 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooped Transformers with Layer Normalization Provably Learn the Power Method
May 30, 2026Transformers have achieved remarkable success across a wide range of applications, and a growing body of work suggests that part of their strength comes from their ability to learn and execute algorithmic procedures. However, our understanding of how transformers learn such algorithms remains limited, especially in the presence of layer normalization (LN). In this work, we study principal component prediction as a concrete testbed for understanding the training dynamics of transformers with LN. We prove that a looped linear transformer with LN, trained by gradient descent, converges to a solution that implements the power method, with each self-attention layer performing one power iteration. Notably, the model is trained only for principal component prediction, rather than being explicitly supervised to implement the power method. Our finding thus reveals an "algorithmic implicit bias" of looped transformers with LN: principal-component prediction can in principle be achieved by many mechanisms, yet gradient descent selects one that realizes the power method. We further provide a concrete comparison between transformers with and without LN: even with layerwise guidance from power iterations, a transformer without LN cannot exactly learn the power method, whereas the corresponding transformer with LN can, leading to a provable performance gap in principal component prediction. Our results provide, to our knowledge, the first theoretical analysis of the training dynamics of looped and single-layer transformers with LN, and shed light on the role of LN in transformer models.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
Transformers Efficiently Perform In-Context Logistic Regression via Normalized Gradient Descent
May 07, 2026Transformers have demonstrated remarkable in-context learning (ICL) capabilities. The strong ICL performance of transformers is commonly believed to arise from their ability to implicitly execute certain algorithms on the context, thereby enhancing prediction and generation. In this work, we investigate how transformers with softmax attention perform in-context learning on linear classification data. We first construct a class of multi-layer transformers that can perform in-context logistic regression, with each layer exactly performing one step of normalized gradient descent on an in-context loss. Then, we show that our constructed transformer can be obtained through (i) training a single self-attention layer supervised by one-step gradient descent, and (ii) recurrently applying the trained layer to obtain a looped model. Training convergence guarantees of the self-attention layer and out-of-distribution generalization guarantees of the looped model are provided. Our results advance the theoretical understanding of ICL mechanism by showcasing how softmax transformers can effectively act as in-context learners.
Low-complexity Frequency Domain Equalization for filtered-AFDM over General Physical Channels
Apr 09, 2026Affine frequency division multiplexing (AFDM) has emerged as a promising waveform for high-mobility communications. However, its equalization remains a practical challenge under general physical channels with off-grid delay and Doppler effects. In this paper, we investigate frequency domain equalization for AFDM by considering a practical filtered-AFDM waveform. We analyze the input-output relations of filtered-AFDM across various domains and show that off-grid effects lead to severe inter-symbol interference in the DAFT domain, limiting the effectiveness of DAFT domain equalization. Motivated by the compactness of the frequency domain channel matrix in wideband systems, we propose a low-complexity two-stage frequency domain equalization scheme. Numerical results demonstrate that the proposed approach achieves performance close to full-block LMMSE equalization with significantly reduced computational complexity, and offers clear advantages over time domain equalization in wideband scenarios.
Transformers Trained via Gradient Descent Can Provably Learn a Class of Teacher Models
Mar 24, 2026Transformers have achieved great success across a wide range of applications, yet the theoretical foundations underlying their success remain largely unexplored. To demystify the strong capacities of transformers applied to versatile scenarios and tasks, we theoretically investigate utilizing transformers as students to learn from a class of teacher models. Specifically, the teacher models covered in our analysis include convolution layers with average pooling, graph convolution layers, and various classic statistical learning models, including a variant of sparse token selection models [Sanford et al., 2023, Wang et al., 2024] and group-sparse linear predictors [Zhang et al., 2025]. When learning from this class of teacher models, we prove that one-layer transformers with simplified "position-only'' attention can successfully recover all parameter blocks of the teacher models, thus achieving the optimal population loss. Building upon the efficient mimicry of trained transformers towards teacher models, we further demonstrate that they can generalize well to a broad class of out-of-distribution data under mild assumptions. The key in our analysis is to identify a fundamental bilinear structure shared by various learning tasks, which enables us to establish unified learning guarantees for these tasks when treating them as teachers for transformers.
