 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRiffusion: Draft-and-Refine Process Parallelizes Diffusion Models with Ease
Mar 26, 2026Diffusion models have achieved remarkable success in generating high-fidelity content but suffer from slow, iterative sampling, resulting in high latency that limits their use in interactive applications. We introduce DRiffusion, a parallel sampling framework that parallelizes diffusion inference through a draft-and-refine process. DRiffusion employs skip transitions to generate multiple draft states for future timesteps and computes their corresponding noises in parallel, which are then used in the standard denoising process to produce refined results. Theoretically, our method achieves an acceleration rate of $\tfrac{1}{n}$ or $\tfrac{2}{n+1}$, depending on whether the conservative or aggressive mode is used, where $n$ denotes the number of devices. Empirically, DRiffusion attains 1.4$\times$-3.7$\times$ speedup across multiple diffusion models while incur minimal degradation in generation quality: on MS-COCO dataset, both FID and CLIP remain largely on par with those of the original model, while PickScore and HPSv2.1 show only minor average drops of 0.17 and 0.43, respectively. These results verify that DRiffusion delivers substantial acceleration and preserves perceptual quality.
IDPruner: Harmonizing Importance and Diversity in Visual Token Pruning for MLLMs
Feb 10, 2026Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities, yet they encounter significant computational bottlenecks due to the massive volume of visual tokens. Consequently, visual token pruning, which substantially reduces the token count, has emerged as a critical technique for accelerating MLLM inference. Existing approaches focus on token importance, diversity, or an intuitive combination of both, without a principled framework for their optimal integration. To address this issue, we first conduct a systematic analysis to characterize the trade-off between token importance and semantic diversity. Guided by this analysis, we propose the \textbf{I}mportance and \textbf{D}iversity Pruner (\textbf{IDPruner}), which leverages the Maximal Marginal Relevance (MMR) algorithm to achieve a Pareto-optimal balance between these two objectives. Crucially, our method operates without requiring attention maps, ensuring full compatibility with FlashAttention and efficient deployment via one-shot pruning. We conduct extensive experiments across various model architectures and multimodal benchmarks, demonstrating that IDPruner achieves state-of-the-art performance and superior generalization across diverse architectures and tasks. Notably, on Qwen2.5-VL-7B-Instruct, IDPruner retains 95.18\% of baseline performance when pruning 75\% of the tokens, and still maintains 86.40\% even under an extreme 90\% pruning ratio. Our code is available at https://github.com/Tencent/AngelSlim.
Efficient Paths and Dense Rewards: Probabilistic Flow Reasoning for Large Language Models
Jan 14, 2026High-quality chain-of-thought has demonstrated strong potential for unlocking the reasoning capabilities of large language models. However, current paradigms typically treat the reasoning process as an indivisible sequence, lacking an intrinsic mechanism to quantify step-wise information gain. This granularity gap manifests in two limitations: inference inefficiency from redundant exploration without explicit guidance, and optimization difficulty due to sparse outcome supervision or costly external verifiers. In this work, we propose CoT-Flow, a framework that reconceptualizes discrete reasoning steps as a continuous probabilistic flow, quantifying the contribution of each step toward the ground-truth answer. Built on this formulation, CoT-Flow enables two complementary methodologies: flow-guided decoding, which employs a greedy flow-based decoding strategy to extract information-efficient reasoning paths, and flow-based reinforcement learning, which constructs a verifier-free dense reward function. Experiments on challenging benchmarks demonstrate that CoT-Flow achieves a superior balance between inference efficiency and reasoning performance.
