 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheckManual: A New Challenge and Benchmark for Manual-based Appliance Manipulation
Jun 11, 2025Correct use of electrical appliances has significantly improved human life quality. Unlike simple tools that can be manipulated with common sense, different parts of electrical appliances have specific functions defined by manufacturers. If we want the robot to heat bread by microwave, we should enable them to review the microwave manual first. From the manual, it can learn about component functions, interaction methods, and representative task steps about appliances. However, previous manual-related works remain limited to question-answering tasks while existing manipulation researchers ignore the manual's important role and fail to comprehend multi-page manuals. In this paper, we propose the first manual-based appliance manipulation benchmark CheckManual. Specifically, we design a large model-assisted human-revised data generation pipeline to create manuals based on CAD appliance models. With these manuals, we establish novel manual-based manipulation challenges, metrics, and simulator environments for model performance evaluation. Furthermore, we propose the first manual-based manipulation planning model ManualPlan to set up a group of baselines for the CheckManual benchmark.
Foundation Feature-Driven Online End-Effector Pose Estimation: A Marker-Free and Learning-Free Approach
Mar 18, 2025Accurate transformation estimation between camera space and robot space is essential. Traditional methods using markers for hand-eye calibration require offline image collection, limiting their suitability for online self-calibration. Recent learning-based robot pose estimation methods, while advancing online calibration, struggle with cross-robot generalization and require the robot to be fully visible. This work proposes a Foundation feature-driven online End-Effector Pose Estimation (FEEPE) algorithm, characterized by its training-free and cross end-effector generalization capabilities. Inspired by the zero-shot generalization capabilities of foundation models, FEEPE leverages pre-trained visual features to estimate 2D-3D correspondences derived from the CAD model and target image, enabling 6D pose estimation via the PnP algorithm. To resolve ambiguities from partial observations and symmetry, a multi-historical key frame enhanced pose optimization algorithm is introduced, utilizing temporal information for improved accuracy. Compared to traditional hand-eye calibration, FEEPE enables marker-free online calibration. Unlike robot pose estimation, it generalizes across robots and end-effectors in a training-free manner. Extensive experiments demonstrate its superior flexibility, generalization, and performance.
Gradient Deconfliction via Orthogonal Projections onto Subspaces For Multi-task Learning
Mar 05, 2025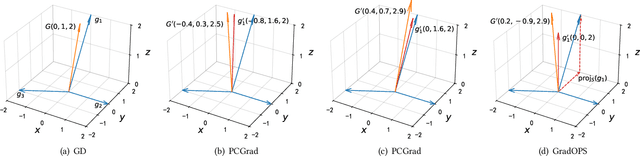
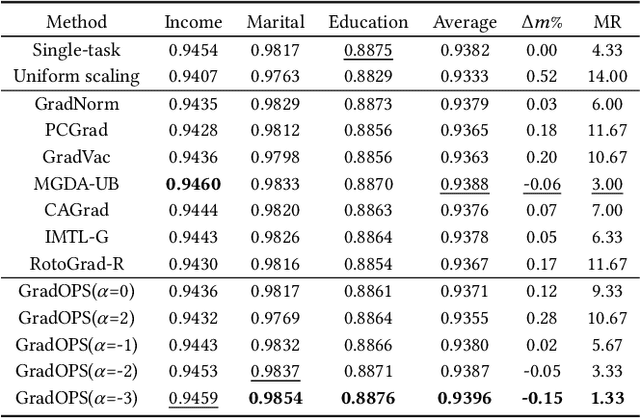

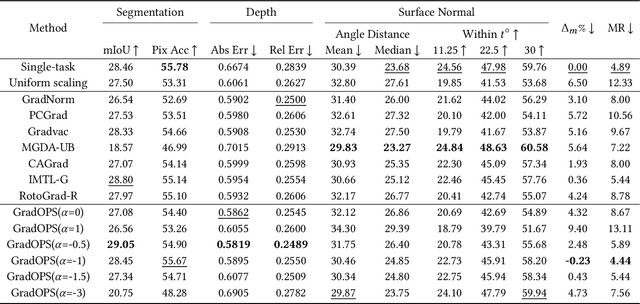
Although multi-task learning (MTL) has been a preferred approach and successfully applied in many real-world scenarios, MTL models are not guaranteed to outperform single-task models on all tasks mainly due to the negative effects of conflicting gradients among the tasks. In this paper, we fully examine the influence of conflicting gradients and further emphasize the importance and advantages of achieving non-conflicting gradients which allows simple but effective trade-off strategies among the tasks with stable performance. Based on our findings, we propose the Gradient Deconfliction via Orthogonal Projections onto Subspaces (GradOPS) spanned by other task-specific gradients. Our method not only solves all conflicts among the tasks, but can also effectively search for diverse solutions towards different trade-off preferences among the tasks. Theoretical analysis on convergence is provided, and performance of our algorithm is fully testified on multiple benchmarks in various domains. Results demonstrate that our method can effectively find multiple state-of-the-art solutions with different trade-off strategies among the tasks on multiple datasets.
