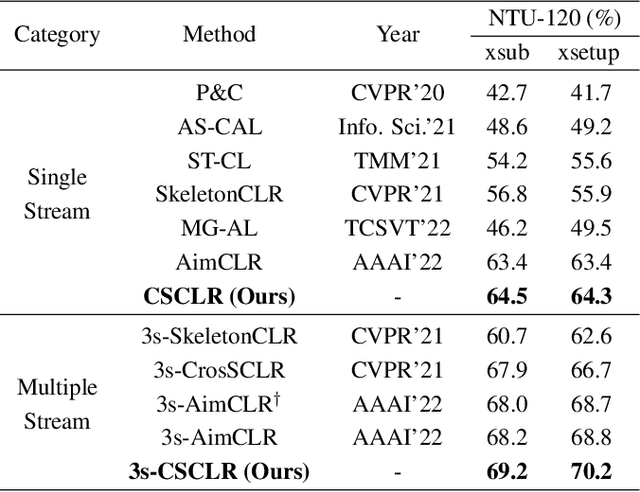
Self-supervised skeleton-based action recognition enjoys a rapid growth along with the development of contrastive learning. The existing methods rely on imposing invariance to augmentations of 3D skeleton within a single data stream, which merely leverages the easy positive pairs and limits the ability to explore the complicated movement patterns. In this paper, we advocate that the defect of single-stream contrast and the lack of necessary feature transformation are responsible for easy positives, and therefore propose a Cross-Stream Contrastive Learning framework for skeleton-based action Representation learning (CSCLR). Specifically, the proposed CSCLR not only utilizes intra-stream contrast pairs, but introduces inter-stream contrast pairs as hard samples to formulate a better representation learning. Besides, to further exploit the potential of positive pairs and increase the robustness of self-supervised representation learning, we propose a Positive Feature Transformation (PFT) strategy which adopts feature-level manipulation to increase the variance of positive pairs. To validate the effectiveness of our method, we conduct extensive experiments on three benchmark datasets NTU-RGB+D 60, NTU-RGB+D 120 and PKU-MMD. Experimental results show that our proposed CSCLR exceeds the state-of-the-art methods on a diverse range of evaluation protocols.
Cross-Domain Label Propagation for Domain Adaptation with Discriminative Graph Self-Learning
Feb 17, 2023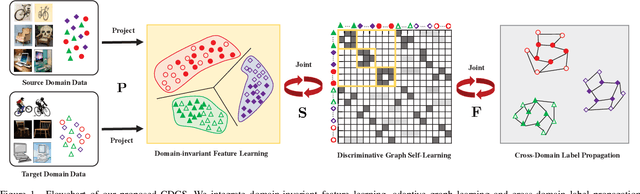

Domain adaptation manages to transfer the knowledge of well-labeled source data to unlabeled target data. Many recent efforts focus on improving the prediction accuracy of target pseudo-labels to reduce conditional distribution shift. In this paper, we propose a novel domain adaptation method, which infers target pseudo-labels through cross-domain label propagation, such that the underlying manifold structure of two domain data can be explored. Unlike existing cross-domain label propagation methods that separate domain-invariant feature learning, affinity matrix constructing and target labels inferring into three independent stages, we propose to integrate them into a unified optimization framework. In such way, these three parts can boost each other from an iterative optimization perspective and thus more effective knowledge transfer can be achieved. Furthermore, to construct a high-quality affinity matrix, we propose a discriminative graph self-learning strategy, which can not only adaptively capture the inherent similarity of the data from two domains but also effectively exploit the discriminative information contained in well-labeled source data and pseudo-labeled target data. An efficient iterative optimization algorithm is designed to solve the objective function of our proposal. Notably, the proposed method can be extended to semi-supervised domain adaptation in a simple but effective way and the corresponding optimization problem can be solved with the identical algorithm. Extensive experiments on six standard datasets verify the significant superiority of our proposal in both unsupervised and semi-supervised domain adaptation settings.
