 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA DVL Aided Loosely Coupled Inertial Navigation Strategy for AUVs with Attitude Error Modeling and Variance Propagation
Jan 27, 2026In underwater navigation systems, strap-down inertial navigation system/Doppler velocity log (SINS/DVL)-based loosely coupled architectures are widely adopted. Conventional approaches project DVL velocities from the body coordinate system to the navigation coordinate system using SINS-derived attitude; however, accumulated attitude estimation errors introduce biases into velocity projection and degrade navigation performance during long-term operation. To address this issue, two complementary improvements are introduced. First, a vehicle attitude error-aware DVL velocity transformation model is formulated by incorporating attitude error terms into the observation equation to reduce projection-induced velocity bias. Second, a covariance matrix-based variance propagation method is developed to transform DVL measurement uncertainty across coordinate systems, introducing an expectation-based attitude error compensation term to achieve statistically consistent noise modeling. Simulation and field experiment results demonstrate that both improvements individually enhance navigation accuracy and confirm that accumulated attitude errors affect both projected velocity measurements and their associated uncertainty. When jointly applied, long-term error divergence is effectively suppressed. Field experimental results show that the proposed approach achieves a 78.3% improvement in 3D position RMSE and a 71.8% reduction in the maximum component-wise position error compared with the baseline IMU+DVL method, providing a robust solution for improving long-term SINS/DVL navigation performance.
Reimagining Social Robots as Recommender Systems: Foundations, Framework, and Applications
Jan 27, 2026Personalization in social robots refers to the ability of the robot to meet the needs and/or preferences of an individual user. Existing approaches typically rely on large language models (LLMs) to generate context-aware responses based on user metadata and historical interactions or on adaptive methods such as reinforcement learning (RL) to learn from users' immediate reactions in real time. However, these approaches fall short of comprehensively capturing user preferences-including long-term, short-term, and fine-grained aspects-, and of using them to rank and select actions, proactively personalize interactions, and ensure ethically responsible adaptations. To address the limitations, we propose drawing on recommender systems (RSs), which specialize in modeling user preferences and providing personalized recommendations. To ensure the integration of RS techniques is well-grounded and seamless throughout the social robot pipeline, we (i) align the paradigms underlying social robots and RSs, (ii) identify key techniques that can enhance personalization in social robots, and (iii) design them as modular, plug-and-play components. This work not only establishes a framework for integrating RS techniques into social robots but also opens a pathway for deep collaboration between the RS and HRI communities, accelerating innovation in both fields.
The Unfairness of Multifactorial Bias in Recommendation
Jan 19, 2026Popularity bias and positivity bias are two prominent sources of bias in recommender systems. Both arise from input data, propagate through recommendation models, and lead to unfair or suboptimal outcomes. Popularity bias occurs when a small subset of items receives most interactions, while positivity bias stems from the over-representation of high rating values. Although each bias has been studied independently, their combined effect, to which we refer to as multifactorial bias, remains underexplored. In this work, we examine how multifactorial bias influences item-side fairness, focusing on exposure bias, which reflects the unequal visibility of items in recommendation outputs. Through simulation studies, we find that positivity bias is disproportionately concentrated on popular items, further amplifying their over-exposure. Motivated by this insight, we adapt a percentile-based rating transformation as a pre-processing strategy to mitigate multifactorial bias. Experiments using six recommendation algorithms across four public datasets show that this approach improves exposure fairness with negligible accuracy loss. We also demonstrate that integrating this pre-processing step into post-processing fairness pipelines enhances their effectiveness and efficiency, enabling comparable or better fairness with reduced computational cost. These findings highlight the importance of addressing multifactorial bias and demonstrate the practical value of simple, data-driven pre-processing methods for improving fairness in recommender systems.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
Your Reasoning Benchmark May Not Test Reasoning: Revealing Perception Bottleneck in Abstract Reasoning Benchmarks
Dec 24, 2025Reasoning benchmarks such as the Abstraction and Reasoning Corpus (ARC) and ARC-AGI are widely used to assess progress in artificial intelligence and are often interpreted as probes of core, so-called ``fluid'' reasoning abilities. Despite their apparent simplicity for humans, these tasks remain challenging for frontier vision-language models (VLMs), a gap commonly attributed to deficiencies in machine reasoning. We challenge this interpretation and hypothesize that the gap arises primarily from limitations in visual perception rather than from shortcomings in inductive reasoning. To verify this hypothesis, we introduce a two-stage experimental pipeline that explicitly separates perception and reasoning. In the perception stage, each image is independently converted into a natural-language description, while in the reasoning stage a model induces and applies rules using these descriptions. This design prevents leakage of cross-image inductive signals and isolates reasoning from perception bottlenecks. Across three ARC-style datasets, Mini-ARC, ACRE, and Bongard-LOGO, we show that the perception capability is the dominant factor underlying the observed performance gap by comparing the two-stage pipeline with against standard end-to-end one-stage evaluation. Manual inspection of reasoning traces in the VLM outputs further reveals that approximately 80 percent of model failures stem from perception errors. Together, these results demonstrate that ARC-style benchmarks conflate perceptual and reasoning challenges and that observed performance gaps may overstate deficiencies in machine reasoning. Our findings underscore the need for evaluation protocols that disentangle perception from reasoning when assessing progress in machine intelligence.
