 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Command Injection Vulnerability Analysis in Python: An Empirical Study on Popular Open-Source Projects
May 21, 2025



Command injection vulnerabilities are a significant security threat in dynamic languages like Python, particularly in widely used open-source projects where security issues can have extensive impact. With the proven effectiveness of Large Language Models(LLMs) in code-related tasks, such as testing, researchers have explored their potential for vulnerabilities analysis. This study evaluates the potential of large language models (LLMs), such as GPT-4, as an alternative approach for automated testing for vulnerability detection. In particular, LLMs have demonstrated advanced contextual understanding and adaptability, making them promising candidates for identifying nuanced security vulnerabilities within code. To evaluate this potential, we applied LLM-based analysis to six high-profile GitHub projects-Django, Flask, TensorFlow, Scikit-learn, PyTorch, and Langchain-each with over 50,000 stars and extensive adoption across software development and academic research. Our analysis assesses both the strengths and limitations of LLMs in detecting command injection vulnerabilities, evaluating factors such as detection accuracy, efficiency, and practical integration into development workflows. In addition, we provide a comparative analysis of different LLM tools to identify those most suitable for security applications. Our findings offer guidance for developers and security researchers on leveraging LLMs as innovative and automated approaches to enhance software security.
CMATH: Cross-Modality Augmented Transformer with Hierarchical Variational Distillation for Multimodal Emotion Recognition in Conversation
Nov 15, 2024Multimodal emotion recognition in conversation (MER) aims to accurately identify emotions in conversational utterances by integrating multimodal information. Previous methods usually treat multimodal information as equal quality and employ symmetric architectures to conduct multimodal fusion. However, in reality, the quality of different modalities usually varies considerably, and utilizing a symmetric architecture is difficult to accurately recognize conversational emotions when dealing with uneven modal information. Furthermore, fusing multi-modality information in a single granularity may fail to adequately integrate modal information, exacerbating the inaccuracy in emotion recognition. In this paper, we propose a novel Cross-Modality Augmented Transformer with Hierarchical Variational Distillation, called CMATH, which consists of two major components, i.e., Multimodal Interaction Fusion and Hierarchical Variational Distillation. The former is comprised of two submodules, including Modality Reconstruction and Cross-Modality Augmented Transformer (CMA-Transformer), where Modality Reconstruction focuses on obtaining high-quality compressed representation of each modality, and CMA-Transformer adopts an asymmetric fusion strategy which treats one modality as the central modality and takes others as auxiliary modalities. The latter first designs a variational fusion network to fuse the fine-grained representations learned by CMA- Transformer into a coarse-grained representations. Then, it introduces a hierarchical distillation framework to maintain the consistency between modality representations with different granularities. Experiments on the IEMOCAP and MELD datasets demonstrate that our proposed model outperforms previous state-of-the-art baselines. Implementation codes can be available at https://github.com/ cjw-MER/CMATH.
CQIL: Inference Latency Optimization with Concurrent Computation of Quasi-Independent Layers
Apr 10, 2024The fast-growing large scale language models are delivering unprecedented performance on almost all natural language processing tasks. However, the effectiveness of large language models are reliant on an exponentially increasing number of parameters. The overwhelming computation complexity incurs a high inference latency that negatively affects user experience. Existing methods to improve inference efficiency, such as tensor parallelism and quantization, target to reduce per-layer computing latency, yet overlook the cumulative latency due to the number of layers. Recent works on reducing the cumulative latency through layer removing, however, lead to significant performance drop. Motivated by the similarity of inputs among adjacent layers, we propose to identify quasi-independent layers, which can be concurrently computed to significantly decrease inference latency. We also introduce a bypassing technique to mitigate the effect of information loss. Empirical experiments of the proposed approach on the LLaMA models confirm that Concurrent Computation of Quasi-Independent Layers (CQIL) can reduce latency by up to 48.3% on the LLaMA-33B model, while maintaining a close level of performance.
Securing Recommender System via Cooperative Training
Jan 23, 2024Recommender systems are often susceptible to well-crafted fake profiles, leading to biased recommendations. Among existing defense methods, data-processing-based methods inevitably exclude normal samples, while model-based methods struggle to enjoy both generalization and robustness. To this end, we suggest integrating data processing and the robust model to propose a general framework, Triple Cooperative Defense (TCD), which employs three cooperative models that mutually enhance data and thereby improve recommendation robustness. Furthermore, Considering that existing attacks struggle to balance bi-level optimization and efficiency, we revisit poisoning attacks in recommender systems and introduce an efficient attack strategy, Co-training Attack (Co-Attack), which cooperatively optimizes the attack optimization and model training, considering the bi-level setting while maintaining attack efficiency. Moreover, we reveal a potential reason for the insufficient threat of existing attacks is their default assumption of optimizing attacks in undefended scenarios. This overly optimistic setting limits the potential of attacks. Consequently, we put forth a Game-based Co-training Attack (GCoAttack), which frames the proposed CoAttack and TCD as a game-theoretic process, thoroughly exploring CoAttack's attack potential in the cooperative training of attack and defense. Extensive experiments on three real datasets demonstrate TCD's superiority in enhancing model robustness. Additionally, we verify that the two proposed attack strategies significantly outperform existing attacks, with game-based GCoAttack posing a greater poisoning threat than CoAttack.