Constrained Maximum Cross-Domain Likelihood for Domain Generalization
Oct 09, 2022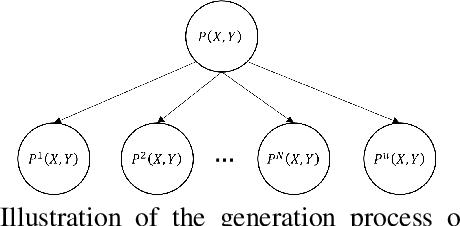
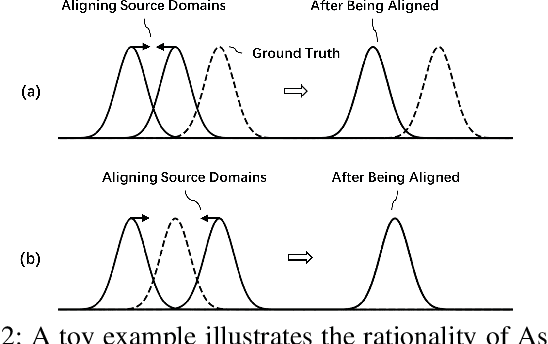
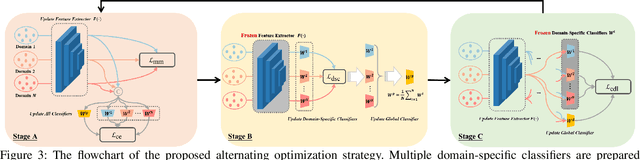
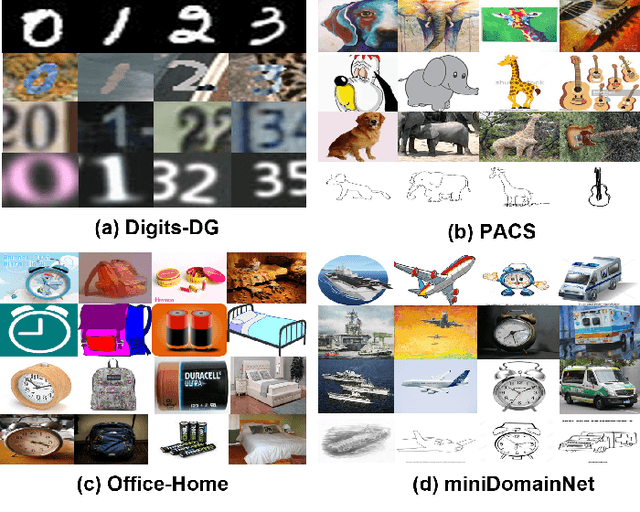
As a recent noticeable topic, domain generalization aims to learn a generalizable model on multiple source domains, which is expected to perform well on unseen test domains. Great efforts have been made to learn domain-invariant features by aligning distributions across domains. However, existing works are often designed based on some relaxed conditions which are generally hard to satisfy and fail to realize the desired joint distribution alignment. In this paper, we propose a novel domain generalization method, which originates from an intuitive idea that a domain-invariant classifier can be learned by minimizing the KL-divergence between posterior distributions from different domains. To enhance the generalizability of the learned classifier, we formalize the optimization objective as an expectation computed on the ground-truth marginal distribution. Nevertheless, it also presents two obvious deficiencies, one of which is the side-effect of entropy increase in KL-divergence and the other is the unavailability of ground-truth marginal distributions. For the former, we introduce a term named maximum in-domain likelihood to maintain the discrimination of the learned domain-invariant representation space. For the latter, we approximate the ground-truth marginal distribution with source domains under a reasonable convex hull assumption. Finally, a Constrained Maximum Cross-domain Likelihood (CMCL) optimization problem is deduced, by solving which the joint distributions are naturally aligned. An alternating optimization strategy is carefully designed to approximately solve this optimization problem. Extensive experiments on four standard benchmark datasets, i.e., Digits-DG, PACS, Office-Home and miniDomainNet, highlight the superior performance of our method.
