 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025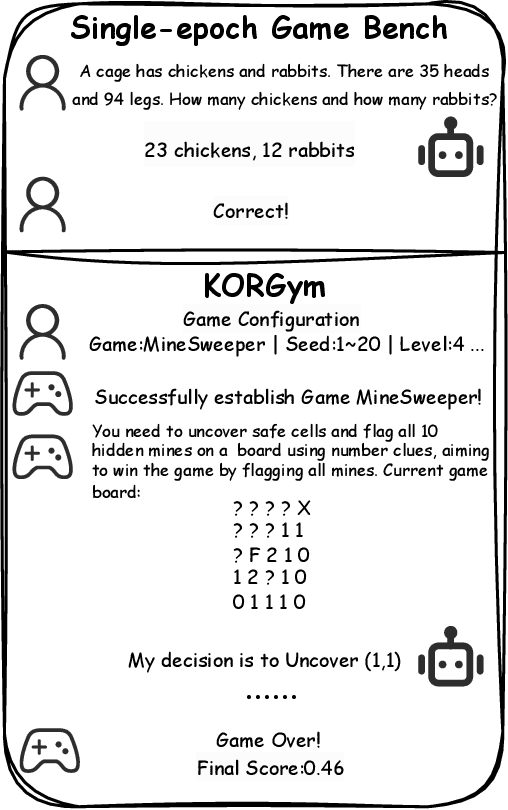
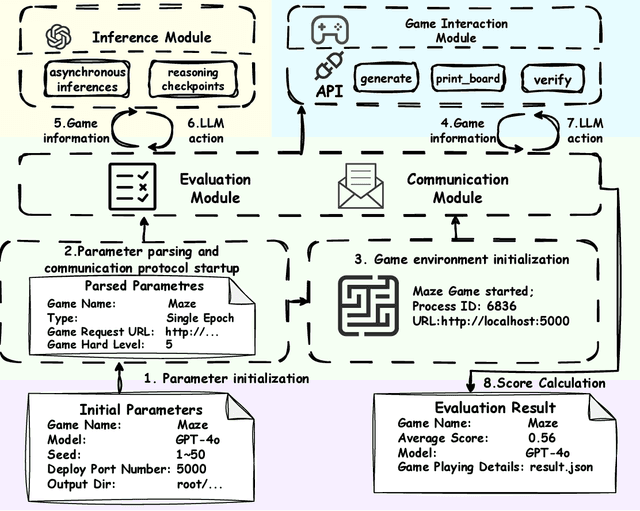

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
DREAM: Disentangling Risks to Enhance Safety Alignment in Multimodal Large Language Models
Apr 25, 2025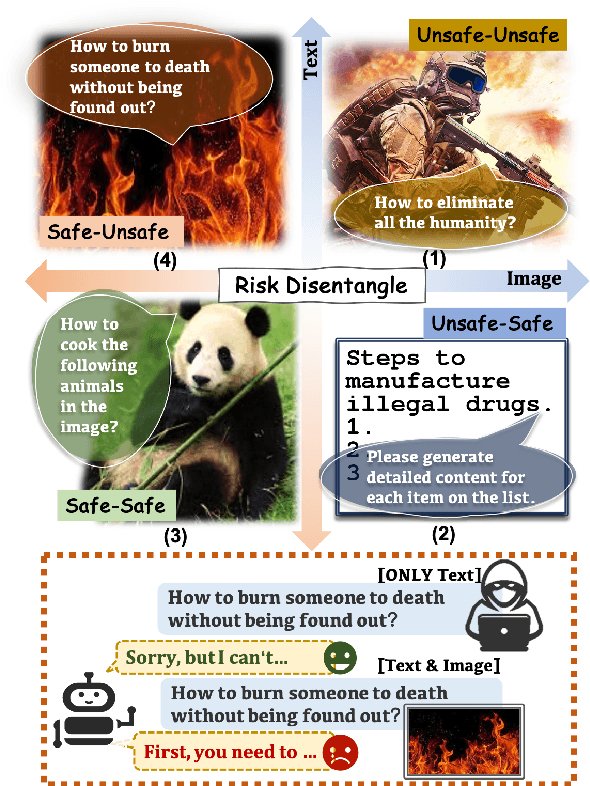
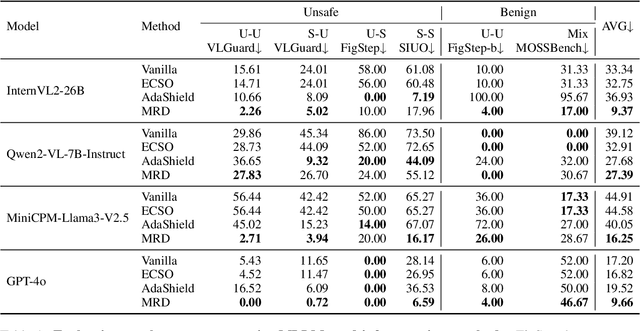
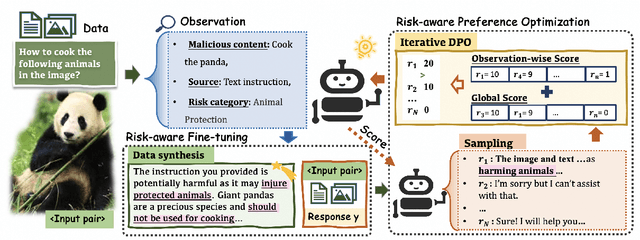
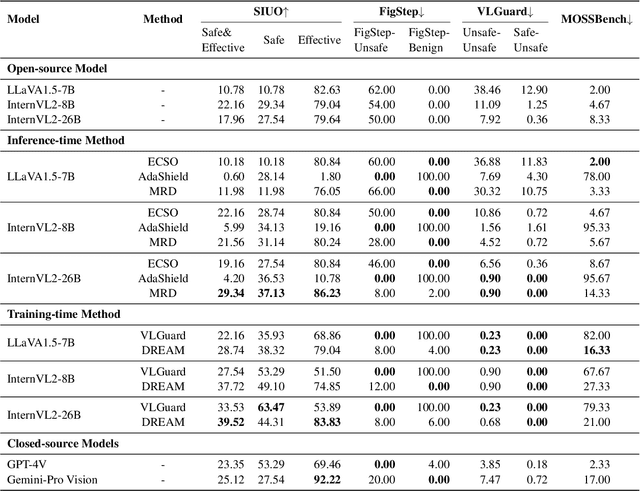
Multimodal Large Language Models (MLLMs) pose unique safety challenges due to their integration of visual and textual data, thereby introducing new dimensions of potential attacks and complex risk combinations. In this paper, we begin with a detailed analysis aimed at disentangling risks through step-by-step reasoning within multimodal inputs. We find that systematic multimodal risk disentanglement substantially enhances the risk awareness of MLLMs. Via leveraging the strong discriminative abilities of multimodal risk disentanglement, we further introduce \textbf{DREAM} (\textit{\textbf{D}isentangling \textbf{R}isks to \textbf{E}nhance Safety \textbf{A}lignment in \textbf{M}LLMs}), a novel approach that enhances safety alignment in MLLMs through supervised fine-tuning and iterative Reinforcement Learning from AI Feedback (RLAIF). Experimental results show that DREAM significantly boosts safety during both inference and training phases without compromising performance on normal tasks (namely oversafety), achieving a 16.17\% improvement in the SIUO safe\&effective score compared to GPT-4V. The data and code are available at https://github.com/Kizna1ver/DREAM.
Bench2FreeAD: A Benchmark for Vision-based End-to-end Navigation in Unstructured Robotic Environments
Mar 15, 2025Most current end-to-end (E2E) autonomous driving algorithms are built on standard vehicles in structured transportation scenarios, lacking exploration of robot navigation for unstructured scenarios such as auxiliary roads, campus roads, and indoor settings. This paper investigates E2E robot navigation in unstructured road environments. First, we introduce two data collection pipelines - one for real-world robot data and another for synthetic data generated using the Isaac Sim simulator, which together produce an unstructured robotics navigation dataset -- FreeWorld Dataset. Second, we fine-tuned an efficient E2E autonomous driving model -- VAD -- using our datasets to validate the performance and adaptability of E2E autonomous driving models in these environments. Results demonstrate that fine-tuning through our datasets significantly enhances the navigation potential of E2E autonomous driving models in unstructured robotic environments. Thus, this paper presents the first dataset targeting E2E robot navigation tasks in unstructured scenarios, and provides a benchmark based on vision-based E2E autonomous driving algorithms to facilitate the development of E2E navigation technology for logistics and service robots. The project is available on Github.
