 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Consistency: Inference for the Relative risk functional in Deep Nonparametric Cox Models
Mar 25, 2026There remain theoretical gaps in deep neural network estimators for the nonparametric Cox proportional hazards model. In particular, it is unclear how gradient-based optimization error propagates to population risk under partial likelihood, how pointwise bias can be controlled to permit valid inference, and how ensemble-based uncertainty quantification behaves under realistic variance decay regimes. We develop an asymptotic distribution theory for deep Cox estimators that addresses these issues. First, we establish nonasymptotic oracle inequalities for general trained networks that link in-sample optimization error to population risk without requiring the exact empirical risk optimizer. We then construct a structured neural parameterization that achieves infinity-norm approximation rates compatible with the oracle bound, yielding control of the pointwise bias. Under these conditions and using the Hajek--Hoeffding projection, we prove pointwise and multivariate asymptotic normality for subsampled ensemble estimators. We derive a range of subsample sizes that balances bias correction with the requirement that the Hajek--Hoeffding projection remain dominant. This range accommodates decay conditions on the single-overlap covariance, which measures how strongly a single shared observation influences the estimator, and is weaker than those imposed in the subsampling literature. An infinitesimal jackknife representation provides analytic covariance estimation and valid Wald-type inference for relative risk contrasts such as log-hazard ratios. Finally, we illustrate the finite-sample implications of the theory through simulations and a real data application.
Towards Understanding Feature Learning in Parameter Transfer
Sep 26, 2025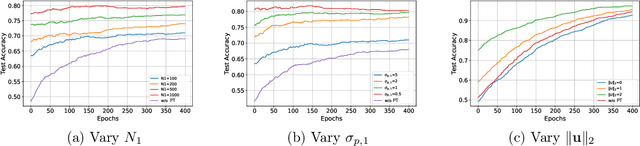
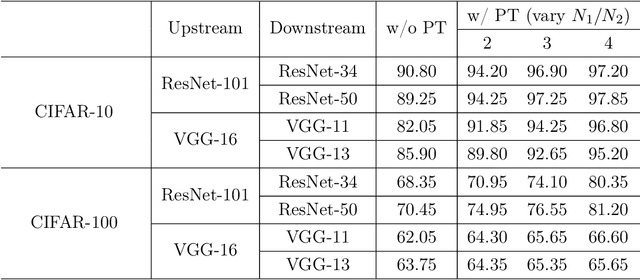
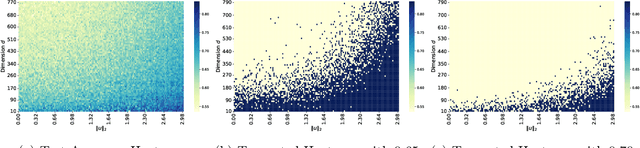
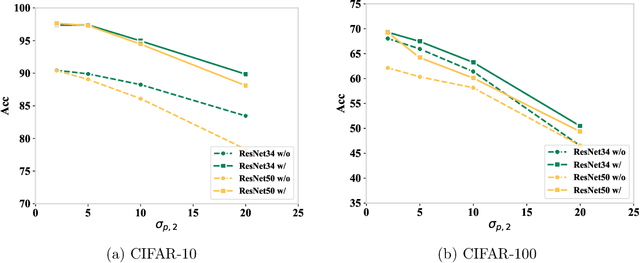
Parameter transfer is a central paradigm in transfer learning, enabling knowledge reuse across tasks and domains by sharing model parameters between upstream and downstream models. However, when only a subset of parameters from the upstream model is transferred to the downstream model, there remains a lack of theoretical understanding of the conditions under which such partial parameter reuse is beneficial and of the factors that govern its effectiveness. To address this gap, we analyze a setting in which both the upstream and downstream models are ReLU convolutional neural networks (CNNs). Within this theoretical framework, we characterize how the inherited parameters act as carriers of universal knowledge and identify key factors that amplify their beneficial impact on the target task. Furthermore, our analysis provides insight into why, in certain cases, transferring parameters can lead to lower test accuracy on the target task than training a new model from scratch. Numerical experiments and real-world data experiments are conducted to empirically validate our theoretical findings.