A Novel One-tap Equalizer for Zero-Padded AFDM System over Doubly Selective Channels
Mar 03, 2026Recently, affine frequency division multiplexing (AFDM) has gained traction as a robust solution for doubly selective channels. In this paper, we present a novel low-complexity one-tap equalizer for zero-padded AFDM (ZP-AFDM) systems. We first select the AFDM parameters, $c_1$ and $c_2$, such that $c_1$ has a relatively high value, and $c_2$ depends on $c_1$, which simplifies the affine domain input-output relation (IOR). This selection also demonstrates that a phase term that varies slowly along the affine domain is experienced by all affine domain symbols and this variation is significantly slower compared to that experienced by the time domain symbols over doubly selective channels. To simplify the equalization, we then introduce zero padding to the transmitted affine domain symbols and reconstruction operation on the received affine domain symbols. By doing so, we convert the effective affine domain IOR of our ZP-AFDM system to be characterized using approximately circular convolution. Next, we transform the resulting affine domain symbols into a new domain called the frequency-of-affine (FoA) domain. We propose our one-tap equalizer in this FoA domain to efficiently recover the transmitted symbols. Numerical results demonstrate the effectiveness of our proposed one-tap equalizer, particularly when $c_1$ is high, without compromising performance robustness.
CoVe: Training Interactive Tool-Use Agents via Constraint-Guided Verification
Mar 02, 2026Developing multi-turn interactive tool-use agents is challenging because real-world user needs are often complex and ambiguous, yet agents must execute deterministic actions to satisfy them. To address this gap, we introduce \textbf{CoVe} (\textbf{Co}nstraint-\textbf{Ve}rification), a post-training data synthesis framework designed for training interactive tool-use agents while ensuring both data complexity and correctness. CoVe begins by defining explicit task constraints, which serve a dual role: they guide the generation of complex trajectories and act as deterministic verifiers for assessing trajectory quality. This enables the creation of high-quality training trajectories for supervised fine-tuning (SFT) and the derivation of accurate reward signals for reinforcement learning (RL). Our evaluation on the challenging $τ^2$-bench benchmark demonstrates the effectiveness of the framework. Notably, our compact \textbf{CoVe-4B} model achieves success rates of 43.0\% and 59.4\% in the Airline and Retail domains, respectively; its overall performance significantly outperforms strong baselines of similar scale and remains competitive with models up to $17\times$ its size. These results indicate that CoVe provides an effective and efficient pathway for synthesizing training data for state-of-the-art interactive tool-use agents. To support future research, we open-source our code, trained model, and the full set of 12K high-quality trajectories used for training.
TRIP-Bench: A Benchmark for Long-Horizon Interactive Agents in Real-World Scenarios
Feb 02, 2026As LLM-based agents are deployed in increasingly complex real-world settings, existing benchmarks underrepresent key challenges such as enforcing global constraints, coordinating multi-tool reasoning, and adapting to evolving user behavior over long, multi-turn interactions. To bridge this gap, we introduce \textbf{TRIP-Bench}, a long-horizon benchmark grounded in realistic travel-planning scenarios. TRIP-Bench leverages real-world data, offers 18 curated tools and 40+ travel requirements, and supports automated evaluation. It includes splits of varying difficulty; the hard split emphasizes long and ambiguous interactions, style shifts, feasibility changes, and iterative version revision. Dialogues span up to 15 user turns, can involve 150+ tool calls, and may exceed 200k tokens of context. Experiments show that even advanced models achieve at most 50\% success on the easy split, with performance dropping below 10\% on hard subsets. We further propose \textbf{GTPO}, an online multi-turn reinforcement learning method with specialized reward normalization and reward differencing. Applied to Qwen2.5-32B-Instruct, GTPO improves constraint satisfaction and interaction robustness, outperforming Gemini-3-Pro in our evaluation. We expect TRIP-Bench to advance practical long-horizon interactive agents, and GTPO to provide an effective online RL recipe for robust long-horizon training.