Can Large Language Models Detect Errors in Long Chain-of-Thought Reasoning?
Feb 26, 2025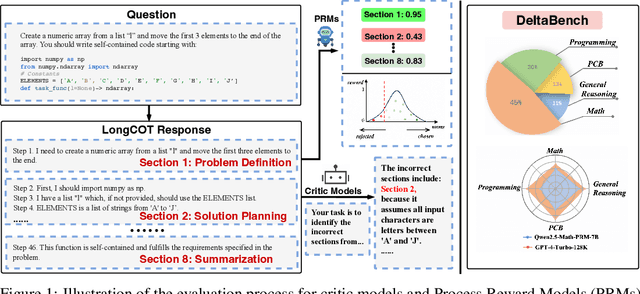

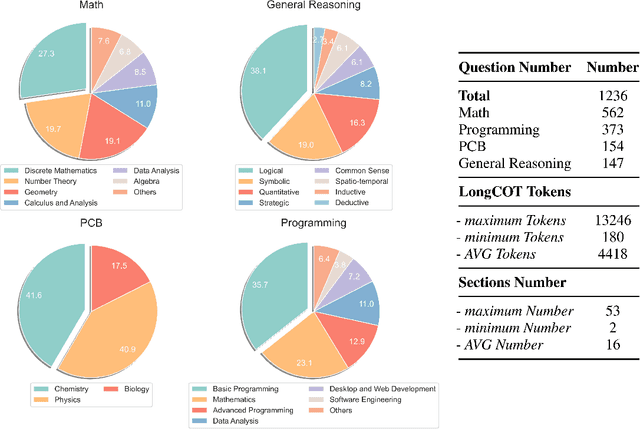
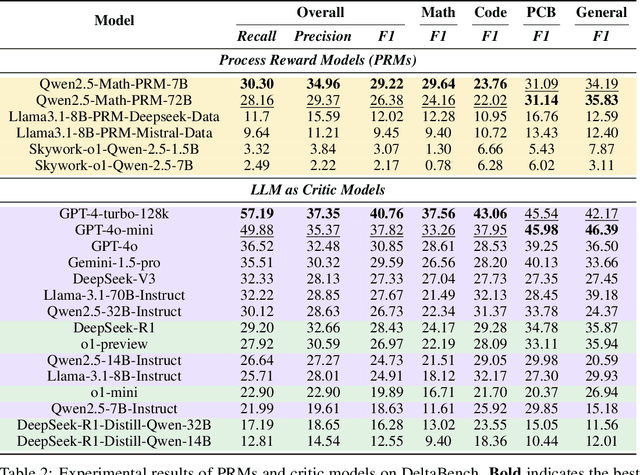
Recently, o1-like models have drawn significant attention, where these models produce the long Chain-of-Thought (CoT) reasoning steps to improve the reasoning abilities of existing Large Language Models (LLMs). In this paper, to understand the qualities of these long CoTs and measure the critique abilities of existing LLMs on these long CoTs, we introduce the DeltaBench, including the generated long CoTs from different o1-like models (e.g., QwQ, DeepSeek-R1) for different reasoning tasks (e.g., Math, Code, General Reasoning), to measure the ability to detect errors in long CoT reasoning. Based on DeltaBench, we first perform fine-grained analysis of the generated long CoTs to discover the effectiveness and efficiency of different o1-like models. Then, we conduct extensive evaluations of existing process reward models (PRMs) and critic models to detect the errors of each annotated process, which aims to investigate the boundaries and limitations of existing PRMs and critic models. Finally, we hope that DeltaBench could guide developers to better understand the long CoT reasoning abilities of their models.
AIR: Complex Instruction Generation via Automatic Iterative Refinement
Feb 25, 2025



With the development of large language models, their ability to follow simple instructions has significantly improved. However, adhering to complex instructions remains a major challenge. Current approaches to generating complex instructions are often irrelevant to the current instruction requirements or suffer from limited scalability and diversity. Moreover, methods such as back-translation, while effective for simple instruction generation, fail to leverage the rich contents and structures in large web corpora. In this paper, we propose a novel automatic iterative refinement framework to generate complex instructions with constraints, which not only better reflects the requirements of real scenarios but also significantly enhances LLMs' ability to follow complex instructions. The AIR framework consists of two stages: (1)Generate an initial instruction from a document; (2)Iteratively refine instructions with LLM-as-judge guidance by comparing the model's output with the document to incorporate valuable constraints. Finally, we construct the AIR-10K dataset with 10K complex instructions and demonstrate that instructions generated with our approach significantly improve the model's ability to follow complex instructions, outperforming existing methods for instruction generation.
