 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEO: Stochastic Experience Optimization for Large Language Models
Jan 08, 2025Large Language Models (LLMs) can benefit from useful experiences to improve their performance on specific tasks. However, finding helpful experiences for different LLMs is not obvious, since it is unclear what experiences suit specific LLMs. Previous studies intended to automatically find useful experiences using LLMs, while it is difficult to ensure the effectiveness of the obtained experience. In this paper, we propose Stochastic Experience Optimization (SEO), an iterative approach that finds optimized model-specific experience without modifying model parameters through experience update in natural language. In SEO, we propose a stochastic validation method to ensure the update direction of experience, avoiding unavailing updates. Experimental results on three tasks for three LLMs demonstrate that experiences optimized by SEO can achieve consistently improved performance. Further analysis indicates that SEO-optimized experience can generalize to out-of-distribution data, boosting the performance of LLMs on similar tasks.
BiSync: A Bilingual Editor for Synchronized Monolingual Texts
Jun 01, 2023In our globalized world, a growing number of situations arise where people are required to communicate in one or several foreign languages. In the case of written communication, users with a good command of a foreign language may find assistance from computer-aided translation (CAT) technologies. These technologies often allow users to access external resources, such as dictionaries, terminologies or bilingual concordancers, thereby interrupting and considerably hindering the writing process. In addition, CAT systems assume that the source sentence is fixed and also restrict the possible changes on the target side. In order to make the writing process smoother, we present BiSync, a bilingual writing assistant that allows users to freely compose text in two languages, while maintaining the two monolingual texts synchronized. We also include additional functionalities, such as the display of alternative prefix translations and paraphrases, which are intended to facilitate the authoring of texts. We detail the model architecture used for synchronization and evaluate the resulting tool, showing that high accuracy can be attained with limited computational resources. The interface and models are publicly available at https://github.com/jmcrego/BiSync and a demonstration video can be watched on YouTube at https://youtu.be/_l-ugDHfNgU .
New Trends in Machine Translation using Large Language Models: Case Examples with ChatGPT
May 02, 2023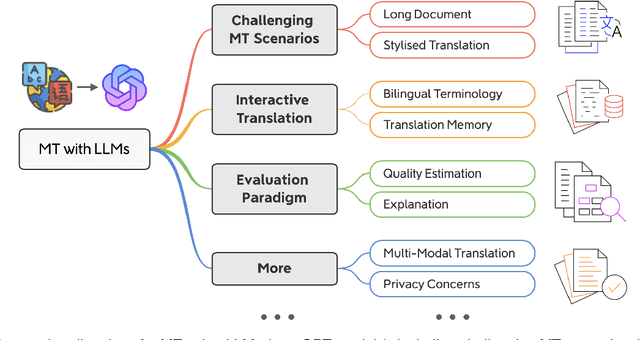



Machine Translation (MT) has made significant progress in recent years using deep learning, especially after the emergence of large language models (LLMs) such as GPT-3 and ChatGPT. This brings new challenges and opportunities for MT using LLMs. In this paper, we brainstorm some interesting directions for MT using LLMs, including stylized MT, interactive MT, and Translation Memory-based MT, as well as a new evaluation paradigm using LLMs. We also discuss the privacy concerns in MT using LLMs and a basic privacy-preserving method to mitigate such risks. To illustrate the potential of our proposed directions, we present several examples for the new directions mentioned above, demonstrating the feasibility of the proposed directions and highlight the opportunities and challenges for future research in MT using LLMs.
Bilingual Synchronization: Restoring Translational Relationships with Editing Operations
Oct 24, 2022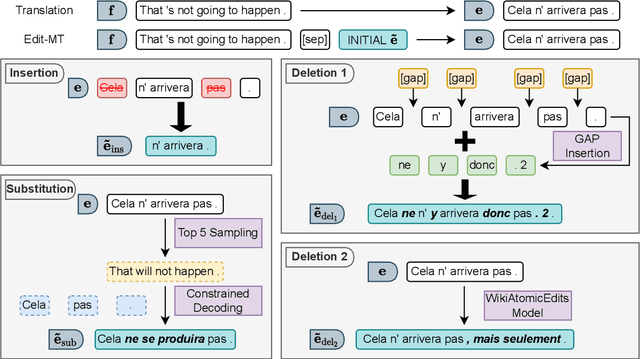


