 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAFM: Dynamic Adaptive Fusion for Multi-Model Collaboration in Composed Image Retrieval
Nov 07, 2025Composed Image Retrieval (CIR) is a cross-modal task that aims to retrieve target images from large-scale databases using a reference image and a modification text. Most existing methods rely on a single model to perform feature fusion and similarity matching. However, this paradigm faces two major challenges. First, one model alone can't see the whole picture and the tiny details at the same time; it has to handle different tasks with the same weights, so it often misses the small but important links between image and text. Second, the absence of dynamic weight allocation prevents adaptive leveraging of complementary model strengths, so the resulting embedding drifts away from the target and misleads the nearest-neighbor search in CIR. To address these limitations, we propose Dynamic Adaptive Fusion (DAFM) for multi-model collaboration in CIR. Rather than optimizing a single method in isolation, DAFM exploits the complementary strengths of heterogeneous models and adaptively rebalances their contributions. This not only maximizes retrieval accuracy but also ensures that the performance gains are independent of the fusion order, highlighting the robustness of our approach. Experiments on the CIRR and FashionIQ benchmarks demonstrate consistent improvements. Our method achieves a Recall@10 of 93.21 and an Rmean of 84.43 on CIRR, and an average Rmean of 67.48 on FashionIQ, surpassing recent strong baselines by up to 4.5%. These results confirm that dynamic multi-model collaboration provides an effective and general solution for CIR.
Ontology-Enhanced Knowledge Graph Completion using Large Language Models
Jul 28, 2025Large Language Models (LLMs) have been extensively adopted in Knowledge Graph Completion (KGC), showcasing significant research advancements. However, as black-box models driven by deep neural architectures, current LLM-based KGC methods rely on implicit knowledge representation with parallel propagation of erroneous knowledge, thereby hindering their ability to produce conclusive and decisive reasoning outcomes. We aim to integrate neural-perceptual structural information with ontological knowledge, leveraging the powerful capabilities of LLMs to achieve a deeper understanding of the intrinsic logic of the knowledge. We propose an ontology enhanced KGC method using LLMs -- OL-KGC. It first leverages neural perceptual mechanisms to effectively embed structural information into the textual space, and then uses an automated extraction algorithm to retrieve ontological knowledge from the knowledge graphs (KGs) that needs to be completed, which is further transformed into a textual format comprehensible to LLMs for providing logic guidance. We conducted extensive experiments on three widely-used benchmarks -- FB15K-237, UMLS and WN18RR. The experimental results demonstrate that OL-KGC significantly outperforms existing mainstream KGC methods across multiple evaluation metrics, achieving state-of-the-art performance.
Eliminating the Language Bias for Visual Question Answering with fine-grained Causal Intervention
Oct 14, 2024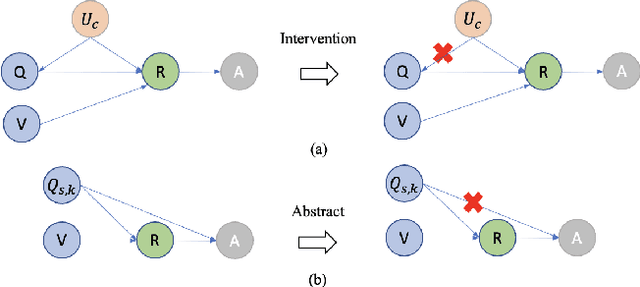
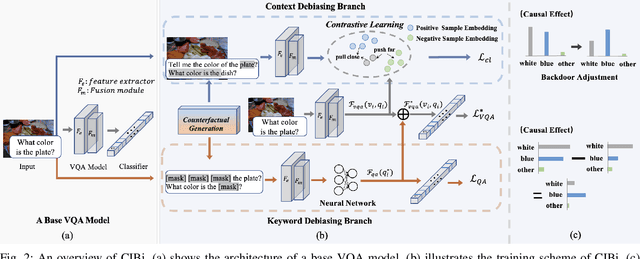
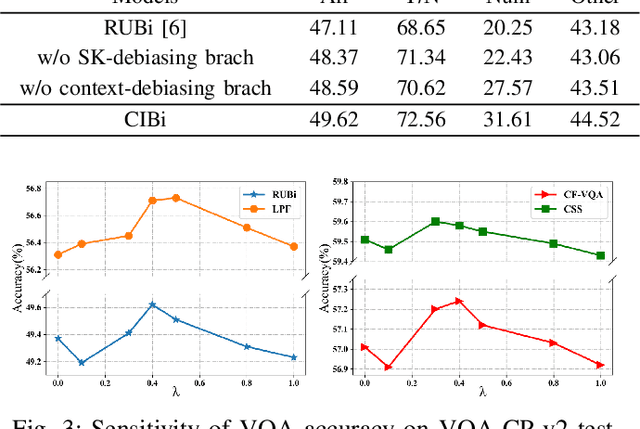
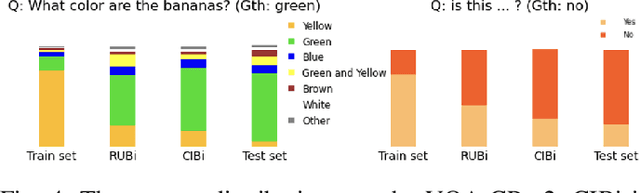
Despite the remarkable advancements in Visual Question Answering (VQA), the challenge of mitigating the language bias introduced by textual information remains unresolved. Previous approaches capture language bias from a coarse-grained perspective. However, the finer-grained information within a sentence, such as context and keywords, can result in different biases. Due to the ignorance of fine-grained information, most existing methods fail to sufficiently capture language bias. In this paper, we propose a novel causal intervention training scheme named CIBi to eliminate language bias from a finer-grained perspective. Specifically, we divide the language bias into context bias and keyword bias. We employ causal intervention and contrastive learning to eliminate context bias and improve the multi-modal representation. Additionally, we design a new question-only branch based on counterfactual generation to distill and eliminate keyword bias. Experimental results illustrate that CIBi is applicable to various VQA models, yielding competitive performance.