Inferring Outcome Means of Exponential Family Distributions Estimated by Deep Neural Networks
Apr 15, 2025



While deep neural networks (DNNs) are widely used for prediction, inference on DNN-estimated subject-specific means for categorical or exponential family outcomes remains underexplored. We address this by proposing a DNN estimator under generalized nonparametric regression models (GNRMs) and developing a rigorous inference framework. Unlike existing approaches that assume independence between prediction errors and inputs to establish the error bound, a condition often violated in GNRMs, we allow for dependence and our theoretical analysis demonstrates the feasibility of drawing inference under GNRMs. To implement inference, we consider an Ensemble Subsampling Method (ESM) that leverages U-statistics and the Hoeffding decomposition to construct reliable confidence intervals for DNN estimates. We show that, under GNRM settings, ESM enables model-free variance estimation and accounts for heterogeneity among individuals in the population. Through simulations under nonparametric logistic, Poisson, and binomial regression models, we demonstrate the effectiveness and efficiency of our method. We further apply the method to the electronic Intensive Care Unit (eICU) dataset, a large-scale collection of anonymized health records from ICU patients, to predict ICU readmission risk and offer patient-centric insights for clinical decision-making.
Transformer Learns Optimal Variable Selection in Group-Sparse Classification
Apr 11, 2025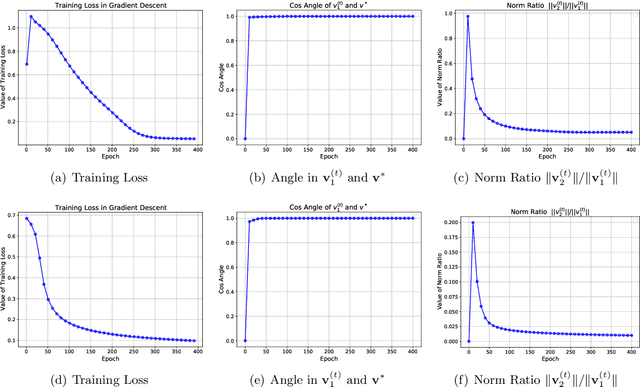
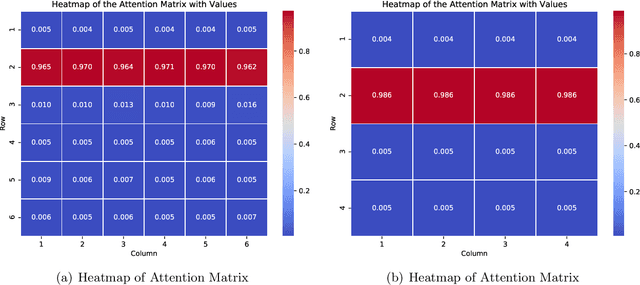
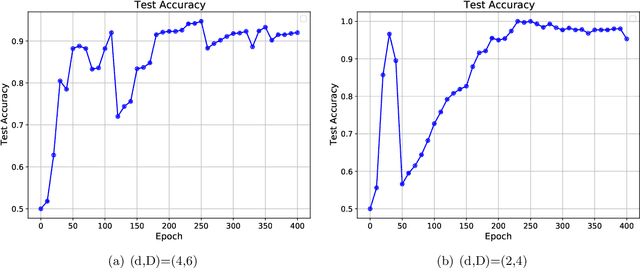
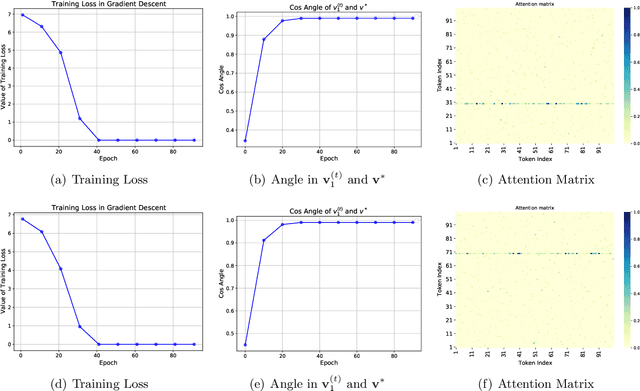
Transformers have demonstrated remarkable success across various applications. However, the success of transformers have not been understood in theory. In this work, we give a case study of how transformers can be trained to learn a classic statistical model with "group sparsity", where the input variables form multiple groups, and the label only depends on the variables from one of the groups. We theoretically demonstrate that, a one-layer transformer trained by gradient descent can correctly leverage the attention mechanism to select variables, disregarding irrelevant ones and focusing on those beneficial for classification. We also demonstrate that a well-pretrained one-layer transformer can be adapted to new downstream tasks to achieve good prediction accuracy with a limited number of samples. Our study sheds light on how transformers effectively learn structured data.