Machine Translation (MT) is usually viewed as a one-shot process that generates the target language equivalent of some source text from scratch. We consider here a more general setting which assumes an initial target sequence, that must be transformed into a valid translation of the source, thereby restoring parallelism between source and target. For this bilingual synchronization task, we consider several architectures (both autoregressive and non-autoregressive) and training regimes, and experiment with multiple practical settings such as simulated interactive MT, translating with Translation Memory (TM) and TM cleaning. Our results suggest that one single generic edit-based system, once fine-tuned, can compare with, or even outperform, dedicated systems specifically trained for these tasks.
Non-Autoregressive Machine Translation with Translation Memories
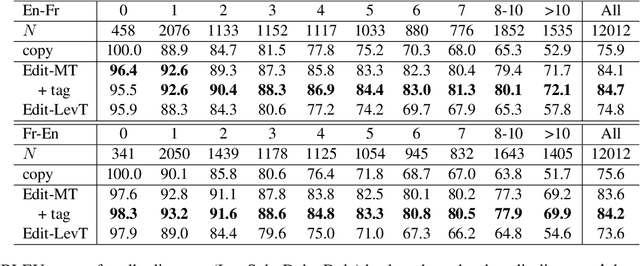
Oct 12, 2022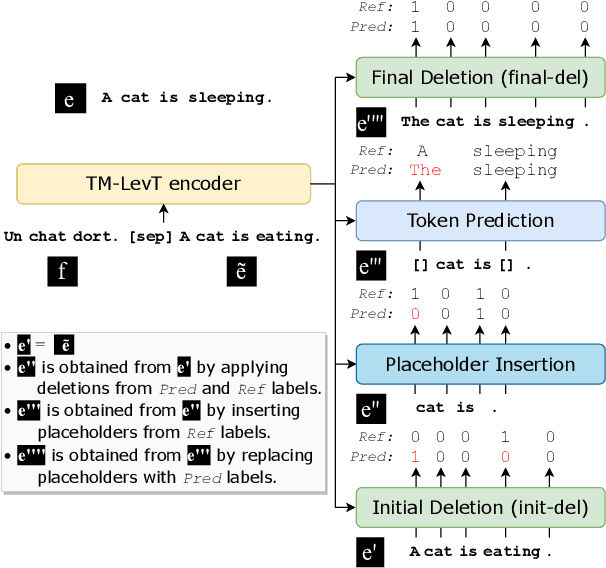
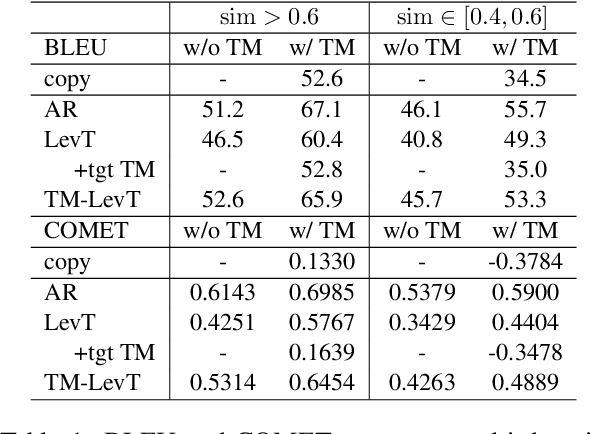

