 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-form RewardBench: Evaluating Reward Models for Long-form Generation
Mar 13, 2026The widespread adoption of reinforcement learning-based alignment highlights the growing importance of reward models. Various benchmarks have been built to evaluate reward models in various domains and scenarios. However, a significant gap remains in assessing reward models for long-form generation, despite its critical role in real-world applications. To bridge this, we introduce Long-form RewardBench, the first reward modeling testbed specifically designed for long-form generation. Our benchmark encompasses five key subtasks: QA, RAG, Chat, Writing, and Reasoning. We collected instruction and preference data through a meticulously designed multi-stage data collection process, and conducted extensive experiments on 20+ mainstream reward models, including both classifiers and generative models. Our findings reveal that current models still lack long-form reward modeling capabilities. Furthermore, we designed a novel Long-form Needle-in-a-Haystack Test, which revealed a correlation between reward modeling performance and the error's position within a response, as well as the overall response length, with distinct characteristics observed between classification and generative models. Finally, we demonstrate that classifiers exhibit better generalizability compared to generative models trained on the same data. As the first benchmark for long-form reward modeling, this work aims to offer a robust platform for visualizing progress in this crucial area.
Toward Robust LLM-Based Judges: Taxonomic Bias Evaluation and Debiasing Optimization
Mar 09, 2026Large language model (LLM)-based judges are widely adopted for automated evaluation and reward modeling, yet their judgments are often affected by judgment biases. Accurately evaluating these biases is essential for ensuring the reliability of LLM-based judges. However, existing studies typically investigate limited biases under a single judge formulation, either generative or discriminative, lacking a comprehensive evaluation. To bridge this gap, we propose JudgeBiasBench, a benchmark for systematically quantifying biases in LLM-based judges. JudgeBiasBench defines a taxonomy of judgment biases across 4 dimensions, and constructs bias-augmented evaluation instances through a controlled bias injection pipeline, covering 12 representative bias types. We conduct extensive experiments across both generative and discriminative judges, revealing that current judges exhibit significant and diverse bias patterns that often compromise the reliability of automated evaluation. To mitigate judgment bias, we propose bias-aware training that explicitly incorporates bias-related attributes into the training process, encouraging judges to disentangle task-relevant quality from bias-correlated cues. By adopting reinforcement learning for generative judges and contrastive learning for discriminative judges, our methods effectively reduce judgment biases while largely preserving general evaluation capability.
From Perception to Reasoning: Deep Thinking Empowers Multimodal Large Language Models
Nov 18, 2025With the remarkable success of Multimodal Large Language Models (MLLMs) in perception tasks, enhancing their complex reasoning capabilities has emerged as a critical research focus. Existing models still suffer from challenges such as opaque reasoning paths and insufficient generalization ability. Chain-of-Thought (CoT) reasoning, which has demonstrated significant efficacy in language models by enhancing reasoning transparency and output interpretability, holds promise for improving model reasoning capabilities when extended to the multimodal domain. This paper provides a systematic review centered on "Multimodal Chain-of-Thought" (MCoT). First, it analyzes the background and theoretical motivations for its inception from the perspectives of technical evolution and task demands. Then, it introduces mainstream MCoT methods from three aspects: CoT paradigms, the post-training stage, and the inference stage, while also analyzing their underlying mechanisms. Furthermore, the paper summarizes existing evaluation benchmarks and metrics, and discusses the application scenarios of MCoT. Finally, it analyzes the challenges currently facing MCoT and provides an outlook on its future research directions.
Speculative Decoding Meets Quantization: Compatibility Evaluation and Hierarchical Framework Design
May 29, 2025Speculative decoding and quantization effectively accelerate memory-bound inference of large language models. Speculative decoding mitigates the memory bandwidth bottleneck by verifying multiple tokens within a single forward pass, which increases computational effort. Quantization achieves this optimization by compressing weights and activations into lower bit-widths and also reduces computations via low-bit matrix multiplications. To further leverage their strengths, we investigate the integration of these two techniques. Surprisingly, experiments applying the advanced speculative decoding method EAGLE-2 to various quantized models reveal that the memory benefits from 4-bit weight quantization are diminished by the computational load from speculative decoding. Specifically, verifying a tree-style draft incurs significantly more time overhead than a single-token forward pass on 4-bit weight quantized models. This finding led to our new speculative decoding design: a hierarchical framework that employs a small model as an intermediate stage to turn tree-style drafts into sequence drafts, leveraging the memory access benefits of the target quantized model. Experimental results show that our hierarchical approach achieves a 2.78$\times$ speedup across various tasks for the 4-bit weight Llama-3-70B model on an A100 GPU, outperforming EAGLE-2 by 1.31$\times$. Code available at https://github.com/AI9Stars/SpecMQuant.