Mitigating Both Covariate and Conditional Shift for Domain Generalization
Sep 17, 2022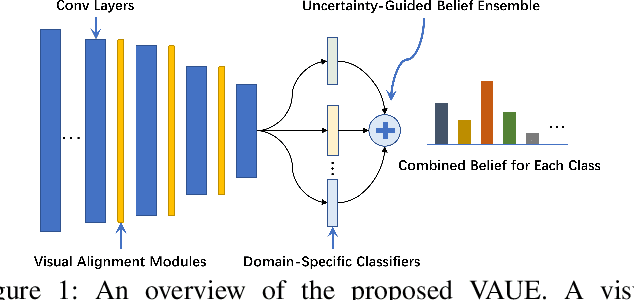
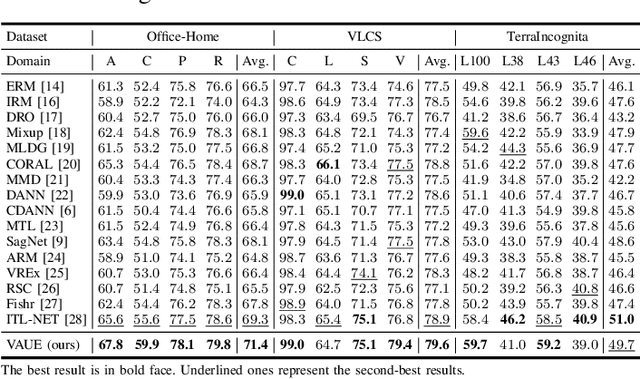
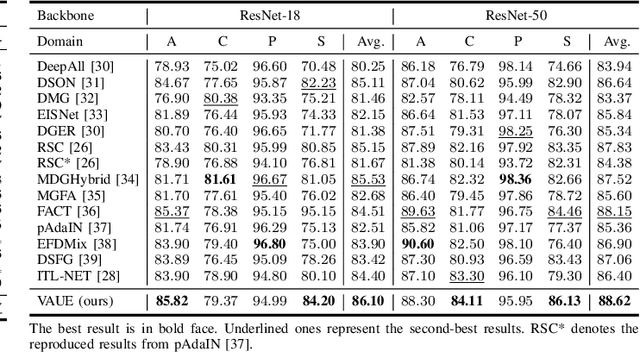
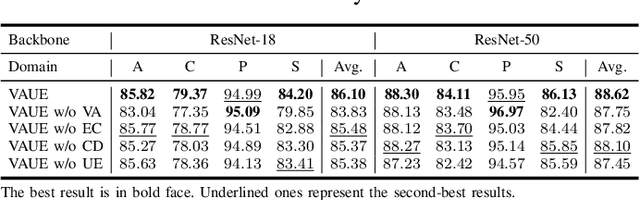
Domain generalization (DG) aims to learn a model on several source domains, hoping that the model can generalize well to unseen target domains. The distribution shift between domains contains the covariate shift and conditional shift, both of which the model must be able to handle for better generalizability. In this paper, a novel DG method is proposed to deal with the distribution shift via Visual Alignment and Uncertainty-guided belief Ensemble (VAUE). Specifically, for the covariate shift, a visual alignment module is designed to align the distribution of image style to a common empirical Gaussian distribution so that the covariate shift can be eliminated in the visual space. For the conditional shift, we adopt an uncertainty-guided belief ensemble strategy based on the subjective logic and Dempster-Shafer theory. The conditional distribution given a test sample is estimated by the dynamic combination of that of source domains. Comprehensive experiments are conducted to demonstrate the superior performance of the proposed method on four widely used datasets, i.e., Office-Home, VLCS, TerraIncognita, and PACS.
Active Learning with Effective Scoring Functions for Semi-Supervised Temporal Action Localization
Aug 31, 2022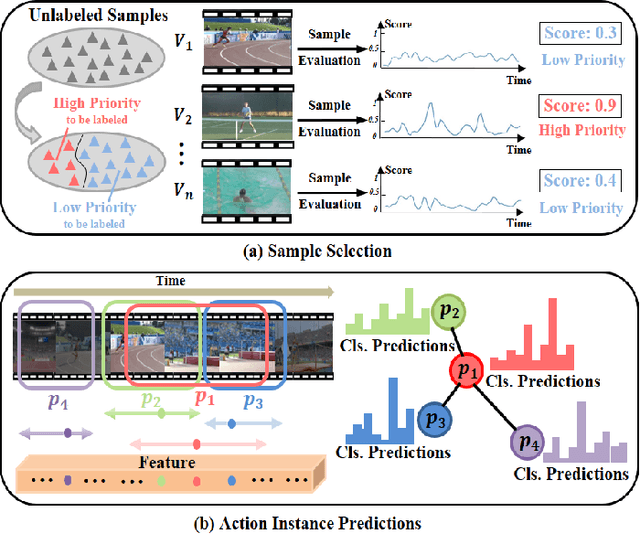
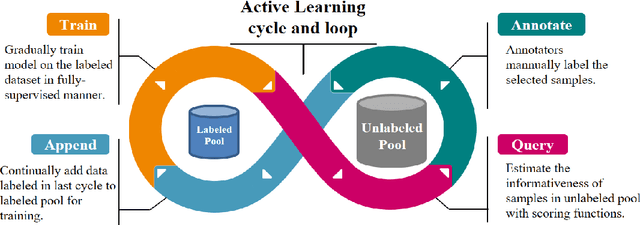
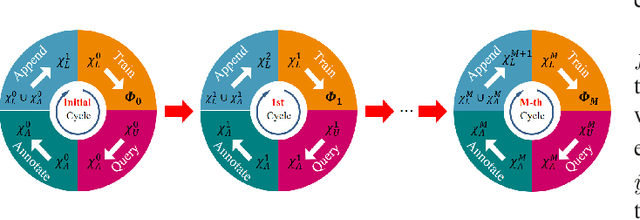
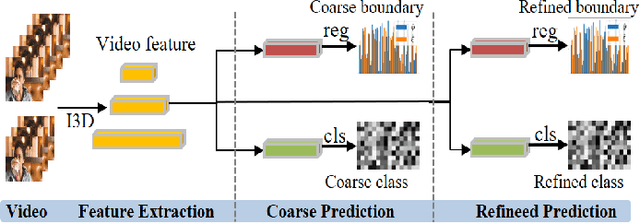
Temporal Action Localization (TAL) aims to predict both action category and temporal boundary of action instances in untrimmed videos, i.e., start and end time. Fully-supervised solutions are usually adopted in most existing works, and proven to be effective. One of the practical bottlenecks in these solutions is the large amount of labeled training data required. To reduce expensive human label cost, this paper focuses on a rarely investigated yet practical task named semi-supervised TAL and proposes an effective active