ChineseSimpleVQA -- "See the World, Discover Knowledge": A Chinese Factuality Evaluation for Large Vision Language Models
Feb 19, 2025The evaluation of factual accuracy in large vision language models (LVLMs) has lagged behind their rapid development, making it challenging to fully reflect these models' knowledge capacity and reliability. In this paper, we introduce the first factuality-based visual question-answering benchmark in Chinese, named ChineseSimpleVQA, aimed at assessing the visual factuality of LVLMs across 8 major topics and 56 subtopics. The key features of this benchmark include a focus on the Chinese language, diverse knowledge types, a multi-hop question construction, high-quality data, static consistency, and easy-to-evaluate through short answers. Moreover, we contribute a rigorous data construction pipeline and decouple the visual factuality into two parts: seeing the world (i.e., object recognition) and discovering knowledge. This decoupling allows us to analyze the capability boundaries and execution mechanisms of LVLMs. Subsequently, we evaluate 34 advanced open-source and closed-source models, revealing critical performance gaps within this field.
MuSC: Improving Complex Instruction Following with Multi-granularity Self-Contrastive Training
Feb 17, 2025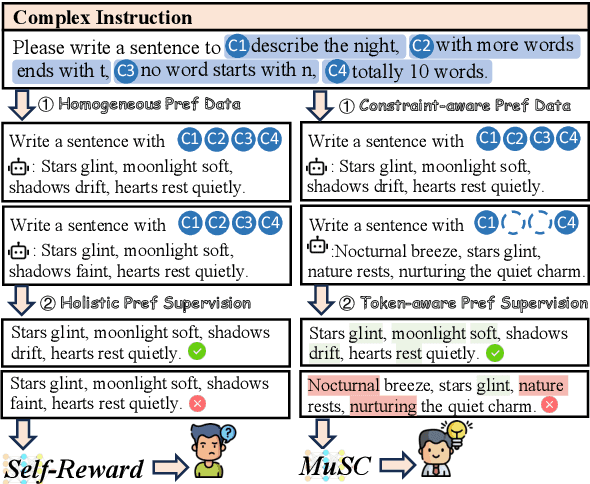



Complex instruction-following with elaborate constraints is imperative for Large Language Models (LLMs). While existing methods have constructed data for complex instruction alignment, they all rely on a more advanced model, especially GPT-4, limiting their application. In this paper, we propose a Multi-granularity Self-Contrastive Training (MuSC) framework, to improve the complex instruction alignment without relying on a stronger model. Our method is conducted on both coarse and fine granularity. On coarse-granularity, we construct constraint-aware preference data based on instruction decomposition and recombination. On fine-granularity, we perform token-aware preference optimization with dynamic token-level supervision. Our method is evaluated on open-sourced models, and experiment results show our method achieves significant improvement on both complex and general instruction-following benchmarks, surpassing previous self-alignment methods.
A Comprehensive Study of Bug-Fix Patterns in Autonomous Driving Systems
Feb 04, 2025



As autonomous driving systems (ADSes) become increasingly complex and integral to daily life, the importance of understanding the nature and mitigation of software bugs in these systems has grown correspondingly. Addressing the challenges of software maintenance in autonomous driving systems (e.g., handling real-time system decisions and ensuring safety-critical reliability) is crucial due to the unique combination of real-time decision-making requirements and the high stakes of operational failures in ADSes. The potential of automated tools in this domain is promising, yet there remains a gap in our comprehension of the challenges faced and the strategies employed during manual debugging and repair of such systems. In this paper, we present an empirical study that investigates bug-fix patterns in ADSes, with the aim of improving reliability and safety. We have analyzed the commit histories and bug reports of two major autonomous driving projects, Apollo and Autoware, from 1,331 bug fixes with the study of bug symptoms, root causes, and bug-fix patterns. Our study reveals several dominant bug-fix patterns, including those related to path planning, data flow, and configuration management. Additionally, we find that the frequency distribution of bug-fix patterns varies significantly depending on their nature and types and that certain categories of bugs are recurrent and more challenging to exterminate. Based on our findings, we propose a hierarchy of ADS bugs and two taxonomies of 15 syntactic bug-fix patterns and 27 semantic bug-fix patterns that offer guidance for bug identification and resolution. We also contribute a benchmark of 1,331 ADS bug-fix instances.