InstCache: A Predictive Cache for LLM Serving
Nov 21, 2024
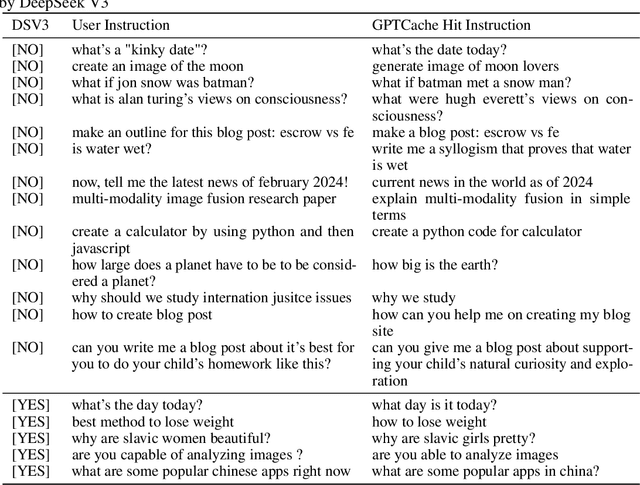

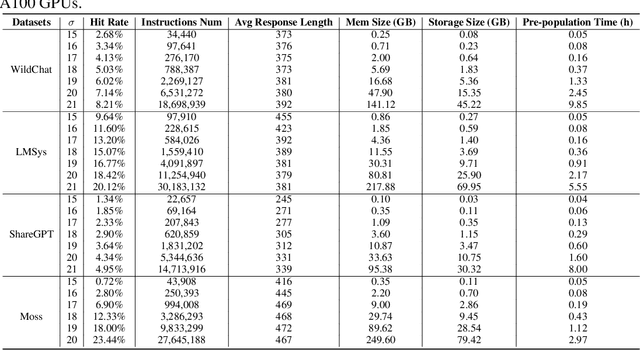
Large language models are revolutionizing every aspect of human life. However, the unprecedented power comes at the cost of significant computing intensity, suggesting long latency and large energy footprint. Key-Value Cache and Semantic Cache have been proposed as a solution to the above problem, but both suffer from limited scalability due to significant memory cost for each token or instruction embeddings. Motivated by the observations that most instructions are short, repetitive and predictable by LLMs, we propose to predict user-instructions by an instruction-aligned LLM and store them in a predictive cache, so-called InstCache. We introduce an instruction pre-population algorithm based on the negative log likelihood of instructions, determining the cache size with regard to the hit rate. The proposed InstCache is efficiently implemented as a hash table with minimal lookup latency for deployment. Experimental results show that InstCache can achieve up to 51.34% hit rate on LMSys dataset, which corresponds to a 2x speedup, at a memory cost of only 4.5GB.
AlignedKV: Reducing Memory Access of KV-Cache with Precision-Aligned Quantization
Sep 25, 2024



Model quantization has become a crucial technique to address the issues of large memory consumption and long inference times associated with LLMs. Mixed-precision quantization, which distinguishes between important and unimportant parameters, stands out among numerous quantization schemes as it achieves a balance between precision and compression rate. However, existing approaches can only identify important parameters through qualitative analysis and manual experiments without quantitatively analyzing how their importance is determined. We propose a new criterion, so-called 'precision alignment', to build a quantitative framework to holistically evaluate the importance of parameters in mixed-precision quantization. Our observations on floating point addition under various real-world scenarios suggest that two addends should have identical precision, otherwise the information in the higher-precision number will be wasted. Such an observation offers an essential principle to determine the precision of each parameter in matrix multiplication operation. As the first step towards applying the above discovery to large model inference, we develop a dynamic KV-Cache quantization technique to effectively reduce memory access latency. Different from existing quantization approaches that focus on memory saving, this work directly aims to accelerate LLM inference through quantifying floating numbers. The proposed technique attains a 25% saving of memory access and delivers up to 1.3x speedup in the computation of attention in the decoding phase of LLM, with almost no loss of precision.