OmniManip: Towards General Robotic Manipulation via Object-Centric Interaction Primitives as Spatial Constraints
Jan 07, 2025



The development of general robotic systems capable of manipulating in unstructured environments is a significant challenge. While Vision-Language Models(VLM) excel in high-level commonsense reasoning, they lack the fine-grained 3D spatial understanding required for precise manipulation tasks. Fine-tuning VLM on robotic datasets to create Vision-Language-Action Models(VLA) is a potential solution, but it is hindered by high data collection costs and generalization issues. To address these challenges, we propose a novel object-centric representation that bridges the gap between VLM's high-level reasoning and the low-level precision required for manipulation. Our key insight is that an object's canonical space, defined by its functional affordances, provides a structured and semantically meaningful way to describe interaction primitives, such as points and directions. These primitives act as a bridge, translating VLM's commonsense reasoning into actionable 3D spatial constraints. In this context, we introduce a dual closed-loop, open-vocabulary robotic manipulation system: one loop for high-level planning through primitive resampling, interaction rendering and VLM checking, and another for low-level execution via 6D pose tracking. This design ensures robust, real-time control without requiring VLM fine-tuning. Extensive experiments demonstrate strong zero-shot generalization across diverse robotic manipulation tasks, highlighting the potential of this approach for automating large-scale simulation data generation.
Explainable LLM-driven Multi-dimensional Distillation for E-Commerce Relevance Learning
Nov 20, 2024Effective query-item relevance modeling is pivotal for enhancing user experience and safeguarding user satisfaction in e-commerce search systems. Recently, benefiting from the vast inherent knowledge, Large Language Model (LLM) approach demonstrates strong performance and long-tail generalization ability compared with previous neural-based specialized relevance learning methods. Though promising, current LLM-based methods encounter the following inadequacies in practice: First, the massive parameters and computational demands make it difficult to be deployed online. Second, distilling LLM models to online models is a feasible direction, but the LLM relevance modeling is a black box, and its rich intrinsic knowledge is difficult to extract and apply online. To improve the interpretability of LLM and boost the performance of online relevance models via LLM, we propose an Explainable LLM-driven Multi-dimensional Distillation framework for e-commerce relevance learning, which comprises two core components: (1) An Explainable LLM for relevance modeling (ELLM-rele), which decomposes the relevance learning into intermediate steps and models relevance learning as a Chain-of-Thought (CoT) reasoning, thereby enhancing both interpretability and performance of LLM. (2) A Multi-dimensional Knowledge Distillation (MKD) architecture that transfers the knowledge of ELLM-rele to current deployable interaction-based and representation-based student models from both the relevance score distribution and CoT reasoning aspects. Through distilling the probabilistic and CoT reasoning knowledge, MKD improves both the semantic interaction and long-tail generalization abilities of student models. Extensive offline evaluations and online experiments on Taobao search ad scene demonstrate that our proposed framework significantly enhances e-commerce relevance learning performance and user experience.