learning method, named AL-STAL. We leverage four steps for actively selecting video samples with high informativeness and training the localization model, named \emph{Train, Query, Annotate, Append}. Two scoring functions that consider the uncertainty of localization model are equipped in AL-STAL, thus facilitating the video sample rank and selection. One takes entropy of predicted label distribution as measure of uncertainty, named Temporal Proposal Entropy (TPE). And the other introduces a new metric based on mutual information between adjacent action proposals and evaluates the informativeness of video samples, named Temporal Context Inconsistency (TCI). To validate the effectiveness of proposed method, we conduct extensive experiments on two benchmark datasets THUMOS'14 and ActivityNet 1.3. Experiment results show that AL-STAL outperforms the existing competitors and achieves satisfying performance compared with fully-supervised learning.
Attentive pooling for Group Activity Recognition
Aug 31, 2022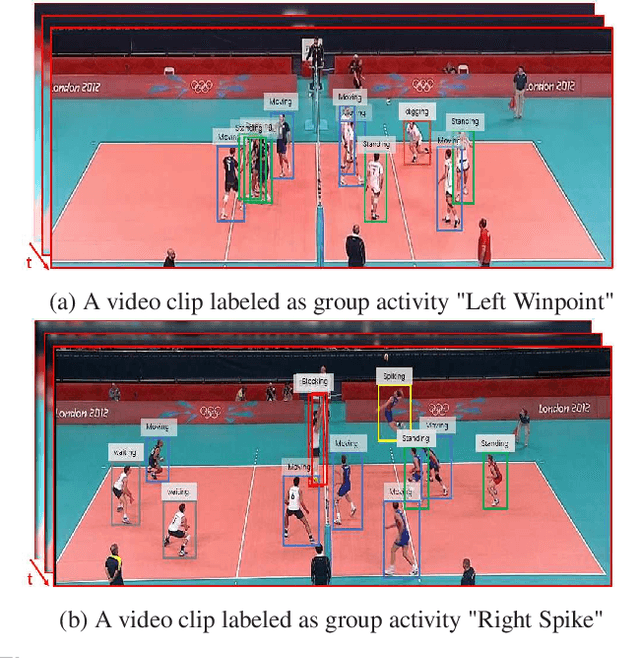

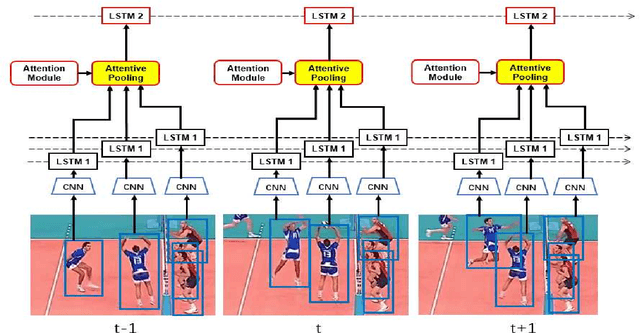
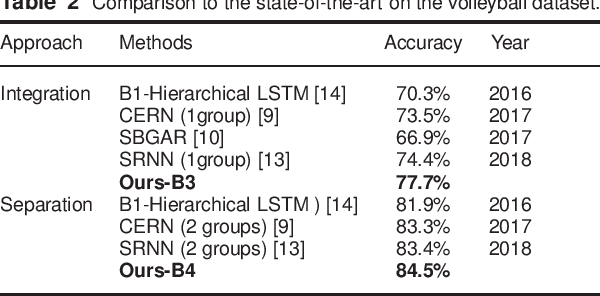
In group activity recognition, hierarchical framework is widely adopted to represent the relationships between individuals and their corresponding group, and has achieved promising performance. However, the existing methods simply employed max/average pooling in this framework, which ignored the distinct contributions of different individuals to the group activity recognition. In this paper, we propose a new contextual pooling scheme, named attentive pooling, which enables the weighted information transition from individual actions to group activity. By utilizing the attention mechanism, the attentive pooling is intrinsically interpretable and able to embed member context into the existing hierarchical model. In order to verify the effectiveness of the proposed scheme, two specific attentive pooling methods, i.e., global attentive pooling (GAP) and hierarchical attentive pooling (HAP) are designed. GAP rewards the individuals that are significant to group activity, while HAP further considers the hierarchical division by introducing subgroup structure. The experimental results on the benchmark dataset demonstrate that our proposal is significantly superior beyond the baseline and is comparable to the state-of-the-art methods.