OneStory: Coherent Multi-Shot Video Generation with Adaptive Memory
Dec 08, 2025
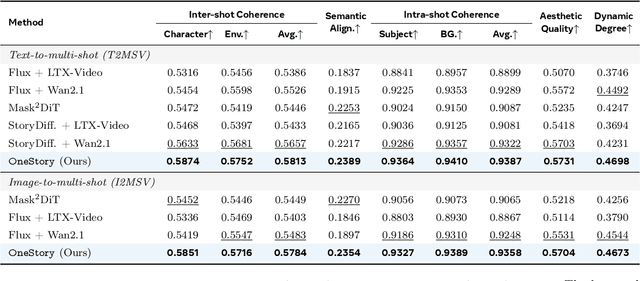
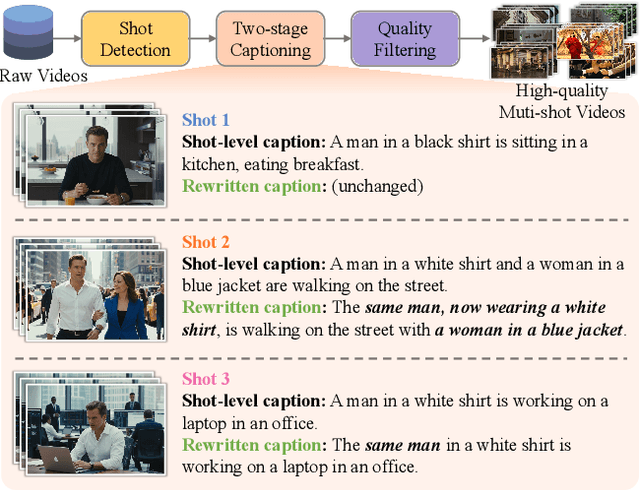

Storytelling in real-world videos often unfolds through multiple shots -- discontinuous yet semantically connected clips that together convey a coherent narrative. However, existing multi-shot video generation (MSV) methods struggle to effectively model long-range cross-shot context, as they rely on limited temporal windows or single keyframe conditioning, leading to degraded performance under complex narratives. In this work, we propose OneStory, enabling global yet compact cross-shot context modeling for consistent and scalable narrative generation. OneStory reformulates MSV as a next-shot generation task, enabling autoregressive shot synthesis while leveraging pretrained image-to-video (I2V) models for strong visual conditioning. We introduce two key modules: a Frame Selection module that constructs a semantically-relevant global memory based on informative frames from prior shots, and an Adaptive Conditioner that performs importance-guided patchification to generate compact context for direct conditioning. We further curate a high-quality multi-shot dataset with referential captions to mirror real-world storytelling patterns, and design effective training strategies under the next-shot paradigm. Finetuned from a pretrained I2V model on our curated 60K dataset, OneStory achieves state-of-the-art narrative coherence across diverse and complex scenes in both text- and image-conditioned settings, enabling controllable and immersive long-form video storytelling.
Omni-LIVO: Robust RGB-Colored Multi-Camera Visual-Inertial-LiDAR Odometry via Photometric Migration and ESIKF Fusion
Sep 19, 2025



Wide field-of-view (FoV) LiDAR sensors provide dense geometry across large environments, but most existing LiDAR-inertial-visual odometry (LIVO) systems rely on a single camera, leading to limited spatial coverage and degraded robustness. We present Omni-LIVO, the first tightly coupled multi-camera LIVO system that bridges the FoV mismatch between wide-angle LiDAR and conventional cameras. Omni-LIVO introduces a Cross-View direct tracking strategy that maintains photometric consistency across non-overlapping views, and extends the Error-State Iterated Kalman Filter (ESIKF) with multi-view updates and adaptive covariance weighting. The system is evaluated on public benchmarks and our custom dataset, showing improved accuracy and robustness over state-of-the-art LIVO, LIO, and visual-inertial baselines. Code and dataset will be released upon publication.