 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating the Language Bias for Visual Question Answering with fine-grained Causal Intervention
Oct 14, 2024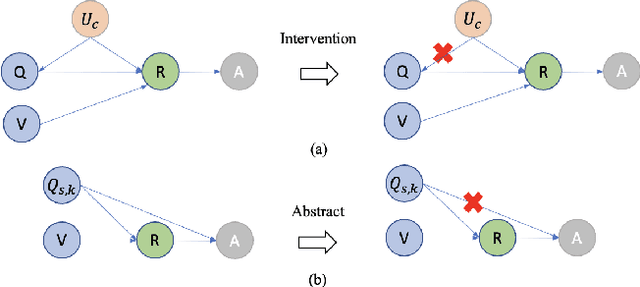
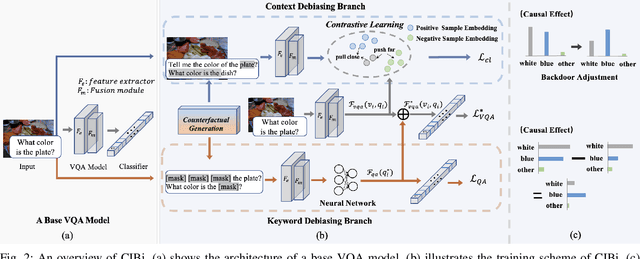
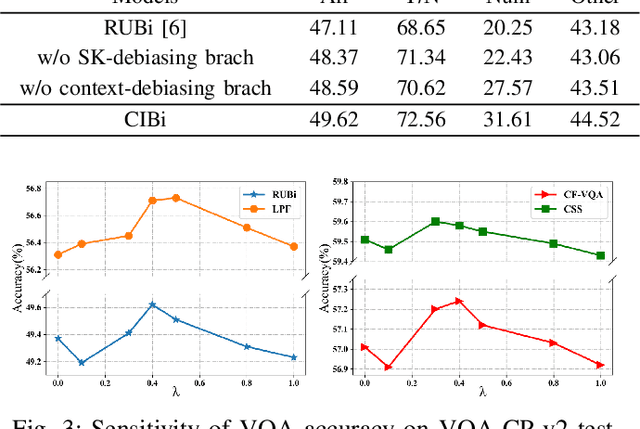
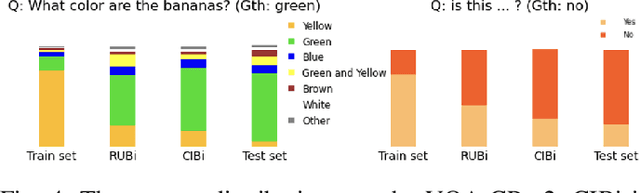
Despite the remarkable advancements in Visual Question Answering (VQA), the challenge of mitigating the language bias introduced by textual information remains unresolved. Previous approaches capture language bias from a coarse-grained perspective. However, the finer-grained information within a sentence, such as context and keywords, can result in different biases. Due to the ignorance of fine-grained information, most existing methods fail to sufficiently capture language bias. In this paper, we propose a novel causal intervention training scheme named CIBi to eliminate language bias from a finer-grained perspective. Specifically, we divide the language bias into context bias and keyword bias. We employ causal intervention and contrastive learning to eliminate context bias and improve the multi-modal representation. Additionally, we design a new question-only branch based on counterfactual generation to distill and eliminate keyword bias. Experimental results illustrate that CIBi is applicable to various VQA models, yielding competitive performance.