CQIL: Inference Latency Optimization with Concurrent Computation of Quasi-Independent Layers
Apr 10, 2024The fast-growing large scale language models are delivering unprecedented performance on almost all natural language processing tasks. However, the effectiveness of large language models are reliant on an exponentially increasing number of parameters. The overwhelming computation complexity incurs a high inference latency that negatively affects user experience. Existing methods to improve inference efficiency, such as tensor parallelism and quantization, target to reduce per-layer computing latency, yet overlook the cumulative latency due to the number of layers. Recent works on reducing the cumulative latency through layer removing, however, lead to significant performance drop. Motivated by the similarity of inputs among adjacent layers, we propose to identify quasi-independent layers, which can be concurrently computed to significantly decrease inference latency. We also introduce a bypassing technique to mitigate the effect of information loss. Empirical experiments of the proposed approach on the LLaMA models confirm that Concurrent Computation of Quasi-Independent Layers (CQIL) can reduce latency by up to 48.3% on the LLaMA-33B model, while maintaining a close level of performance.
A Multi-Level Framework for Accelerating Training Transformer Models
Apr 07, 2024The fast growing capabilities of large-scale deep learning models, such as Bert, GPT and ViT, are revolutionizing the landscape of NLP, CV and many other domains. Training such models, however, poses an unprecedented demand for computing power, which incurs exponentially increasing energy cost and carbon dioxide emissions. It is thus critical to develop efficient training solutions to reduce the training costs. Motivated by a set of key observations of inter- and intra-layer similarities among feature maps and attentions that can be identified from typical training processes, we propose a multi-level framework for training acceleration. Specifically, the framework is based on three basic operators, Coalescing, De-coalescing and Interpolation, which can be orchestrated to build a multi-level training framework. The framework consists of a V-cycle training process, which progressively down- and up-scales the model size and projects the parameters between adjacent levels of models via coalescing and de-coalescing. The key idea is that a smaller model that can be trained for fast convergence and the trained parameters provides high-qualities intermediate solutions for the next level larger network. The interpolation operator is designed to break the symmetry of neurons incurred by de-coalescing for better convergence performance. Our experiments on transformer-based language models (e.g. Bert, GPT) as well as a vision model (e.g. DeiT) prove that the proposed framework reduces the computational cost by about 20% on training BERT/GPT-Base models and up to 51.6% on training the BERT-Large model while preserving the performance.
TCGAN: Convolutional Generative Adversarial Network for Time Series Classification and Clustering
Sep 09, 2023Recent works have demonstrated the superiority of supervised Convolutional Neural Networks (CNNs) in learning hierarchical representations from time series data for successful classification. These methods require sufficiently large labeled data for stable learning, however acquiring high-quality labeled time series data can be costly and potentially infeasible. Generative Adversarial Networks (GANs) have achieved great success in enhancing unsupervised and semi-supervised learning. Nonetheless, to our best knowledge, it remains unclear how effectively GANs can serve as a general-purpose solution to learn representations for time series recognition, i.e., classification and clustering. The above considerations inspire us to introduce a Time-series Convolutional GAN (TCGAN). TCGAN learns by playing an adversarial game between two one-dimensional CNNs (i.e., a generator and a discriminator) in the absence of label information. Parts of the trained TCGAN are then reused to construct a representation encoder to empower linear recognition methods. We conducted comprehensive experiments on synthetic and real-world datasets. The results demonstrate that TCGAN is faster and more accurate than existing time-series GANs. The learned representations enable simple classification and clustering methods to achieve superior and stable performance. Furthermore, TCGAN retains high efficacy in scenarios with few-labeled and imbalanced-labeled data. Our work provides a promising path to effectively utilize abundant unlabeled time series data.
