 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneMall: One Architecture, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Feb 02, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
OneMall: One Model, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Jan 29, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
Explainable LLM-driven Multi-dimensional Distillation for E-Commerce Relevance Learning
Nov 20, 2024Effective query-item relevance modeling is pivotal for enhancing user experience and safeguarding user satisfaction in e-commerce search systems. Recently, benefiting from the vast inherent knowledge, Large Language Model (LLM) approach demonstrates strong performance and long-tail generalization ability compared with previous neural-based specialized relevance learning methods. Though promising, current LLM-based methods encounter the following inadequacies in practice: First, the massive parameters and computational demands make it difficult to be deployed online. Second, distilling LLM models to online models is a feasible direction, but the LLM relevance modeling is a black box, and its rich intrinsic knowledge is difficult to extract and apply online. To improve the interpretability of LLM and boost the performance of online relevance models via LLM, we propose an Explainable LLM-driven Multi-dimensional Distillation framework for e-commerce relevance learning, which comprises two core components: (1) An Explainable LLM for relevance modeling (ELLM-rele), which decomposes the relevance learning into intermediate steps and models relevance learning as a Chain-of-Thought (CoT) reasoning, thereby enhancing both interpretability and performance of LLM. (2) A Multi-dimensional Knowledge Distillation (MKD) architecture that transfers the knowledge of ELLM-rele to current deployable interaction-based and representation-based student models from both the relevance score distribution and CoT reasoning aspects. Through distilling the probabilistic and CoT reasoning knowledge, MKD improves both the semantic interaction and long-tail generalization abilities of student models. Extensive offline evaluations and online experiments on Taobao search ad scene demonstrate that our proposed framework significantly enhances e-commerce relevance learning performance and user experience.
Demand Response Method Considering Multiple Types of Flexible Loads in Industrial Parks
May 24, 2022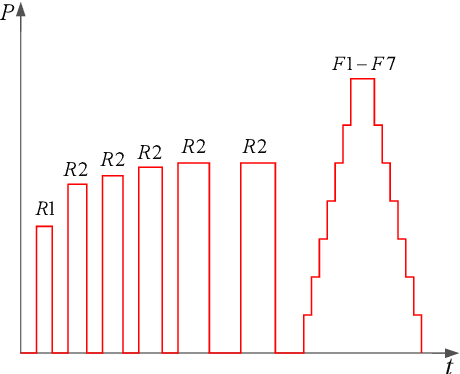

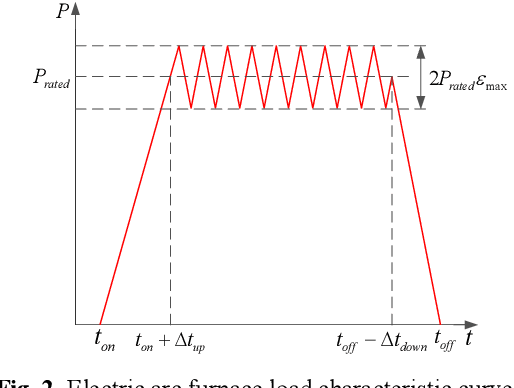

With the rapid development of the energy internet, the proportion of flexible loads in smart grid is getting much higher than before. It is highly important to model flexible loads based on demand response. Therefore, a new demand response method considering multiple flexible loads is proposed in this paper to character the integrated demand response (IDR) resources. Firstly, a physical process analytical deduction (PPAD) model is proposed to improve the classification of flexible loads in industrial parks. Scenario generation, data point augmentation, and smooth curves under various operating conditions are considered to enhance the applicability of the model. Secondly, in view of the strong volatility and poor modeling effect of Wasserstein-generative adversarial networks (WGAN), an improved WGAN-gradient penalty (IWGAN-GP) model is developed to get a faster convergence speed than traditional WGAN and generate a higher quality samples. Finally, the PPAD and IWGAN-GP models are jointly implemented to reveal the degree of correlation between flexible loads. Meanwhile, an intelligent offline database is built to deal with the impact of nonlinear factors in different response scenarios. Numerical examples have been performed with the results proving that the proposed method is significantly better than the existing technologies in reducing load modeling deviation and improving the responsiveness of park loads.
Enhancing Label Correlation Feedback in Multi-Label Text Classification via Multi-Task Learning
Jun 06, 2021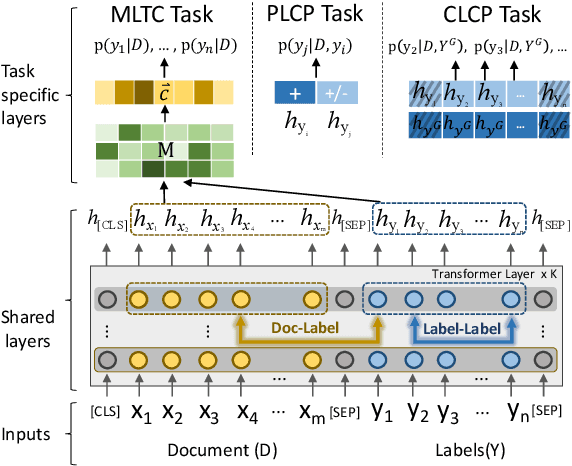
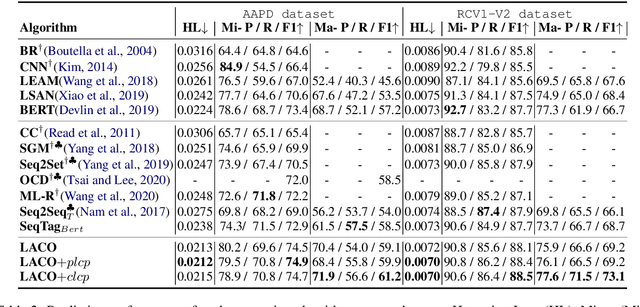
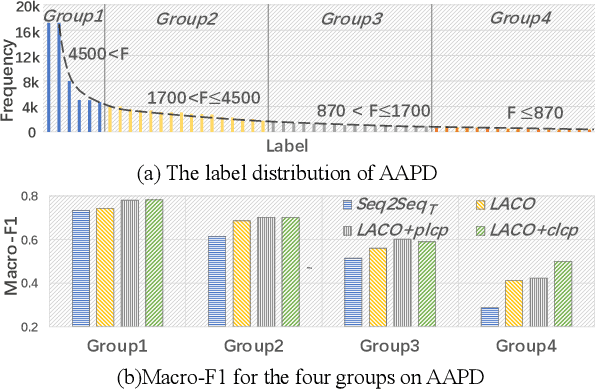
In multi-label text classification (MLTC), each given document is associated with a set of correlated labels. To capture label correlations, previous classifier-chain and sequence-to-sequence models transform MLTC to a sequence prediction task. However, they tend to suffer from label order dependency, label combination over-fitting and error propagation problems. To address these problems, we introduce a novel approach with multi-task learning to enhance label correlation feedback. We first utilize a joint embedding (JE) mechanism to obtain the text and label representation simultaneously. In MLTC task, a document-label cross attention (CA) mechanism is adopted to generate a more discriminative document representation. Furthermore, we propose two auxiliary label co-occurrence prediction tasks to enhance label correlation learning: 1) Pairwise Label Co-occurrence Prediction (PLCP), and 2) Conditional Label Co-occurrence Prediction (CLCP). Experimental results on AAPD and RCV1-V2 datasets show that our method outperforms competitive baselines by a large margin. We analyze low-frequency label performance, label dependency, label combination diversity and coverage speed to show the effectiveness of our proposed method on label correlation learning.