Fusion Makes Perfection: An Efficient Multi-Grained Matching Approach for Zero-Shot Relation Extraction
Jun 17, 2024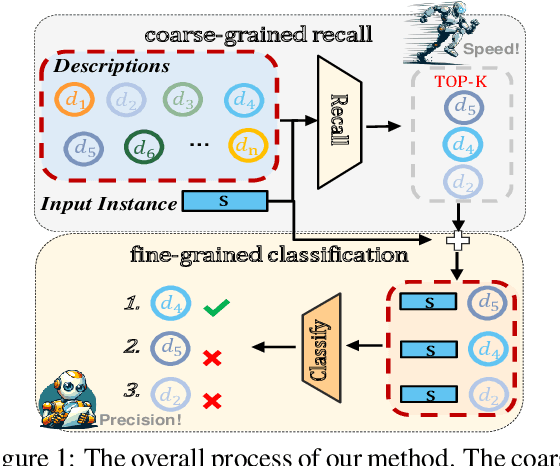
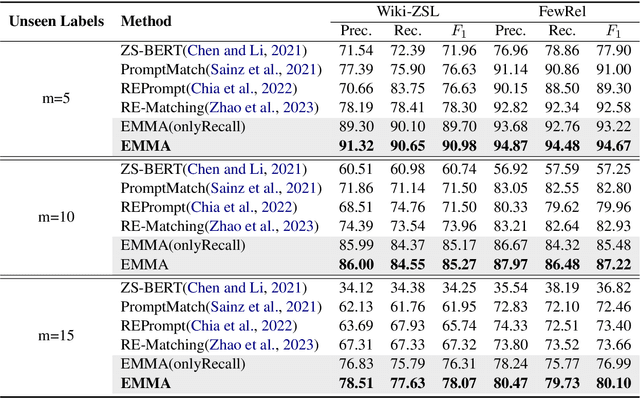
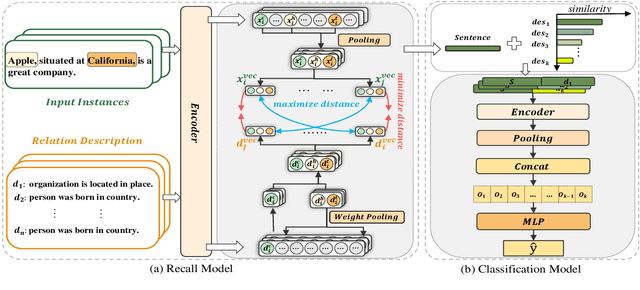
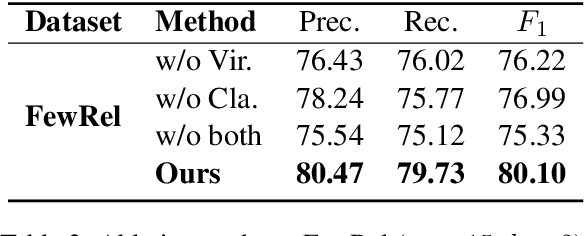
Predicting unseen relations that cannot be observed during the training phase is a challenging task in relation extraction. Previous works have made progress by matching the semantics between input instances and label descriptions. However, fine-grained matching often requires laborious manual annotation, and rich interactions between instances and label descriptions come with significant computational overhead. In this work, we propose an efficient multi-grained matching approach that uses virtual entity matching to reduce manual annotation cost, and fuses coarse-grained recall and fine-grained classification for rich interactions with guaranteed inference speed. Experimental results show that our approach outperforms the previous State Of The Art (SOTA) methods, and achieves a balance between inference efficiency and prediction accuracy in zero-shot relation extraction tasks. Our code is available at https://github.com/longls777/EMMA.
Zero-Shot Rumor Detection with Propagation Structure via Prompt Learning
Dec 02, 2022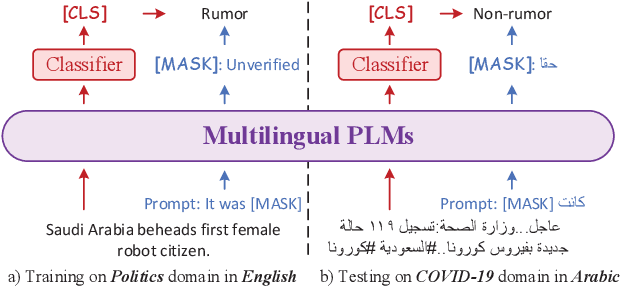


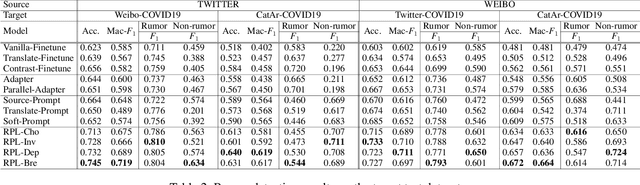
The spread of rumors along with breaking events seriously hinders the truth in the era of social media. Previous studies reveal that due to the lack of annotated resources, rumors presented in minority languages are hard to be detected. Furthermore, the unforeseen breaking events not involved in yesterday's news exacerbate the scarcity of data resources. In this work, we propose a novel zero-shot framework based on prompt learning to detect rumors falling in different domains or presented in different languages. More specifically, we firstly represent rumor circulated on social media as diverse propagation threads, then design a hierarchical prompt encoding mechanism to learn language-agnostic contextual representations for both prompts and rumor data. To further enhance domain adaptation, we model the domain-invariant structural features from the propagation threads, to incorporate structural position representations of influential community response. In addition, a new virtual response augmentation method is used to improve model training. Extensive experiments conducted on three real-world datasets demonstrate that our proposed model achieves much better performance than state-of-the-art methods and exhibits a superior capacity for detecting rumors at early stages.