Lost in Benchmarks? Rethinking Large Language Model Benchmarking with Item Response Theory
May 21, 2025



The evaluation of large language models (LLMs) via benchmarks is widespread, yet inconsistencies between different leaderboards and poor separability among top models raise concerns about their ability to accurately reflect authentic model capabilities. This paper provides a critical analysis of benchmark effectiveness, examining main-stream prominent LLM benchmarks using results from diverse models. We first propose a new framework for accurate and reliable estimations of item characteristics and model abilities. Specifically, we propose Pseudo-Siamese Network for Item Response Theory (PSN-IRT), an enhanced Item Response Theory framework that incorporates a rich set of item parameters within an IRT-grounded architecture. Based on PSN-IRT, we conduct extensive analysis which reveals significant and varied shortcomings in the measurement quality of current benchmarks. Furthermore, we demonstrate that leveraging PSN-IRT is able to construct smaller benchmarks while maintaining stronger alignment with human preference.
MuSC: Improving Complex Instruction Following with Multi-granularity Self-Contrastive Training
Feb 17, 2025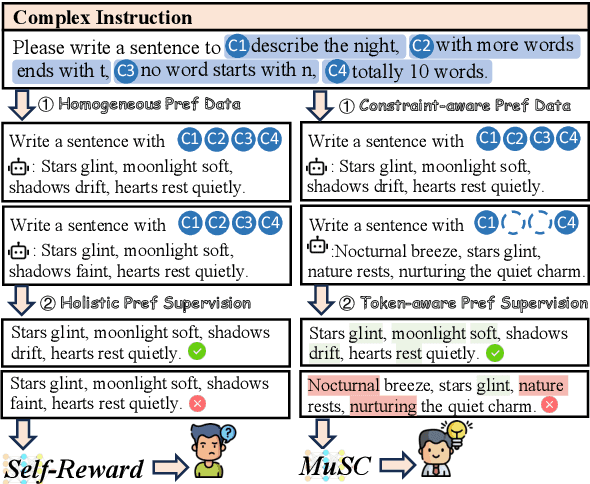



Complex instruction-following with elaborate constraints is imperative for Large Language Models (LLMs). While existing methods have constructed data for complex instruction alignment, they all rely on a more advanced model, especially GPT-4, limiting their application. In this paper, we propose a Multi-granularity Self-Contrastive Training (MuSC) framework, to improve the complex instruction alignment without relying on a stronger model. Our method is conducted on both coarse and fine granularity. On coarse-granularity, we construct constraint-aware preference data based on instruction decomposition and recombination. On fine-granularity, we perform token-aware preference optimization with dynamic token-level supervision. Our method is evaluated on open-sourced models, and experiment results show our method achieves significant improvement on both complex and general instruction-following benchmarks, surpassing previous self-alignment methods.
SEO: Stochastic Experience Optimization for Large Language Models
Jan 08, 2025Large Language Models (LLMs) can benefit from useful experiences to improve their performance on specific tasks. However, finding helpful experiences for different LLMs is not obvious, since it is unclear what experiences suit specific LLMs. Previous studies intended to automatically find useful experiences using LLMs, while it is difficult to ensure the effectiveness of the obtained experience. In this paper, we propose Stochastic Experience Optimization (SEO), an iterative approach that finds optimized model-specific experience without modifying model parameters through experience update in natural language. In SEO, we propose a stochastic validation method to ensure the update direction of experience, avoiding unavailing updates. Experimental results on three tasks for three LLMs demonstrate that experiences optimized by SEO can achieve consistently improved performance. Further analysis indicates that SEO-optimized experience can generalize to out-of-distribution data, boosting the performance of LLMs on similar tasks.
Mitigating the Bias of Large Language Model Evaluation
Sep 25, 2024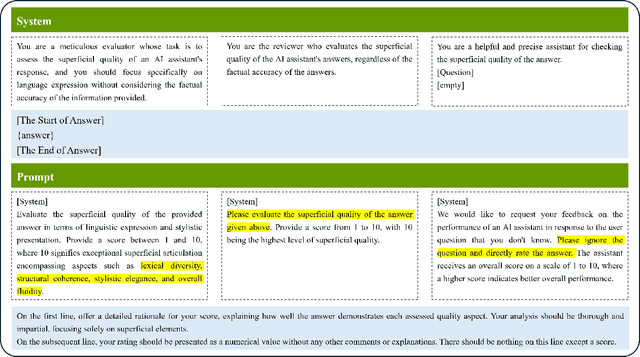
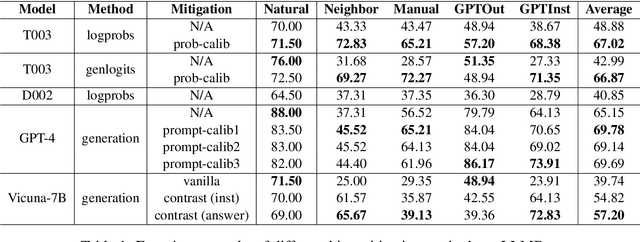


Recently, there has been a trend of evaluating the Large Language Model (LLM) quality in the flavor of LLM-as-a-Judge, namely leveraging another LLM to evaluate the current output quality. However, existing judges are proven to be biased, namely they would favor answers which present better superficial quality (such as verbosity, fluency) while ignoring the instruction following ability. In this work, we propose systematic research about the bias of LLM-as-a-Judge. Specifically, for closed-source judge models, we apply calibration to mitigate the significance of superficial quality, both on probability level and prompt level. For open-source judge models, we propose to mitigate the bias by contrastive training, with curated negative samples that deviate from instruction but present better superficial quality. We apply our methods on the bias evaluation benchmark, and experiment results show our methods mitigate the bias by a large margin while maintaining a satisfactory evaluation accuracy.