Large Language Model Enhanced Knowledge Representation Learning: A Survey
Jul 01, 2024



The integration of Large Language Models (LLMs) with Knowledge Representation Learning (KRL) signifies a pivotal advancement in the field of artificial intelligence, enhancing the ability to capture and utilize complex knowledge structures. This synergy leverages the advanced linguistic and contextual understanding capabilities of LLMs to improve the accuracy, adaptability, and efficacy of KRL, thereby expanding its applications and potential. Despite the increasing volume of research focused on embedding LLMs within the domain of knowledge representation, a thorough review that examines the fundamental components and processes of these enhanced models is conspicuously absent. Our survey addresses this by categorizing these models based on three distinct Transformer architectures, and by analyzing experimental data from various KRL downstream tasks to evaluate the strengths and weaknesses of each approach. Finally, we identify and explore potential future research directions in this emerging yet underexplored domain, proposing pathways for continued progress.
HyCubE: Efficient Knowledge Hypergraph 3D Circular Convolutional Embedding
Feb 14, 2024Existing knowledge hypergraph embedding methods mainly focused on improving model performance, but their model structures are becoming more complex and redundant. Furthermore, due to the inherent complex semantic knowledge, the computation of knowledge hypergraph embedding models is often very expensive, leading to low efficiency. In this paper, we propose a feature interaction and extraction-enhanced 3D circular convolutional embedding model, HyCubE, which designs a novel 3D circular convolutional neural network and introduces the alternate mask stack strategy to achieve efficient n-ary knowledge hypergraph embedding. By adaptively adjusting the 3D circular convolution kernel size and uniformly embedding the entity position information, HyCubE improves the model performance with fewer parameters and reaches a better trade-off between model performance and efficiency. In addition, we use 1-N multilinear scoring based on the entity mask mechanism to further accelerate the model training efficiency. Finally, extensive experimental results on all datasets demonstrate that HyCubE consistently outperforms state-of-the-art baselines, with an average improvement of 4.08%-10.77% and a maximum improvement of 21.16% across all metrics. Commendably, HyCubE speeds up by an average of 7.55x and reduces memory usage by an average of 77.02% compared to the latest state-of-the-art baselines.
ConvD: Attention Enhanced Dynamic Convolutional Embeddings for Knowledge Graph Completion
Dec 11, 2023



Knowledge graphs generally suffer from incompleteness, which can be alleviated by completing the missing information. Deep knowledge convolutional embedding models based on neural networks are currently popular methods for knowledge graph completion. However, most existing methods use external convolution kernels and traditional plain convolution processes, which limits the feature interaction capability of the model. In this paper, we propose a novel dynamic convolutional embedding model ConvD for knowledge graph completion, which directly reshapes the relation embeddings into multiple internal convolution kernels to improve the external convolution kernels of the traditional convolutional embedding model. The internal convolution kernels can effectively augment the feature interaction between the relation embeddings and entity embeddings, thus enhancing the model embedding performance. Moreover, we design a priori knowledge-optimized attention mechanism, which can assign different contribution weight coefficients to multiple relation convolution kernels for dynamic convolution to improve the expressiveness of the model further. Extensive experiments on various datasets show that our proposed model consistently outperforms the state-of-the-art baseline methods, with average improvements ranging from 11.30\% to 16.92\% across all model evaluation metrics. Ablation experiments verify the effectiveness of each component module of the ConvD model.