Deep Multi-view Semi-supervised Clustering with Sample Pairwise Constraints
Jun 10, 2022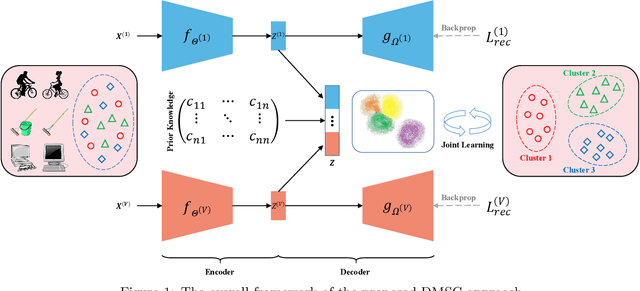


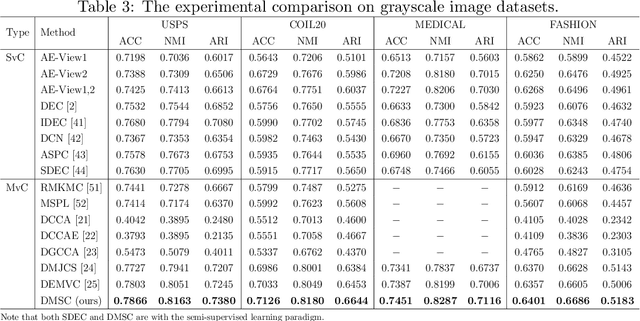
Multi-view clustering has attracted much attention thanks to the capacity of multi-source information integration. Although numerous advanced methods have been proposed in past decades, most of them generally overlook the significance of weakly-supervised information and fail to preserve the feature properties of multiple views, thus resulting in unsatisfactory clustering performance. To address these issues, in this paper, we propose a novel Deep Multi-view Semi-supervised Clustering (DMSC) method, which jointly optimizes three kinds of losses during networks finetuning, including multi-view clustering loss, semi-supervised pairwise constraint loss and multiple autoencoders reconstruction loss. Specifically, a KL divergence based multi-view clustering loss is imposed on the common representation of multi-view data to perform heterogeneous feature optimization, multi-view weighting and clustering prediction simultaneously. Then, we innovatively propose to integrate pairwise constraints into the process of multi-view clustering by enforcing the learned multi-view representation of must-link samples (cannot-link samples) to be similar (dissimilar), such that the formed clustering architecture can be more credible. Moreover, unlike existing rivals that only preserve the encoders for each heterogeneous branch during networks finetuning, we further propose to tune the intact autoencoders frame that contains both encoders and decoders. In this way, the issue of serious corruption of view-specific and view-shared feature space could be alleviated, making the whole training procedure more stable. Through comprehensive experiments on eight popular image datasets, we demonstrate that our proposed approach performs better than the state-of-the-art multi-view and single-view competitors.