 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep1X-3D: Towards High-Fidelity and Controllable Generation of Textured 3D Assets
May 12, 2025While generative artificial intelligence has advanced significantly across text, image, audio, and video domains, 3D generation remains comparatively underdeveloped due to fundamental challenges such as data scarcity, algorithmic limitations, and ecosystem fragmentation. To this end, we present Step1X-3D, an open framework addressing these challenges through: (1) a rigorous data curation pipeline processing >5M assets to create a 2M high-quality dataset with standardized geometric and textural properties; (2) a two-stage 3D-native architecture combining a hybrid VAE-DiT geometry generator with an diffusion-based texture synthesis module; and (3) the full open-source release of models, training code, and adaptation modules. For geometry generation, the hybrid VAE-DiT component produces TSDF representations by employing perceiver-based latent encoding with sharp edge sampling for detail preservation. The diffusion-based texture synthesis module then ensures cross-view consistency through geometric conditioning and latent-space synchronization. Benchmark results demonstrate state-of-the-art performance that exceeds existing open-source methods, while also achieving competitive quality with proprietary solutions. Notably, the framework uniquely bridges the 2D and 3D generation paradigms by supporting direct transfer of 2D control techniques~(e.g., LoRA) to 3D synthesis. By simultaneously advancing data quality, algorithmic fidelity, and reproducibility, Step1X-3D aims to establish new standards for open research in controllable 3D asset generation.
DiffSplat: Repurposing Image Diffusion Models for Scalable Gaussian Splat Generation
Jan 28, 2025Recent advancements in 3D content generation from text or a single image struggle with limited high-quality 3D datasets and inconsistency from 2D multi-view generation. We introduce DiffSplat, a novel 3D generative framework that natively generates 3D Gaussian splats by taming large-scale text-to-image diffusion models. It differs from previous 3D generative models by effectively utilizing web-scale 2D priors while maintaining 3D consistency in a unified model. To bootstrap the training, a lightweight reconstruction model is proposed to instantly produce multi-view Gaussian splat grids for scalable dataset curation. In conjunction with the regular diffusion loss on these grids, a 3D rendering loss is introduced to facilitate 3D coherence across arbitrary views. The compatibility with image diffusion models enables seamless adaptions of numerous techniques for image generation to the 3D realm. Extensive experiments reveal the superiority of DiffSplat in text- and image-conditioned generation tasks and downstream applications. Thorough ablation studies validate the efficacy of each critical design choice and provide insights into the underlying mechanism.
ManipGPT: Is Affordance Segmentation by Large Vision Models Enough for Articulated Object Manipulation?
Dec 13, 2024



Visual actionable affordance has emerged as a transformative approach in robotics, focusing on perceiving interaction areas prior to manipulation. Traditional methods rely on pixel sampling to identify successful interaction samples or processing pointclouds for affordance mapping. However, these approaches are computationally intensive and struggle to adapt to diverse and dynamic environments. This paper introduces ManipGPT, a framework designed to predict optimal interaction areas for articulated objects using a large pre-trained vision transformer (ViT). We created a dataset of 9.9k simulated and real images to bridge the sim-to-real gap and enhance real-world applicability. By fine-tuning the vision transformer on this small dataset, we significantly improved part-level affordance segmentation, adapting the model's in-context segmentation capabilities to robot manipulation scenarios. This enables effective manipulation across simulated and real-world environments by generating part-level affordance masks, paired with an impedance adaptation policy, sufficiently eliminating the need for complex datasets or perception systems.
