 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMean-Shift PCA by Knockoff Mean
May 25, 2026Removing noise is difficult, but adding noise is easy. In this work, we show how to eliminate mean-shift noisy components from PCA by deliberately introducing knockoff mean-shift perturbation. Standard PCA is highly sensitive to shifts in the sample mean: a small fraction of samples from a shifted distribution can cause large deviations in the leading principal components. In high-dimensional regimes, existing Robust PCA approaches cannot handle the mean-shift contamination structure inherent in the mixture model. Using tools from Random Matrix Theory, we prove that the mean-shift spikes are spectrally separable from the stable eigenvalues of the original covariance. Furthermore, the original eigenspace remains asymptotically invariant to the contamination, independent of the mixture weight. Exploiting this spectral stability, we propose a simple, two-stage PCA algorithm by adding knockoff mean that identifies and removes the mean-shift component using only standard PCA operations.
Towards Quantifying the Hessian Structure of Neural Networks
May 05, 2025Empirical studies reported that the Hessian matrix of neural networks (NNs) exhibits a near-block-diagonal structure, yet its theoretical foundation remains unclear. In this work, we reveal two forces that shape the Hessian structure: a ``static force'' rooted in the architecture design, and a ``dynamic force'' arisen from training. We then provide a rigorous theoretical analysis of ``static force'' at random initialization. We study linear models and 1-hidden-layer networks with the mean-square (MSE) loss and the Cross-Entropy (CE) loss for classification tasks. By leveraging random matrix theory, we compare the limit distributions of the diagonal and off-diagonal Hessian blocks and find that the block-diagonal structure arises as $C \rightarrow \infty$, where $C$ denotes the number of classes. Our findings reveal that $C$ is a primary driver of the near-block-diagonal structure. These results may shed new light on the Hessian structure of large language models (LLMs), which typically operate with a large $C$ exceeding $10^4$ or $10^5$.
CMATH: Cross-Modality Augmented Transformer with Hierarchical Variational Distillation for Multimodal Emotion Recognition in Conversation
Nov 15, 2024Multimodal emotion recognition in conversation (MER) aims to accurately identify emotions in conversational utterances by integrating multimodal information. Previous methods usually treat multimodal information as equal quality and employ symmetric architectures to conduct multimodal fusion. However, in reality, the quality of different modalities usually varies considerably, and utilizing a symmetric architecture is difficult to accurately recognize conversational emotions when dealing with uneven modal information. Furthermore, fusing multi-modality information in a single granularity may fail to adequately integrate modal information, exacerbating the inaccuracy in emotion recognition. In this paper, we propose a novel Cross-Modality Augmented Transformer with Hierarchical Variational Distillation, called CMATH, which consists of two major components, i.e., Multimodal Interaction Fusion and Hierarchical Variational Distillation. The former is comprised of two submodules, including Modality Reconstruction and Cross-Modality Augmented Transformer (CMA-Transformer), where Modality Reconstruction focuses on obtaining high-quality compressed representation of each modality, and CMA-Transformer adopts an asymmetric fusion strategy which treats one modality as the central modality and takes others as auxiliary modalities. The latter first designs a variational fusion network to fuse the fine-grained representations learned by CMA- Transformer into a coarse-grained representations. Then, it introduces a hierarchical distillation framework to maintain the consistency between modality representations with different granularities. Experiments on the IEMOCAP and MELD datasets demonstrate that our proposed model outperforms previous state-of-the-art baselines. Implementation codes can be available at https://github.com/ cjw-MER/CMATH.
