 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotif-2-12.7B-Reasoning: A Practitioner's Guide to RL Training Recipes
Dec 11, 2025We introduce Motif-2-12.7B-Reasoning, a 12.7B parameter language model designed to bridge the gap between open-weight systems and proprietary frontier models in complex reasoning and long-context understanding. Addressing the common challenges of model collapse and training instability in reasoning adaptation, we propose a comprehensive, reproducible training recipe spanning system, data, and algorithmic optimizations. Our approach combines memory-efficient infrastructure for 64K-token contexts using hybrid parallelism and kernel-level optimizations with a two-stage Supervised Fine-Tuning (SFT) curriculum that mitigates distribution mismatch through verified, aligned synthetic data. Furthermore, we detail a robust Reinforcement Learning Fine-Tuning (RLFT) pipeline that stabilizes training via difficulty-aware data filtering and mixed-policy trajectory reuse. Empirical results demonstrate that Motif-2-12.7B-Reasoning achieves performance comparable to models with significantly larger parameter counts across mathematics, coding, and agentic benchmarks, offering the community a competitive open model and a practical blueprint for scaling reasoning capabilities under realistic compute constraints.
Motif 2 12.7B technical report
Nov 07, 2025We introduce Motif-2-12.7B, a new open-weight foundation model that pushes the efficiency frontier of large language models by combining architectural innovation with system-level optimization. Designed for scalable language understanding and robust instruction generalization under constrained compute budgets, Motif-2-12.7B builds upon Motif-2.6B with the integration of Grouped Differential Attention (GDA), which improves representational efficiency by disentangling signal and noise-control attention pathways. The model is pre-trained on 5.5 trillion tokens spanning diverse linguistic, mathematical, scientific, and programming domains using a curriculum-driven data scheduler that gradually changes the data composition ratio. The training system leverages the MuonClip optimizer alongside custom high-performance kernels, including fused PolyNorm activations and the Parallel Muon algorithm, yielding significant throughput and memory efficiency gains in large-scale distributed environments. Post-training employs a three-stage supervised fine-tuning pipeline that successively enhances general instruction adherence, compositional understanding, and linguistic precision. Motif-2-12.7B demonstrates competitive performance across diverse benchmarks, showing that thoughtful architectural scaling and optimized training design can rival the capabilities of much larger models.
SIDA: Synthetic Image Driven Zero-shot Domain Adaptation
Jul 24, 2025



Zero-shot domain adaptation is a method for adapting a model to a target domain without utilizing target domain image data. To enable adaptation without target images, existing studies utilize CLIP's embedding space and text description to simulate target-like style features. Despite the previous achievements in zero-shot domain adaptation, we observe that these text-driven methods struggle to capture complex real-world variations and significantly increase adaptation time due to their alignment process. Instead of relying on text descriptions, we explore solutions leveraging image data, which provides diverse and more fine-grained style cues. In this work, we propose SIDA, a novel and efficient zero-shot domain adaptation method leveraging synthetic images. To generate synthetic images, we first create detailed, source-like images and apply image translation to reflect the style of the target domain. We then utilize the style features of these synthetic images as a proxy for the target domain. Based on these features, we introduce Domain Mix and Patch Style Transfer modules, which enable effective modeling of real-world variations. In particular, Domain Mix blends multiple styles to expand the intra-domain representations, and Patch Style Transfer assigns different styles to individual patches. We demonstrate the effectiveness of our method by showing state-of-the-art performance in diverse zero-shot adaptation scenarios, particularly in challenging domains. Moreover, our approach achieves high efficiency by significantly reducing the overall adaptation time.
SynC: Synthetic Image Caption Dataset Refinement with One-to-many Mapping for Zero-shot Image Captioning
Jul 24, 2025