Enhancing Label Correlation Feedback in Multi-Label Text Classification via Multi-Task Learning
Jun 06, 2021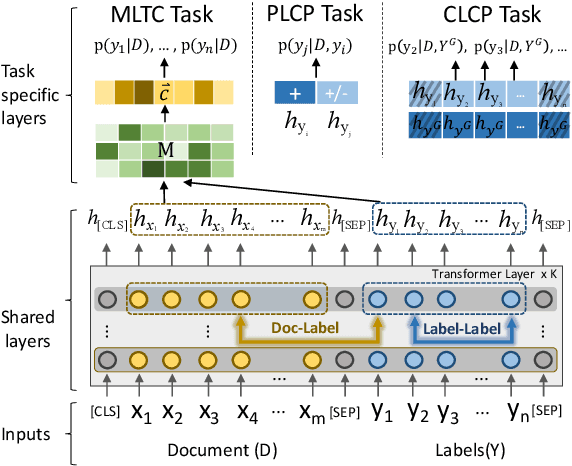
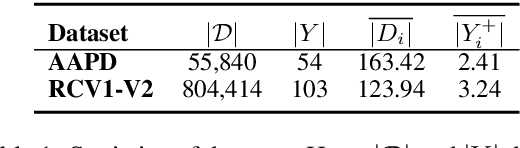
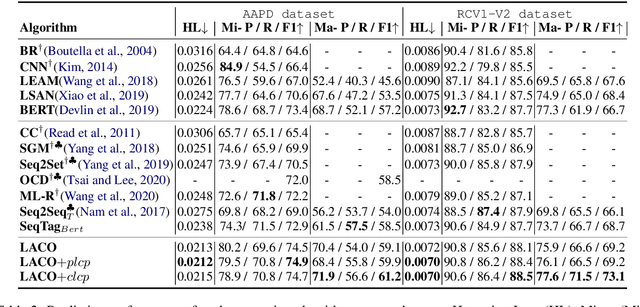
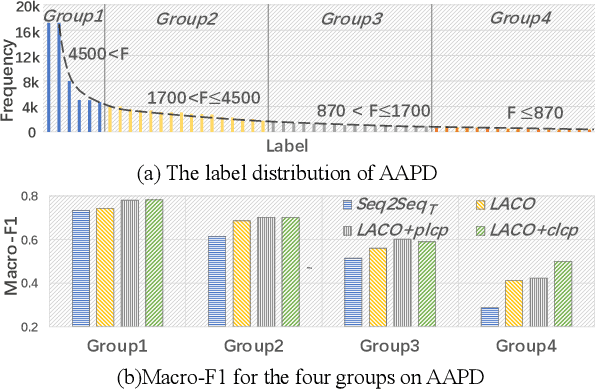
In multi-label text classification (MLTC), each given document is associated with a set of correlated labels. To capture label correlations, previous classifier-chain and sequence-to-sequence models transform MLTC to a sequence prediction task. However, they tend to suffer from label order dependency, label combination over-fitting and error propagation problems. To address these problems, we introduce a novel approach with multi-task learning to enhance label correlation feedback. We first utilize a joint embedding (JE) mechanism to obtain the text and label representation simultaneously. In MLTC task, a document-label cross attention (CA) mechanism is adopted to generate a more discriminative document representation. Furthermore, we propose two auxiliary label co-occurrence prediction tasks to enhance label correlation learning: 1) Pairwise Label Co-occurrence Prediction (PLCP), and 2) Conditional Label Co-occurrence Prediction (CLCP). Experimental results on AAPD and RCV1-V2 datasets show that our method outperforms competitive baselines by a large margin. We analyze low-frequency label performance, label dependency, label combination diversity and coverage speed to show the effectiveness of our proposed method on label correlation learning.