Non-autoregressive machine translation (NAT) has recently made great progress. However, most works to date have focused on standard translation tasks, even though some edit-based NAT models, such as the Levenshtein Transformer (LevT), seem well suited to translate with a Translation Memory (TM). This is the scenario considered here. We first analyze the vanilla LevT model and explain why it does not do well in this setting. We then propose a new variant, TM-LevT, and show how to effectively train this model. By modifying the data presentation and introducing an extra deletion operation, we obtain performance that are on par with an autoregressive approach, while reducing the decoding load. We also show that incorporating TMs during training dispenses to use knowledge distillation, a well-known trick used to mitigate the multimodality issue.
Finding and Exploring Promising Search Space for the 0-1 Multidimensional Knapsack Problem
Oct 08, 2022

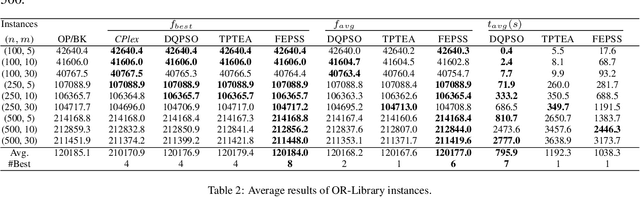
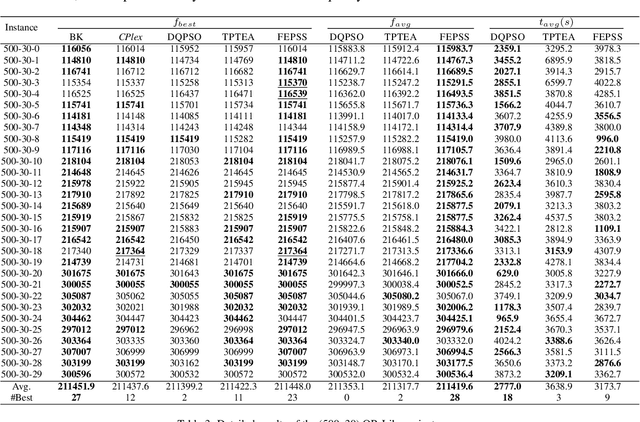
The 0-1 multidimensional knapsack problem(MKP) is a classical NP-hard combinatorial optimization problem. In this paper, we propose a novel heuristic algorithm simulating evolutionary computation and large neighbourhood search for the MKP. It maintains a set of solutions and abstracts information from the solution set to generate good partial assignments. To find high-quality solutions, integer programming is employed to explore the promising search space specified by the good partial assignments. Extensive experimentation with commonly used benchmark sets shows that our approach outperforms the state of the art heuristic algorithms, TPTEA and DQPSO, in solution quality. It finds new lower bound for 8 large and hard instances
Joint Generation of Captions and Subtitles with Dual Decoding
May 13, 2022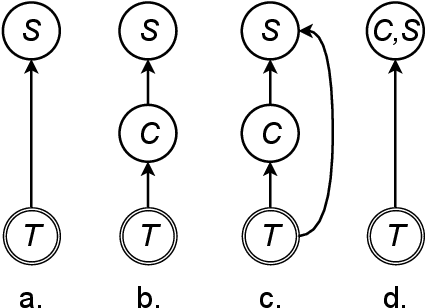