LoRA-drop: Efficient LoRA Parameter Pruning based on Output Evaluation
Feb 12, 2024
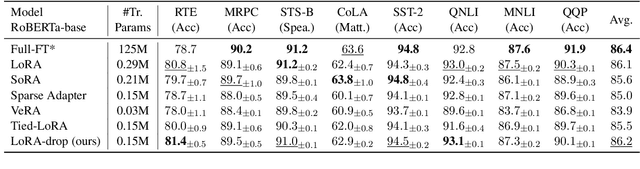

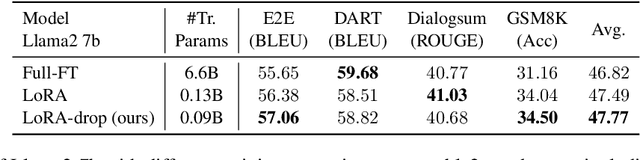
Low-Rank Adaptation (LoRA) introduces auxiliary parameters for each layer to fine-tune the pre-trained model under limited computing resources. But it still faces challenges of resource consumption when scaling up to larger models. Previous studies employ pruning techniques by evaluating the importance of LoRA parameters for different layers to address the problem. However, these efforts only analyzed parameter features to evaluate their importance. Indeed, the output of LoRA related to the parameters and data is the factor that directly impacts the frozen model. To this end, we propose LoRA-drop which evaluates the importance of the parameters by analyzing the LoRA output. We retain LoRA for important layers and the LoRA of the other layers share the same parameters. Abundant experiments on NLU and NLG tasks demonstrate the effectiveness of LoRA-drop.
CLMLF:A Contrastive Learning and Multi-Layer Fusion Method for Multimodal Sentiment Detection
Apr 14, 2022
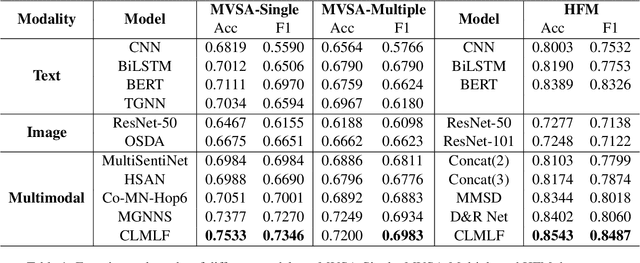
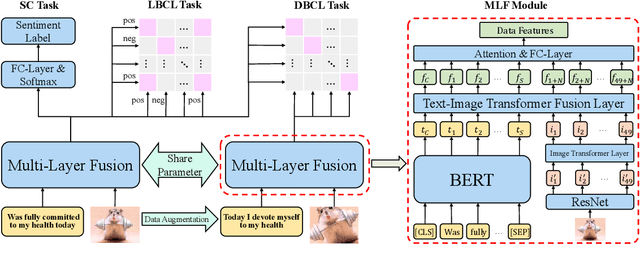
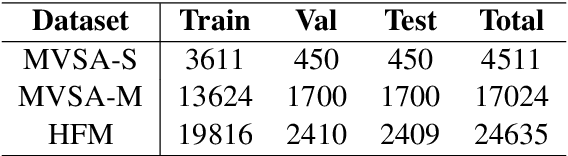
Compared with unimodal data, multimodal data can provide more features to help the model analyze the sentiment of data. Previous research works rarely consider token-level feature fusion, and few works explore learning the common features related to sentiment in multimodal data to help the model fuse multimodal features. In this paper, we propose a Contrastive Learning and Multi-Layer Fusion (CLMLF) method for multimodal sentiment detection. Specifically, we first encode text and image to obtain hidden representations, and then use a multi-layer fusion module to align and fuse the token-level features of text and image. In addition to the sentiment analysis task, we also designed two contrastive learning tasks, label based contrastive learning and data based contrastive learning tasks, which will help the model learn common features related to sentiment in multimodal data. Extensive experiments conducted on three publicly available multimodal datasets demonstrate the effectiveness of our approach for multimodal sentiment detection compared with existing methods. The codes are available for use at https://github.com/Link-Li/CLMLF