Using Saliency and Cropping to Improve Video Memorability
Sep 21, 2023Video memorability is a measure of how likely a particular video is to be remembered by a viewer when that viewer has no emotional connection with the video content. It is an important characteristic as videos that are more memorable are more likely to be shared, viewed, and discussed. This paper presents results of a series of experiments where we improved the memorability of a video by selectively cropping frames based on image saliency. We present results of a basic fixed cropping as well as the results from dynamic cropping where both the size of the crop and the position of the crop within the frame, move as the video is played and saliency is tracked. Our results indicate that especially for videos of low initial memorability, the memorability score can be improved.
Polarity is all you need to learn and transfer faster
Mar 29, 2023Natural intelligences (NIs) thrive in a dynamic world - they learn quickly, sometimes with only a few samples. In contrast, Artificial intelligences (AIs) typically learn with prohibitive amount of training samples and computational power. What design principle difference between NI and AI could contribute to such a discrepancy? Here, we propose an angle from weight polarity: development processes initialize NIs with advantageous polarity configurations; as NIs grow and learn, synapse magnitudes update yet polarities are largely kept unchanged. We demonstrate with simulation and image classification tasks that if weight polarities are adequately set $\textit{a priori}$, then networks learn with less time and data. We also explicitly illustrate situations in which $\textit{a priori}$ setting the weight polarities is disadvantageous for networks. Our work illustrates the value of weight polarities from the perspective of statistical and computational efficiency during learning.
Towards Robust Recommender Systems via Triple Cooperative Defense
Oct 25, 2022Recommender systems are often susceptible to well-crafted fake profiles, leading to biased recommendations. The wide application of recommender systems makes studying the defense against attack necessary. Among existing defense methods, data-processing-based methods inevitably exclude normal samples, while model-based methods struggle to enjoy both generalization and robustness. Considering the above limitations, we suggest integrating data processing and robust model and propose a general framework, Triple Cooperative Defense (TCD), which cooperates to improve model robustness through the co-training of three models. Specifically, in each round of training, we sequentially use the high-confidence prediction ratings (consistent ratings) of any two models as auxiliary training data for the remaining model, and the three models cooperatively improve recommendation robustness. Notably, TCD adds pseudo label data instead of deleting abnormal data, which avoids the cleaning of normal data, and the cooperative training of the three models is also beneficial to model generalization. Through extensive experiments with five poisoning attacks on three real-world datasets, the results show that the robustness improvement of TCD significantly outperforms baselines. It is worth mentioning that TCD is also beneficial for model generalizations.
Why Do Networks Need Negative Weights?
Aug 05, 2022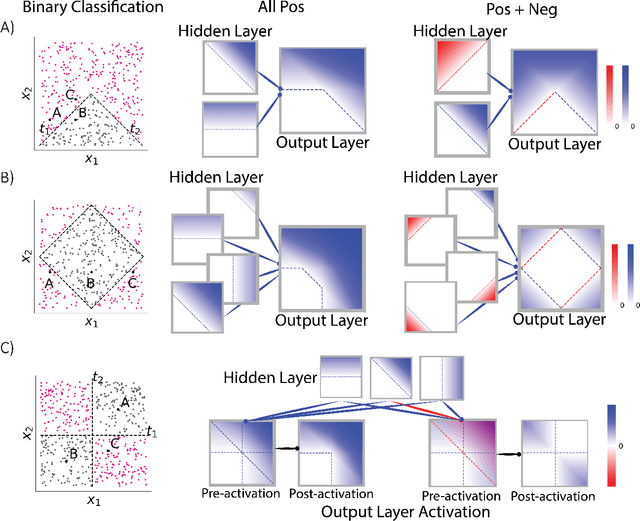
Why do networks have negative weights at all? The answer is: to learn more functions. We mathematically prove that deep neural networks with all non-negative weights are not universal approximators. This fundamental result is assumed by much of the deep learning literature without previously proving the result and demonstrating its necessity.