Multi-modal Relation Distillation for Unified 3D Representation Learning
Jul 19, 2024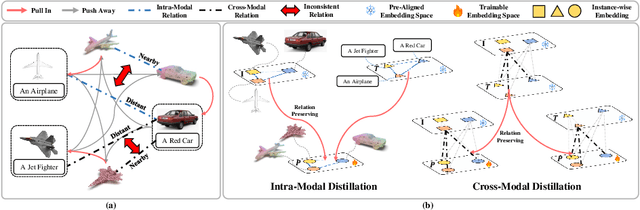

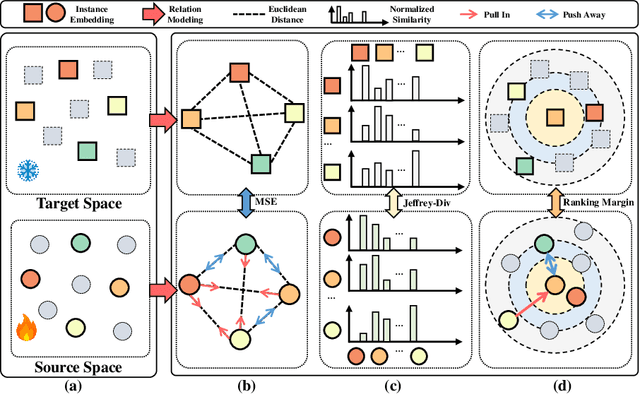

Recent advancements in multi-modal pre-training for 3D point clouds have demonstrated promising results by aligning heterogeneous features across 3D shapes and their corresponding 2D images and language descriptions. However, current straightforward solutions often overlook intricate structural relations among samples, potentially limiting the full capabilities of multi-modal learning. To address this issue, we introduce Multi-modal Relation Distillation (MRD), a tri-modal pre-training framework, which is designed to effectively distill reputable large Vision-Language Models (VLM) into 3D backbones. MRD aims to capture both intra-relations within each modality as well as cross-relations between different modalities and produce more discriminative 3D shape representations. Notably, MRD achieves significant improvements in downstream zero-shot classification tasks and cross-modality retrieval tasks, delivering new state-of-the-art performance.
4K4DGen: Panoramic 4D Generation at 4K Resolution
Jun 19, 2024
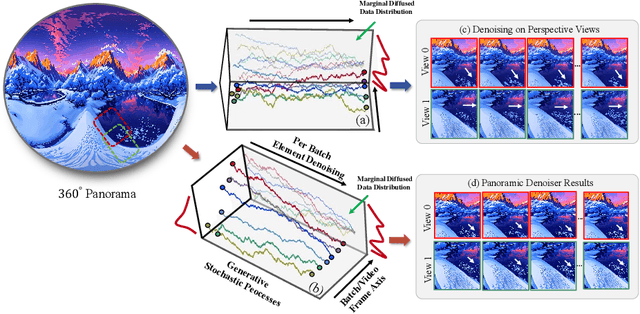

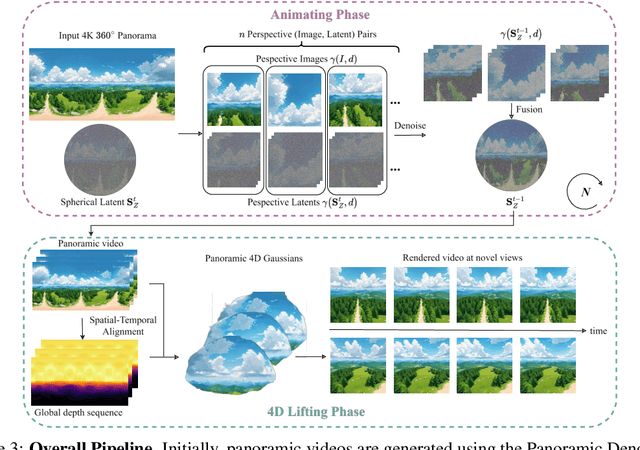
The blooming of virtual reality and augmented reality (VR/AR) technologies has driven an increasing demand for the creation of high-quality, immersive, and dynamic environments. However, existing generative techniques either focus solely on dynamic objects or perform outpainting from a single perspective image, failing to meet the needs of VR/AR applications. In this work, we tackle the challenging task of elevating a single panorama to an immersive 4D experience. For the first time, we demonstrate the capability to generate omnidirectional dynamic scenes with 360-degree views at 4K resolution, thereby providing an immersive user experience. Our method introduces a pipeline that facilitates natural scene animations and optimizes a set of 4D Gaussians using efficient splatting techniques for real-time exploration. To overcome the lack of scene-scale annotated 4D data and models, especially in panoramic formats, we propose a novel Panoramic Denoiser that adapts generic 2D diffusion priors to animate consistently in 360-degree images, transforming them into panoramic videos with dynamic scenes at targeted regions. Subsequently, we elevate the panoramic video into a 4D immersive environment while preserving spatial and temporal consistency. By transferring prior knowledge from 2D models in the perspective domain to the panoramic domain and the 4D lifting with spatial appearance and geometry regularization, we achieve high-quality Panorama-to-4D generation at a resolution of (4096 $\times$ 2048) for the first time. See the project website at https://4k4dgen.github.io.