A Spatiotemporal Deep Neural Network for Fine-Grained Multi-Horizon Wind Prediction
Sep 09, 2023The prediction of wind in terms of both wind speed and direction, which has a crucial impact on many real-world applications like aviation and wind power generation, is extremely challenging due to the high stochasticity and complicated correlation in the weather data. Existing methods typically focus on a sub-set of influential factors and thus lack a systematic treatment of the problem. In addition, fine-grained forecasting is essential for efficient industry operations, but has been less attended in the literature. In this work, we propose a novel data-driven model, Multi-Horizon SpatioTemporal Network (MHSTN), generally for accurate and efficient fine-grained wind prediction. MHSTN integrates multiple deep neural networks targeting different factors in a sequence-to-sequence (Seq2Seq) backbone to effectively extract features from various data sources and produce multi-horizon predictions for all sites within a given region. MHSTN is composed of four major modules. First, a temporal module fuses coarse-grained forecasts derived by Numerical Weather Prediction (NWP) and historical on-site observation data at stations so as to leverage both global and local atmospheric information. Second, a spatial module exploits spatial correlation by modeling the joint representation of all stations. Third, an ensemble module weighs the above two modules for final predictions. Furthermore, a covariate selection module automatically choose influential meteorological variables as initial input. MHSTN is already integrated into the scheduling platform of one of the busiest international airports of China. The evaluation results demonstrate that our model outperforms competitors by a significant margin.
DetNet: A Backbone network for Object Detection
Apr 19, 2018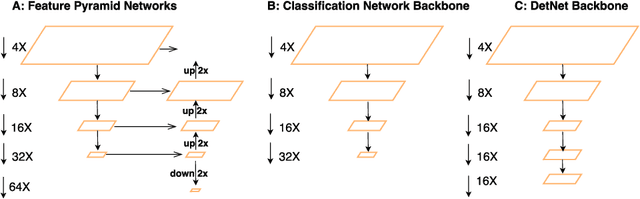
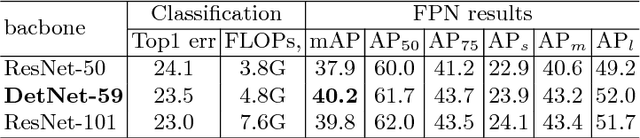
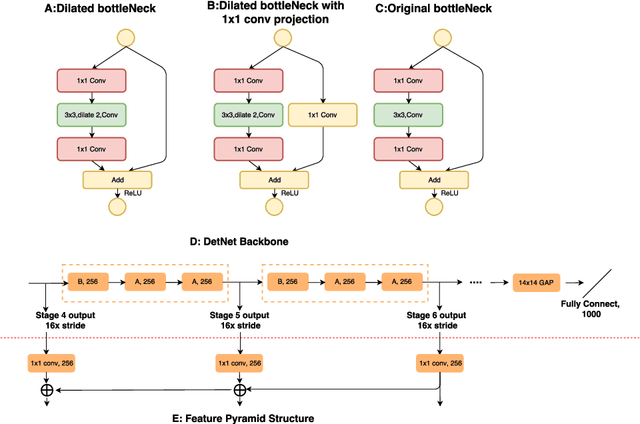

Recent CNN based object detectors, no matter one-stage methods like YOLO, SSD, and RetinaNe or two-stage detectors like Faster R-CNN, R-FCN and FPN are usually trying to directly finetune from ImageNet pre-trained models designed for image classification. There has been little work discussing on the backbone feature extractor specifically designed for the object detection. More importantly, there are several differences between the tasks of image classification and object detection. 1. Recent object detectors like FPN and RetinaNet usually involve extra stages against the task of image classification to handle the objects with various scales. 2. Object detection not only needs to recognize the category of the object instances but also spatially locate the position. Large downsampling factor brings large valid receptive field, which is good for image classification but compromises the object location ability. Due to the gap between the image classification and object detection, we propose DetNet in this paper, which is a novel backbone network specifically designed for object detection. Moreover, DetNet includes the extra stages against traditional backbone network for image classification, while maintains high spatial resolution in deeper layers. Without any bells and whistles, state-of-the-art results have been obtained for both object detection and instance segmentation on the MSCOCO benchmark based on our DetNet~(4.8G FLOPs) backbone. The code will be released for the reproduction.