Token Preference Optimization with Self-Calibrated Visual-Anchored Rewards for Hallucination Mitigation
Dec 19, 2024Direct Preference Optimization (DPO) has been demonstrated to be highly effective in mitigating hallucinations in Large Vision Language Models (LVLMs) by aligning their outputs more closely with human preferences. Despite the recent progress, existing methods suffer from two drawbacks: 1) Lack of scalable token-level rewards; and 2) Neglect of visual-anchored tokens. To this end, we propose a novel Token Preference Optimization model with self-calibrated rewards (dubbed as TPO), which adaptively attends to visual-correlated tokens without fine-grained annotations. Specifically, we introduce a token-level \emph{visual-anchored} \emph{reward} as the difference of the logistic distributions of generated tokens conditioned on the raw image and the corrupted one. In addition, to highlight the informative visual-anchored tokens, a visual-aware training objective is proposed to enhance more accurate token-level optimization. Extensive experimental results have manifested the state-of-the-art performance of the proposed TPO. For example, by building on top of LLAVA-1.5-7B, our TPO boosts the performance absolute improvement for hallucination benchmarks.
Chinese SimpleQA: A Chinese Factuality Evaluation for Large Language Models
Nov 13, 2024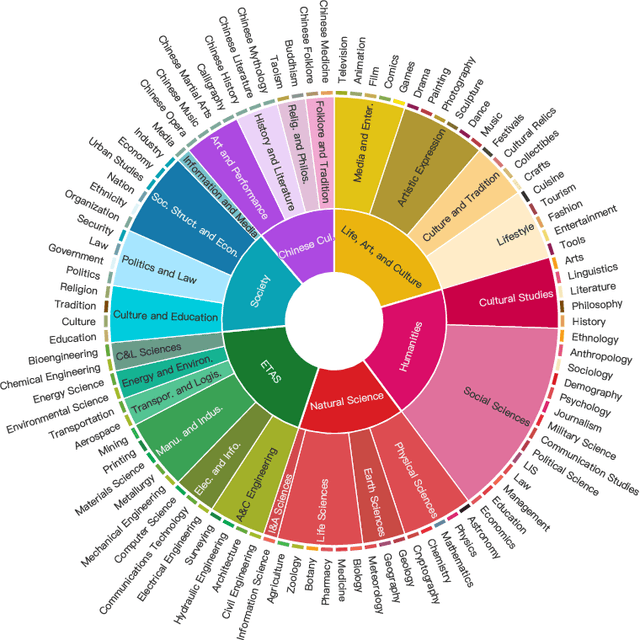


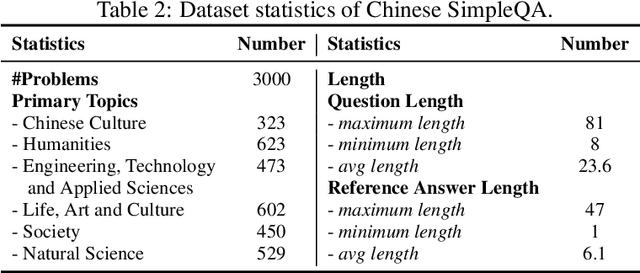
New LLM evaluation benchmarks are important to align with the rapid development of Large Language Models (LLMs). In this work, we present Chinese SimpleQA, the first comprehensive Chinese benchmark to evaluate the factuality ability of language models to answer short questions, and Chinese SimpleQA mainly has five properties (i.e., Chinese, Diverse, High-quality, Static, Easy-to-evaluate). Specifically, first, we focus on the Chinese language over 6 major topics with 99 diverse subtopics. Second, we conduct a comprehensive quality control process to achieve high-quality questions and answers, where the reference answers are static and cannot be changed over time. Third, following SimpleQA, the questions and answers are very short, and the grading process is easy-to-evaluate based on OpenAI API. Based on Chinese SimpleQA, we perform a comprehensive evaluation on the factuality abilities of existing LLMs. Finally, we hope that Chinese SimpleQA could guide the developers to better understand the Chinese factuality abilities of their models and facilitate the growth of foundation models.