Multiple Descent in the Multiple Random Feature Model
Aug 21, 2022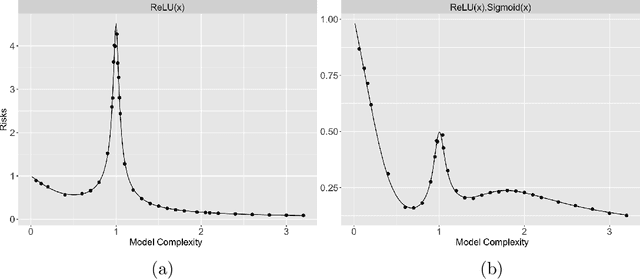
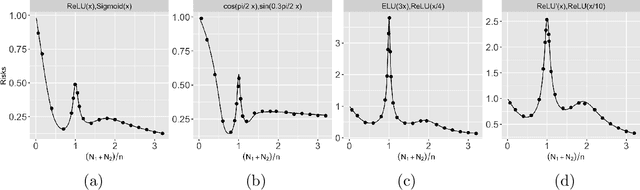
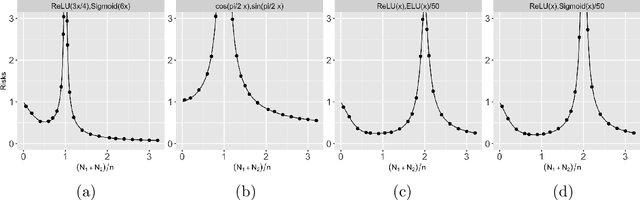
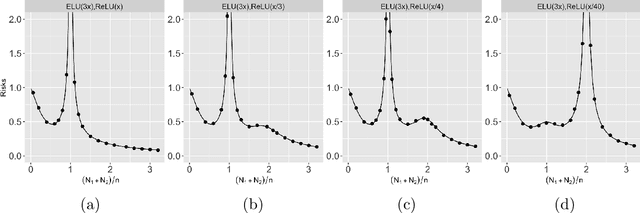
Recent works have demonstrated a double descent phenomenon in over-parameterized learning: as the number of model parameters increases, the excess risk has a $\mathsf{U}$-shape at beginning, then decreases again when the model is highly over-parameterized. Although this phenomenon has been investigated by recent works under different settings such as linear models, random feature models and kernel methods, it has not been fully understood in theory. In this paper, we consider a double random feature model (DRFM) consisting of two types of random features, and study the excess risk achieved by the DRFM in ridge regression. We calculate the precise limit of the excess risk under the high dimensional framework where the training sample size, the dimension of data, and the dimension of random features tend to infinity proportionally. Based on the calculation, we demonstrate that the risk curves of DRFMs can exhibit triple descent. We then provide an explanation of the triple descent phenomenon, and discuss how the ratio between random feature dimensions, the regularization parameter and the signal-to-noise ratio control the shape of the risk curves of DRFMs. At last, we extend our study to the multiple random feature model (MRFM), and show that MRFMs with $K$ types of random features may exhibit $(K+1)$-fold descent. Our analysis points out that risk curves with a specific number of descent generally exist in random feature based regression. Another interesting finding is that our result can recover the risk peak locations reported in the literature when learning neural networks are in the "neural tangent kernel" regime.
Implicit Data-Driven Regularization in Deep Neural Networks under SGD
Nov 26, 2021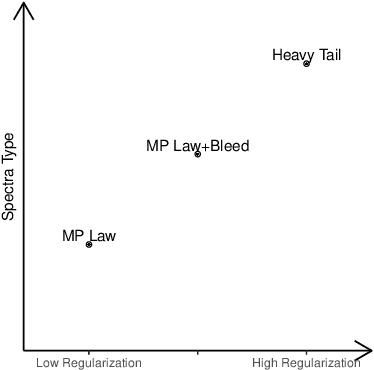


Much research effort has been devoted to explaining the success of deep learning. Random Matrix Theory (RMT) provides an emerging way to this end: spectral analysis of large random matrices involved in a trained deep neural network (DNN) such as weight matrices or Hessian matrices with respect to the stochastic gradient descent algorithm. In this paper, we conduct extensive experiments on weight matrices in different modules, e.g., layers, networks and data sets, to analyze the evolution of their spectra. We find that these spectra can be classified into three main types: Mar\v{c}enko-Pastur spectrum (MP), Mar\v{c}enko-Pastur spectrum with few bleeding outliers (MPB), and Heavy tailed spectrum (HT). Moreover, these discovered spectra are directly connected to the degree of regularization in the DNN. We argue that the degree of regularization depends on the quality of data fed to the DNN, namely Data-Driven Regularization. These findings are validated in several NNs, using Gaussian synthetic data and real data sets (MNIST and CIFAR10). Finally, we propose a spectral criterion and construct an early stopping procedure when the NN is found highly regularized without test data by using the connection between the spectra types and the degrees of regularization. Such early stopped DNNs avoid unnecessary extra training while preserving a much comparable generalization ability.