HumanSplat: Generalizable Single-Image Human Gaussian Splatting with Structure Priors
Jun 18, 2024Despite recent advancements in high-fidelity human reconstruction techniques, the requirements for densely captured images or time-consuming per-instance optimization significantly hinder their applications in broader scenarios. To tackle these issues, we present HumanSplat which predicts the 3D Gaussian Splatting properties of any human from a single input image in a generalizable manner. In particular, HumanSplat comprises a 2D multi-view diffusion model and a latent reconstruction transformer with human structure priors that adeptly integrate geometric priors and semantic features within a unified framework. A hierarchical loss that incorporates human semantic information is further designed to achieve high-fidelity texture modeling and better constrain the estimated multiple views. Comprehensive experiments on standard benchmarks and in-the-wild images demonstrate that HumanSplat surpasses existing state-of-the-art methods in achieving photorealistic novel-view synthesis.
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Apr 18, 2024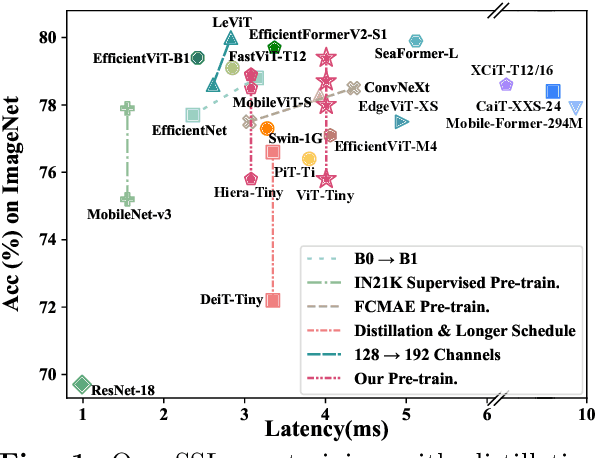
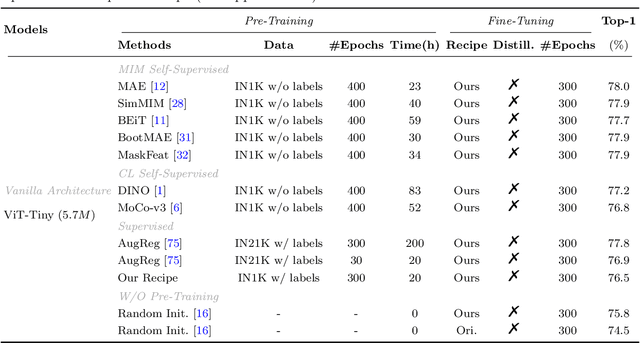

Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) in computer vision has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the extremely simple ViTs' fine-tuning performance with a small-scale architecture can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology with sophisticated components introduced. By carefully adapting various typical MIM pre-training methods to this lightweight regime and comparing them with the contrastive learning (CL) pre-training on various downstream image classification and dense prediction tasks, we systematically observe different behaviors between MIM and CL with respect to the downstream fine-tuning data scales. Furthermore, we analyze the frozen features under linear probing evaluation and also the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory fine-tuning performance on data-insufficient downstream tasks. This finding is naturally a guide to choosing appropriate distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments on various vision tasks demonstrate the effectiveness of our observation-analysis-solution flow. In particular, our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design (5.7M/6.5M) can achieve 79.4%/78.9% top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K semantic segmentation task (42.8% mIoU) and LaSOT visual tracking task (66.1% AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
HMD-Poser: On-Device Real-time Human Motion Tracking from Scalable Sparse Observations
Mar 06, 2024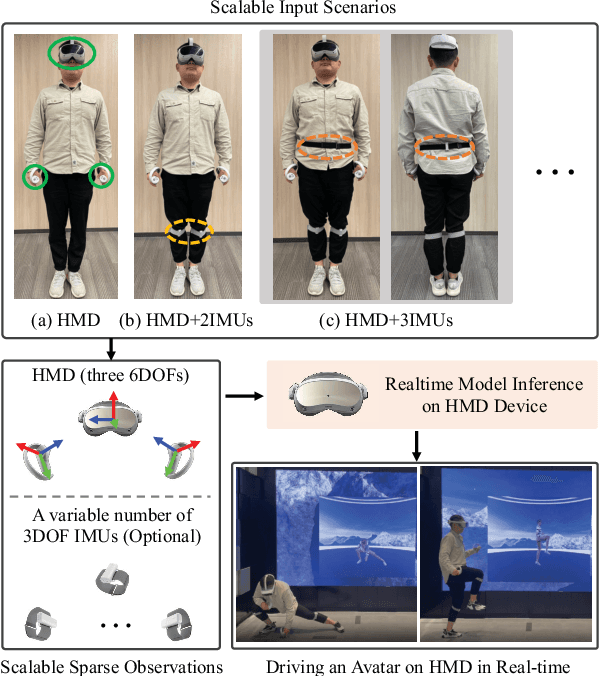
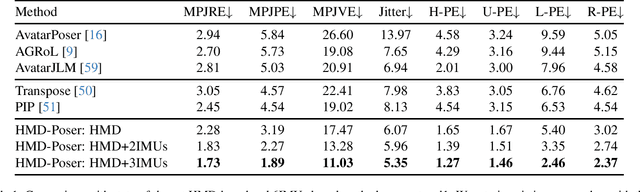
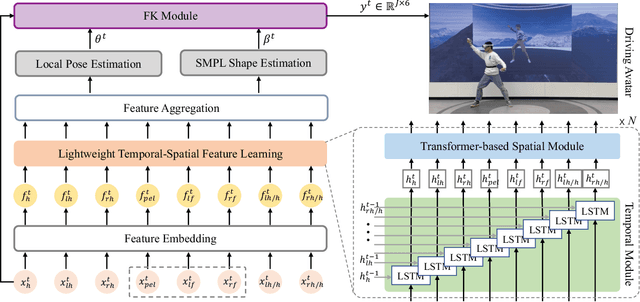
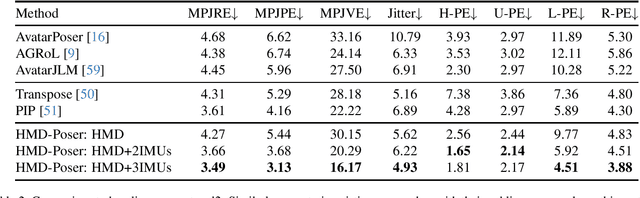
It is especially challenging to achieve real-time human motion tracking on a standalone VR Head-Mounted Display (HMD) such as Meta Quest and PICO. In this paper, we propose HMD-Poser, the first unified approach to recover full-body motions using scalable sparse observations from HMD and body-worn IMUs. In particular, it can support a variety of input scenarios, such as HMD, HMD+2IMUs, HMD+3IMUs, etc. The scalability of inputs may accommodate users' choices for both high tracking accuracy and easy-to-wear. A lightweight temporal-spatial feature learning network is proposed in HMD-Poser to guarantee that the model runs in real-time on HMDs. Furthermore, HMD-Poser presents online body shape estimation to improve the position accuracy of body joints. Extensive experimental results on the challenging AMASS dataset show that HMD-Poser achieves new state-of-the-art results in both accuracy and real-time performance. We also build a new free-dancing motion dataset to evaluate HMD-Poser's on-device performance and investigate the performance gap between synthetic data and real-captured sensor data. Finally, we demonstrate our HMD-Poser with a real-time Avatar-driving application on a commercial HMD. Our code and free-dancing motion dataset are available https://pico-ai-team.github.io/hmd-poser
GMM: Delving into Gradient Aware and Model Perceive Depth Mining for Monocular 3D Detection
Jun 30, 2023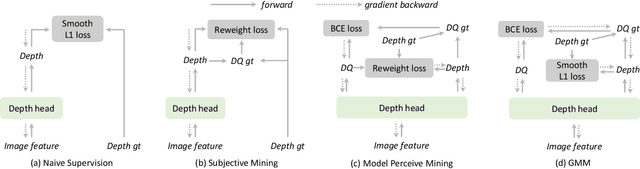
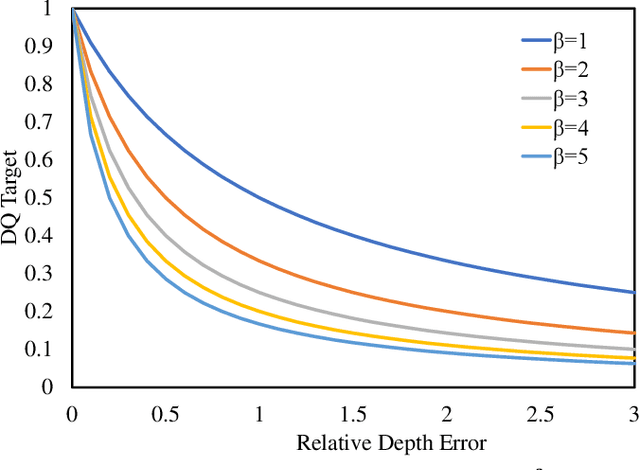
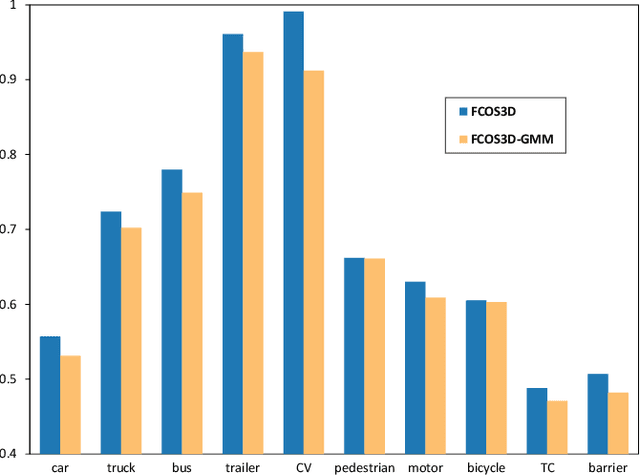