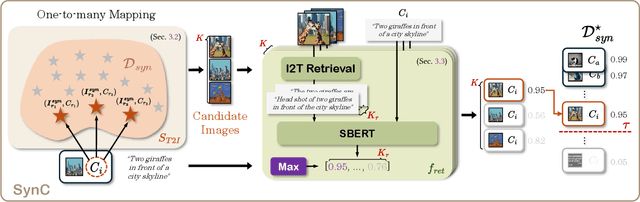

Zero-shot Image Captioning (ZIC) increasingly utilizes synthetic datasets generated by text-to-image (T2I) models to mitigate the need for costly manual annotation. However, these T2I models often produce images that exhibit semantic misalignments with their corresponding input captions (e.g., missing objects, incorrect attributes), resulting in noisy synthetic image-caption pairs that can hinder model training. Existing dataset pruning techniques are largely designed for removing noisy text in web-crawled data. However, these methods are ill-suited for the distinct challenges of synthetic data, where captions are typically well-formed, but images may be inaccurate representations. To address this gap, we introduce SynC, a novel framework specifically designed to refine synthetic image-caption datasets for ZIC. Instead of conventional filtering or regeneration, SynC focuses on reassigning captions to the most semantically aligned images already present within the synthetic image pool. Our approach employs a one-to-many mapping strategy by initially retrieving multiple relevant candidate images for each caption. We then apply a cycle-consistency-inspired alignment scorer that selects the best image by verifying its ability to retrieve the original caption via image-to-text retrieval. Extensive evaluations demonstrate that SynC consistently and significantly improves performance across various ZIC models on standard benchmarks (MS-COCO, Flickr30k, NoCaps), achieving state-of-the-art results in several scenarios. SynC offers an effective strategy for curating refined synthetic data to enhance ZIC.
CheckManual: A New Challenge and Benchmark for Manual-based Appliance Manipulation
Jun 11, 2025Correct use of electrical appliances has significantly improved human life quality. Unlike simple tools that can be manipulated with common sense, different parts of electrical appliances have specific functions defined by manufacturers. If we want the robot to heat bread by microwave, we should enable them to review the microwave manual first. From the manual, it can learn about component functions, interaction methods, and representative task steps about appliances. However, previous manual-related works remain limited to question-answering tasks while existing manipulation researchers ignore the manual's important role and fail to comprehend multi-page manuals. In this paper, we propose the first manual-based appliance manipulation benchmark CheckManual. Specifically, we design a large model-assisted human-revised data generation pipeline to create manuals based on CAD appliance models. With these manuals, we establish novel manual-based manipulation challenges, metrics, and simulator environments for model performance evaluation. Furthermore, we propose the first manual-based manipulation planning model ManualPlan to set up a group of baselines for the CheckManual benchmark.
ViPCap: Retrieval Text-Based Visual Prompts for Lightweight Image Captioning
Dec 26, 2024Recent lightweight image captioning models using retrieved data mainly focus on text prompts. However, previous works only utilize the retrieved text as text prompts, and the visual information relies only on the CLIP visual embedding. Because of this issue, there is a limitation that the image descriptions inherent in the prompt are not sufficiently reflected in the visual embedding space. To tackle this issue, we propose ViPCap, a novel retrieval text-based visual prompt for lightweight image captioning. ViPCap leverages the retrieved text with image information as visual prompts to enhance the ability of the model to capture relevant visual information. By mapping text prompts into the CLIP space and generating multiple randomized Gaussian distributions, our method leverages sampling to explore randomly augmented distributions and effectively retrieves the semantic features that contain image information. These retrieved features are integrated into the image and designated as the visual prompt, leading to performance improvements on the datasets such as COCO, Flickr30k, and NoCaps. Experimental results demonstrate that ViPCap significantly outperforms prior lightweight captioning models in efficiency and effectiveness, demonstrating the potential for a plug-and-play solution.
ManipGPT: Is Affordance Segmentation by Large Vision Models Enough for Articulated Object Manipulation?
Dec 13, 2024



Visual actionable affordance has emerged as a transformative approach in robotics, focusing on perceiving interaction areas prior to manipulation. Traditional methods rely on pixel sampling to identify successful interaction samples or processing pointclouds for affordance mapping. However, these approaches are computationally intensive and struggle to adapt to diverse and dynamic environments. This paper introduces ManipGPT, a framework designed to predict optimal interaction areas for articulated objects using a large pre-trained vision transformer (ViT). We created a dataset of 9.9k simulated and real images to bridge the sim-to-real gap and enhance real-world applicability. By fine-tuning the vision transformer on this small dataset, we significantly improved part-level affordance segmentation, adapting the model's in-context segmentation capabilities to robot manipulation scenarios. This enables effective manipulation across simulated and real-world environments by generating part-level affordance masks, paired with an impedance adaptation policy, sufficiently eliminating the need for complex datasets or perception systems.
IFCap: Image-like Retrieval and Frequency-based Entity Filtering for Zero-shot Captioning
Sep 26, 2024



Recent advancements in image captioning have explored text-only training methods to overcome the limitations of paired image-text data. However, existing text-only training methods often overlook the modality gap between using text data during training and employing images during inference. To address this issue, we propose a novel approach called Image-like Retrieval, which aligns text features with visually relevant features to mitigate the modality gap. Our method further enhances the accuracy of generated captions by designing a Fusion Module that integrates retrieved captions with input features. Additionally, we introduce a Frequency-based Entity Filtering technique that significantly improves caption quality. We integrate these methods into a unified framework, which we refer to as IFCap ($\textbf{I}$mage-like Retrieval and $\textbf{F}$requency-based Entity Filtering for Zero-shot $\textbf{Cap}$tioning). Through extensive experimentation, our straightforward yet powerful approach has demonstrated its efficacy, outperforming the state-of-the-art methods by a significant margin in both image captioning and video captioning compared to zero-shot captioning based on text-only training.