Neural Entity Reasoner for Global Consistency in NER
Sep 30, 2018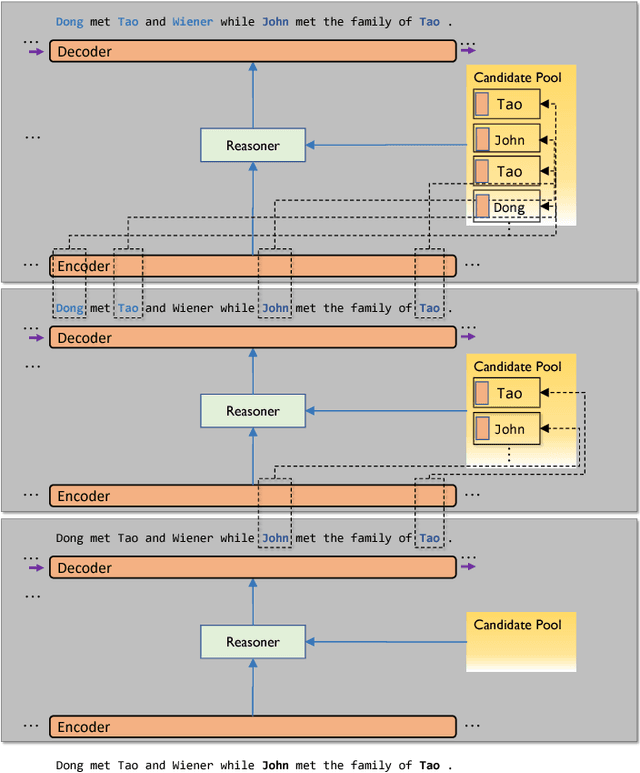
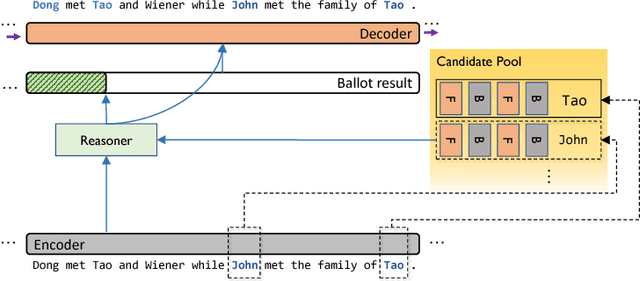
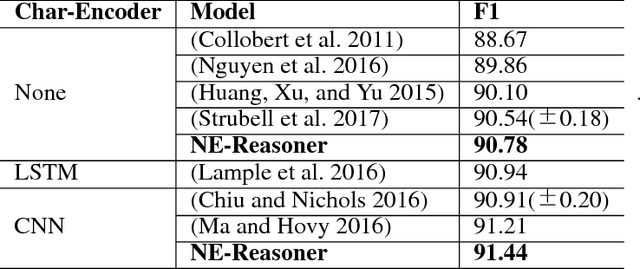
We propose Neural Entity Reasoner (NE-Reasoner), a framework to introduce global consistency of recognized entities into Neural Reasoner over Named Entity Recognition (NER) task. Given an input sentence, the NE-Reasoner layer can infer over multiple entities to increase the global consistency of output labels, which then be transfered into entities for the input of next layer. NE-Reasoner inherits and develops some features from Neural Reasoner 1) a symbolic memory, allowing it to exchange entities between layers. 2) the specific interaction-pooling mechanism, allowing it to connect each local word to multiple global entities, and 3) the deep architecture, allowing it to bootstrap the recognized entity set from coarse to fine. Like human beings, NE-Reasoner is able to accommodate ambiguous words and Name Entities that rarely or never met before. Despite the symbolic information the model introduced, NE-Reasoner can still be trained effectively in an end-to-end manner via parameter sharing strategy. NE-Reasoner can outperform conventional NER models in most cases on both English and Chinese NER datasets. For example, it achieves state-of-art on CoNLL-2003 English NER dataset.