Initialization Matters: On the Benign Overfitting of Two-Layer ReLU CNN with Fully Trainable Layers
Oct 24, 2024Benign overfitting refers to how over-parameterized neural networks can fit training data perfectly and generalize well to unseen data. While this has been widely investigated theoretically, existing works are limited to two-layer networks with fixed output layers, where only the hidden weights are trained. We extend the analysis to two-layer ReLU convolutional neural networks (CNNs) with fully trainable layers, which is closer to the practice. Our results show that the initialization scaling of the output layer is crucial to the training dynamics: large scales make the model training behave similarly to that with the fixed output, the hidden layer grows rapidly while the output layer remains largely unchanged; in contrast, small scales result in more complex layer interactions, the hidden layer initially grows to a specific ratio relative to the output layer, after which both layers jointly grow and maintain that ratio throughout training. Furthermore, in both settings, we provide nearly matching upper and lower bounds on the test errors, identifying the sharp conditions on the initialization scaling and signal-to-noise ratio (SNR) in which the benign overfitting can be achieved or not. Numerical experiments back up the theoretical results.
Benign Overfitting in Two-Layer ReLU Convolutional Neural Networks for XOR Data
Oct 03, 2023Modern deep learning models are usually highly over-parameterized so that they can overfit the training data. Surprisingly, such overfitting neural networks can usually still achieve high prediction accuracy. To study this "benign overfitting" phenomenon, a line of recent works has theoretically studied the learning of linear models and two-layer neural networks. However, most of these analyses are still limited to the very simple learning problems where the Bayes-optimal classifier is linear. In this work, we investigate a class of XOR-type classification tasks with label-flipping noises. We show that, under a certain condition on the sample complexity and signal-to-noise ratio, an over-parameterized ReLU CNN trained by gradient descent can achieve near Bayes-optimal accuracy. Moreover, we also establish a matching lower bound result showing that when the previous condition is not satisfied, the prediction accuracy of the obtained CNN is an absolute constant away from the Bayes-optimal rate. Our result demonstrates that CNNs have a remarkable capacity to efficiently learn XOR problems, even in the presence of highly correlated features.
Per-Example Gradient Regularization Improves Learning Signals from Noisy Data
Mar 31, 2023Gradient regularization, as described in \citet{barrett2021implicit}, is a highly effective technique for promoting flat minima during gradient descent. Empirical evidence suggests that this regularization technique can significantly enhance the robustness of deep learning models against noisy perturbations, while also reducing test error. In this paper, we explore the per-example gradient regularization (PEGR) and present a theoretical analysis that demonstrates its effectiveness in improving both test error and robustness against noise perturbations. Specifically, we adopt a signal-noise data model from \citet{cao2022benign} and show that PEGR can learn signals effectively while suppressing noise. In contrast, standard gradient descent struggles to distinguish the signal from the noise, leading to suboptimal generalization performance. Our analysis reveals that PEGR penalizes the variance of pattern learning, thus effectively suppressing the memorization of noises from the training data. These findings underscore the importance of variance control in deep learning training and offer useful insights for developing more effective training approaches.