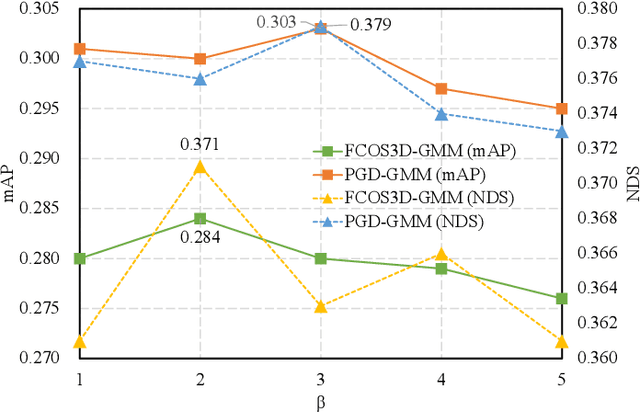
Depth perception is a crucial component of monoc-ular 3D detection tasks that typically involve ill-posed problems. In light of the success of sample mining techniques in 2D object detection, we propose a simple yet effective mining strategy for improving depth perception in 3D object detection. Concretely, we introduce a plain metric to evaluate the quality of depth predictions, which chooses the mined sample for the model. Moreover, we propose a Gradient-aware and Model-perceive Mining strategy (GMM) for depth learning, which exploits the predicted depth quality for better depth learning through easy mining. GMM is a general strategy that can be readily applied to several state-of-the-art monocular 3D detectors, improving the accuracy of depth prediction. Extensive experiments on the nuScenes dataset demonstrate that the proposed methods significantly improve the performance of 3D object detection while outperforming other state-of-the-art sample mining techniques by a considerable margin. On the nuScenes benchmark, GMM achieved the state-of-the-art (42.1% mAP and 47.3% NDS) performance in monocular object detection.
Dynamic Grained Encoder for Vision Transformers
Jan 10, 2023Transformers, the de-facto standard for language modeling, have been recently applied for vision tasks. This paper introduces sparse queries for vision transformers to exploit the intrinsic spatial redundancy of natural images and save computational costs. Specifically, we propose a Dynamic Grained Encoder for vision transformers, which can adaptively assign a suitable number of queries to each spatial region. Thus it achieves a fine-grained representation in discriminative regions while keeping high efficiency. Besides, the dynamic grained encoder is compatible with most vision transformer frameworks. Without bells and whistles, our encoder allows the state-of-the-art vision transformers to reduce computational complexity by 40%-60% while maintaining comparable performance on image classification. Extensive experiments on object detection and segmentation further demonstrate the generalizability of our approach. Code is available at https://github.com/StevenGrove/vtpack.