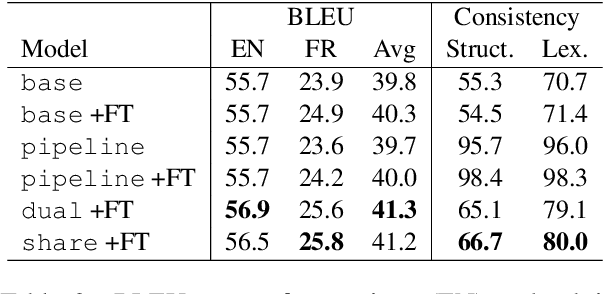
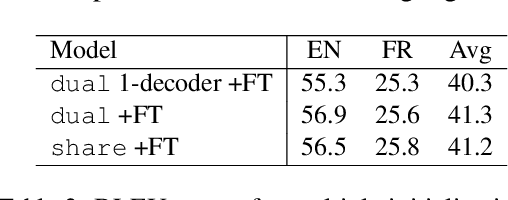
As the amount of audio-visual content increases, the need to develop automatic captioning and subtitling solutions to match the expectations of a growing international audience appears as the only viable way to boost throughput and lower the related post-production costs. Automatic captioning and subtitling often need to be tightly intertwined to achieve an appropriate level of consistency and synchronization with each other and with the video signal. In this work, we assess a dual decoding scheme to achieve a strong coupling between these two tasks and show how adequacy and consistency are increased, with virtually no additional cost in terms of model size and training complexity.
One Source, Two Targets: Challenges and Rewards of Dual Decoding
Sep 21, 2021



Machine translation is generally understood as generating one target text from an input source document. In this paper, we consider a stronger requirement: to jointly generate two texts so that each output side effectively depends on the other. As we discuss, such a device serves several practical purposes, from multi-target machine translation to the generation of controlled variations of the target text. We present an analysis of possible implementations of dual decoding, and experiment with four applications. Viewing the problem from multiple angles allows us to better highlight the challenges of dual decoding and to also thoroughly analyze the benefits of generating matched, rather than independent, translations.
Can You Traducir This? Machine Translation for Code-Switched Input
May 11, 2021
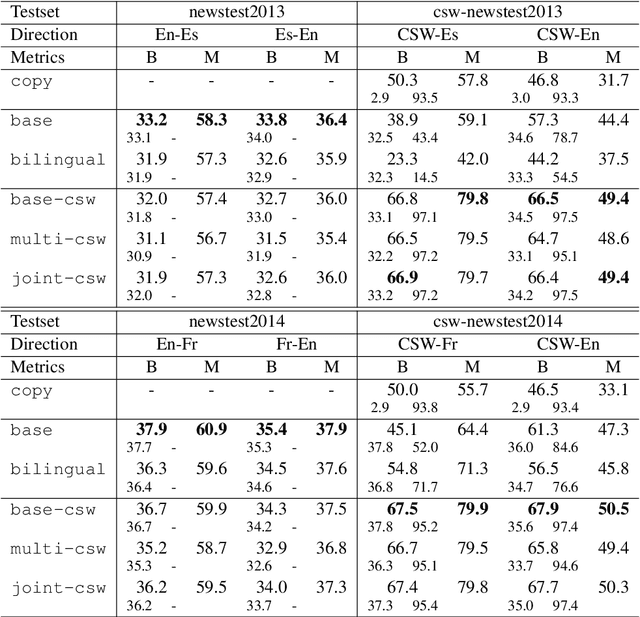
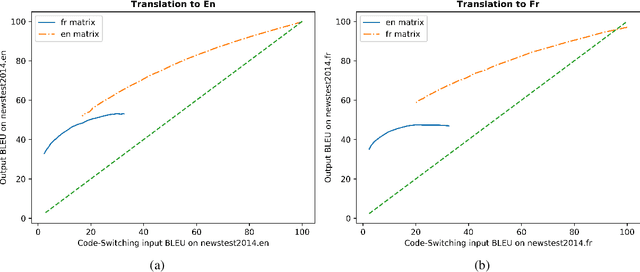

Code-Switching (CSW) is a common phenomenon that occurs in multilingual geographic or social contexts, which raises challenging problems for natural language processing tools. We focus here on Machine Translation (MT) of CSW texts, where we aim to simultaneously disentangle and translate the two mixed languages. Due to the lack of actual translated CSW data, we generate artificial training data from regular parallel texts. Experiments show this training strategy yields MT systems that surpass multilingual systems for code-switched texts. These results are confirmed in an alternative task aimed at providing contextual translations for a L2 writing assistant.