EENMF: An End-to-End Neural Matching Framework for E-Commerce Sponsored Search
Dec 09, 2018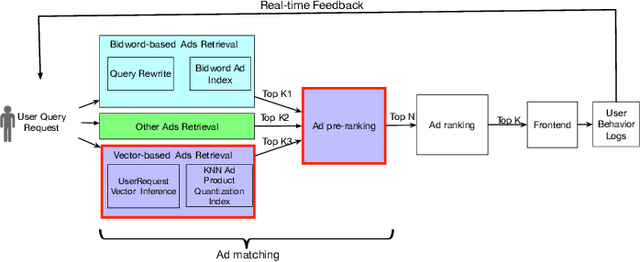
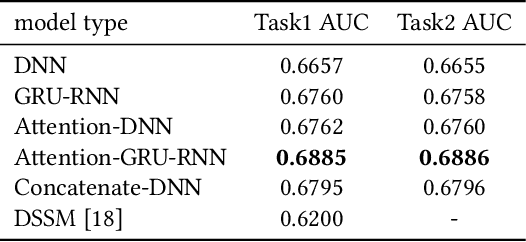
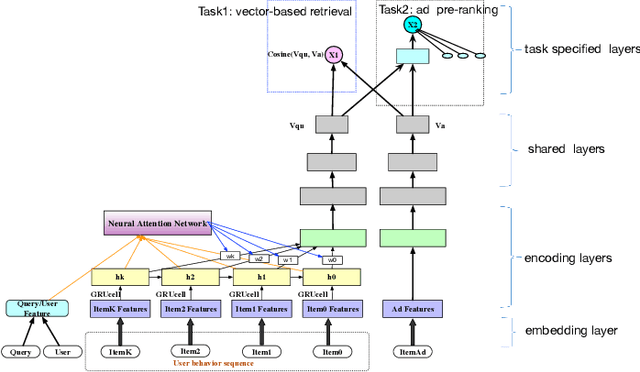
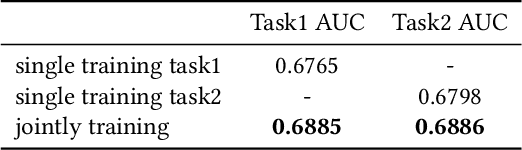
E-commerce sponsored search contributes an important part of revenue for the e-commerce company. In consideration of effectiveness and efficiency, a large-scale sponsored search system commonly adopts a multi-stage architecture. We name these stages as ad retrieval, ad pre-ranking and ad ranking. Ad retrieval and ad pre-ranking are collectively referred to as ad matching in this paper. We propose an end-to-end neural matching framework (EENMF) to model two tasks---vector-based ad retrieval and neural networks based ad pre-ranking. Under the deep matching framework, vector-based ad retrieval harnesses user recent behavior sequence to retrieve relevant ad candidates without the constraint of keyword bidding. Simultaneously, the deep model is employed to perform the global pre-ranking of ad candidates from multiple retrieval paths effectively and efficiently. Besides, the proposed model tries to optimize the pointwise cross-entropy loss which is consistent with the objective of predict models in the ranking stage. We conduct extensive evaluation to validate the performance of the proposed framework. In the real traffic of a large-scale e-commerce sponsored search, the proposed approach significantly outperforms the baseline.
Beyond Keywords and Relevance: A Personalized Ad Retrieval Framework in E-Commerce Sponsored Search
Apr 23, 2018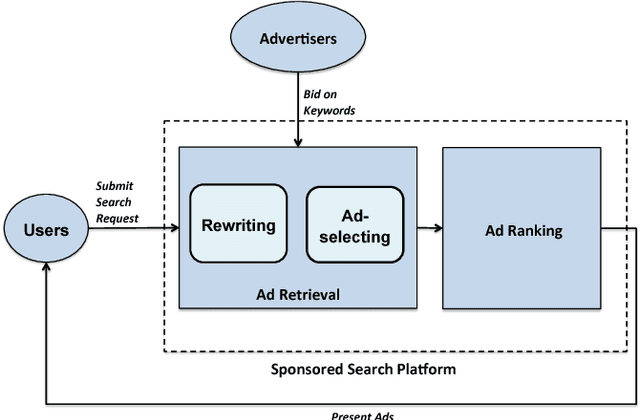

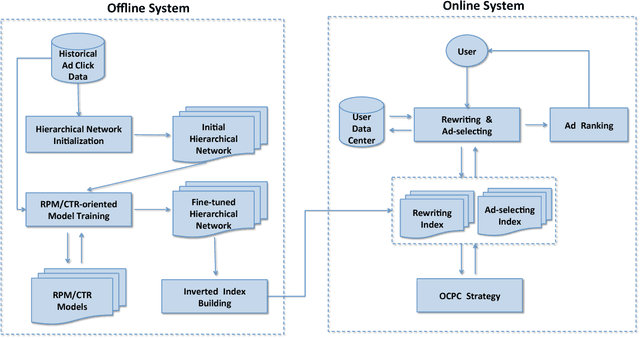
On most sponsored search platforms, advertisers bid on some keywords for their advertisements (ads). Given a search request, ad retrieval module rewrites the query into bidding keywords, and uses these keywords as keys to select Top N ads through inverted indexes. In this way, an ad will not be retrieved even if queries are related when the advertiser does not bid on corresponding keywords. Moreover, most ad retrieval approaches regard rewriting and ad-selecting as two separated tasks, and focus on boosting relevance between search queries and ads. Recently, in e-commerce sponsored search more and more personalized information has been introduced, such as user profiles, long-time and real-time clicks. Personalized information makes ad retrieval able to employ more elements (e.g. real-time clicks) as search signals and retrieval keys, however it makes ad retrieval more difficult to measure ads retrieved through different signals. To address these problems, we propose a novel ad retrieval framework beyond keywords and relevance in e-commerce sponsored search. Firstly, we employ historical ad click data to initialize a hierarchical network representing signals, keys and ads, in which personalized information is introduced. Then we train a model on top of the hierarchical network by learning the weights of edges. Finally we select the best edges according to the model, boosting RPM/CTR. Experimental results on our e-commerce platform demonstrate that our ad retrieval framework achieves good performance.