Multiple Descent in the Multiple Random Feature Model
Aug 21, 2022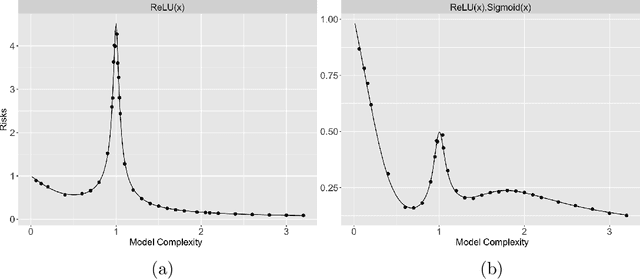
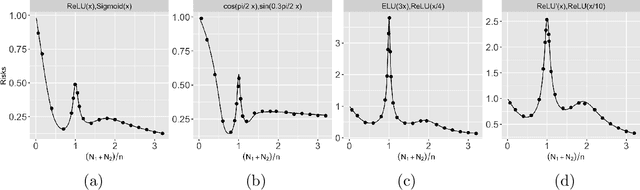
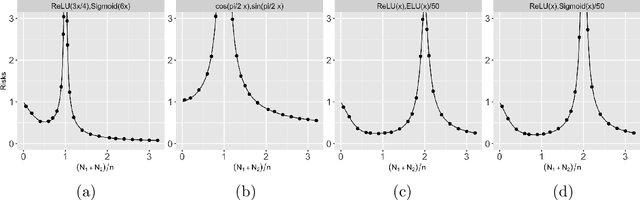
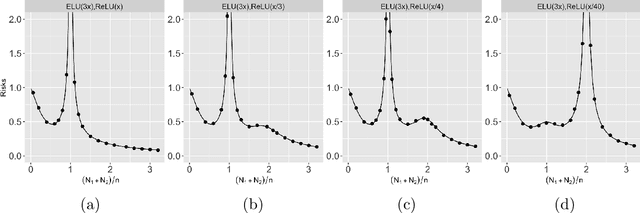
Recent works have demonstrated a double descent phenomenon in over-parameterized learning: as the number of model parameters increases, the excess risk has a $\mathsf{U}$-shape at beginning, then decreases again when the model is highly over-parameterized. Although this phenomenon has been investigated by recent works under different settings such as linear models, random feature models and kernel methods, it has not been fully understood in theory. In this paper, we consider a double random feature model (DRFM) consisting of two types of random features, and study the excess risk achieved by the DRFM in ridge regression. We calculate the precise limit of the excess risk under the high dimensional framework where the training sample size, the dimension of data, and the dimension of random features tend to infinity proportionally. Based on the calculation, we demonstrate that the risk curves of DRFMs can exhibit triple descent. We then provide an explanation of the triple descent phenomenon, and discuss how the ratio between random feature dimensions, the regularization parameter and the signal-to-noise ratio control the shape of the risk curves of DRFMs. At last, we extend our study to the multiple random feature model (MRFM), and show that MRFMs with $K$ types of random features may exhibit $(K+1)$-fold descent. Our analysis points out that risk curves with a specific number of descent generally exist in random feature based regression. Another interesting finding is that our result can recover the risk peak locations reported in the literature when learning neural networks are in the "neural tangent kernel" regime.
Implicit Data-Driven Regularization in Deep Neural Networks under SGD
Nov 26, 2021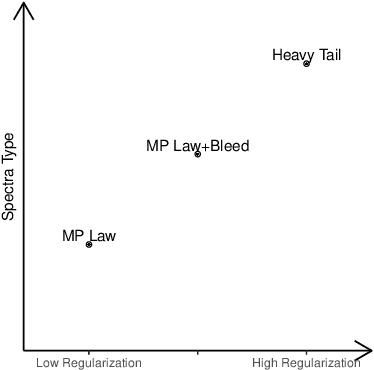


Much research effort has been devoted to explaining the success of deep learning. Random Matrix Theory (RMT) provides an emerging way to this end: spectral analysis of large random matrices involved in a trained deep neural network (DNN) such as weight matrices or Hessian matrices with respect to the stochastic gradient descent algorithm. In this paper, we conduct extensive experiments on weight matrices in different modules, e.g., layers, networks and data sets, to analyze the evolution of their spectra. We find that these spectra can be classified into three main types: Mar\v{c}enko-Pastur spectrum (MP), Mar\v{c}enko-Pastur spectrum with few bleeding outliers (MPB), and Heavy tailed spectrum (HT). Moreover, these discovered spectra are directly connected to the degree of regularization in the DNN. We argue that the degree of regularization depends on the quality of data fed to the DNN, namely Data-Driven Regularization. These findings are validated in several NNs, using Gaussian synthetic data and real data sets (MNIST and CIFAR10). Finally, we propose a spectral criterion and construct an early stopping procedure when the NN is found highly regularized without test data by using the connection between the spectra types and the degrees of regularization. Such early stopped DNNs avoid unnecessary extra training while preserving a much comparable generalization ability.