RSS-based Multiple Sources Localization with Unknown Log-normal Shadow Fading
Oct 20, 2021
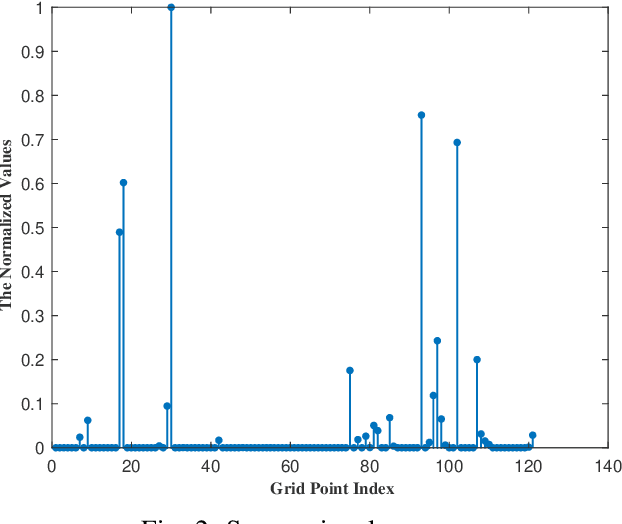
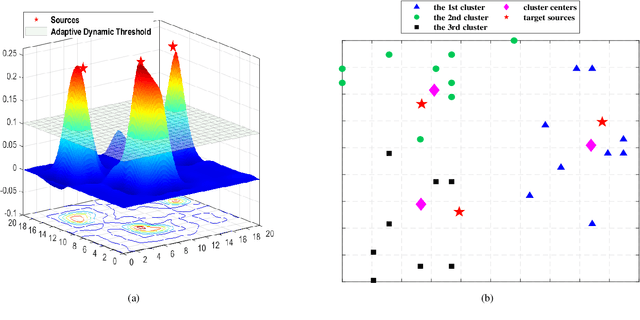
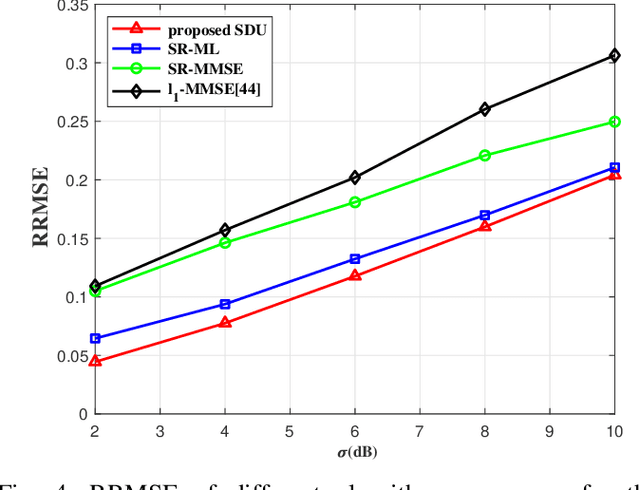
Multi-source localization based on received signal strength (RSS) has drawn great interest in wireless sensor networks. However, the shadow fading term caused by obstacles cannot be separated from the received signal, which leads to severe error in location estimate. In this paper, we approximate the log-normal sum distribution through Fenton-Wilkinson method to formulate a non-convex maximum likelihood (ML) estimator with unknown shadow fading factor. In order to overcome the difficulty in solving the non-convex problem, we propose a novel algorithm to estimate the locations of sources. Specifically, the region is divided into $N$ grids firstly, and the multi-source localization is converted into a sparse recovery problem so that we can obtain the sparse solution. Then we utilize the K-means clustering method to obtain the rough locations of the off-grid sources as the initial feasible point of the ML estimator. Finally, an iterative refinement of the estimated locations is proposed by dynamic updating of the localization dictionary. The proposed algorithm can efficiently approach a superior local optimal solution of the ML estimator. It is shown from the simulation results that the proposed method has a promising localization performance and improves the robustness for multi-source localization in unknown shadow fading environments. Moreover, the proposed method provides a better computational complexity from $O(K^3N^3)$ to $O(N^3)$.