Raspi$^2$USBL: An open-source Raspberry Pi-Based Passive Inverted Ultra-Short Baseline Positioning System for Underwater Robotics
Nov 10, 2025Precise underwater positioning remains a fundamental challenge for underwater robotics since global navigation satellite system (GNSS) signals cannot penetrate the sea surface. This paper presents Raspi$^2$USBL, an open-source, Raspberry Pi-based passive inverted ultra-short baseline (piUSBL) positioning system designed to provide a low-cost and accessible solution for underwater robotic research. The system comprises a passive acoustic receiver and an active beacon. The receiver adopts a modular hardware architecture that integrates a hydrophone array, a multichannel preamplifier, an oven-controlled crystal oscillator (OCXO), a Raspberry Pi 5, and an MCC-series data acquisition (DAQ) board. Apart from the Pi 5, OCXO, and MCC board, the beacon comprises an impedance-matching network, a power amplifier, and a transmitting transducer. An open-source C++ software framework provides high-precision clock synchronization and triggering for one-way travel-time (OWTT) messaging, while performing real-time signal processing, including matched filtering, array beamforming, and adaptive gain control, to estimate the time of flight (TOF) and direction of arrival (DOA) of received signals. The Raspi$^2$USBL system was experimentally validated in an anechoic tank, freshwater lake, and open-sea trials. Results demonstrate a slant-range accuracy better than 0.1%, a bearing accuracy within 0.1$^\circ$, and stable performance over operational distances up to 1.3 km. These findings confirm that low-cost, reproducible hardware can deliver research-grade underwater positioning accuracy. By releasing both the hardware and software as open-source, Raspi$^2$USBL provides a unified reference platform that lowers the entry barrier for underwater robotics laboratories, fosters reproducibility, and promotes collaborative innovation in underwater acoustic navigation and swarm robotics.
AsyMoE: Leveraging Modal Asymmetry for Enhanced Expert Specialization in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) have demonstrated impressive performance on multimodal tasks through scaled architectures and extensive training. However, existing Mixture of Experts (MoE) approaches face challenges due to the asymmetry between visual and linguistic processing. Visual information is spatially complete, while language requires maintaining sequential context. As a result, MoE models struggle to balance modality-specific features and cross-modal interactions. Through systematic analysis, we observe that language experts in deeper layers progressively lose contextual grounding and rely more on parametric knowledge rather than utilizing the provided visual and linguistic information. To address this, we propose AsyMoE, a novel architecture that models this asymmetry using three specialized expert groups. We design intra-modality experts for modality-specific processing, hyperbolic inter-modality experts for hierarchical cross-modal interactions, and evidence-priority language experts to suppress parametric biases and maintain contextual grounding. Extensive experiments demonstrate that AsyMoE achieves 26.58% and 15.45% accuracy improvements over vanilla MoE and modality-specific MoE respectively, with 25.45% fewer activated parameters than dense models.
FUTURE: Flexible Unlearning for Tree Ensemble
Aug 28, 2025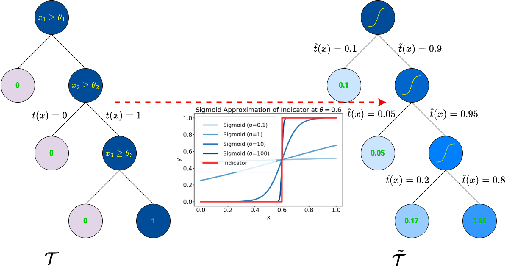
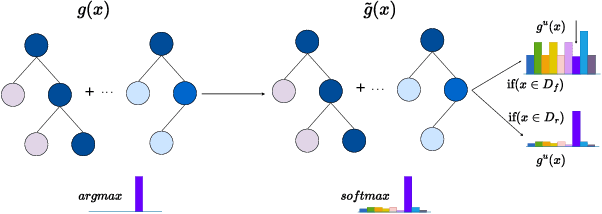
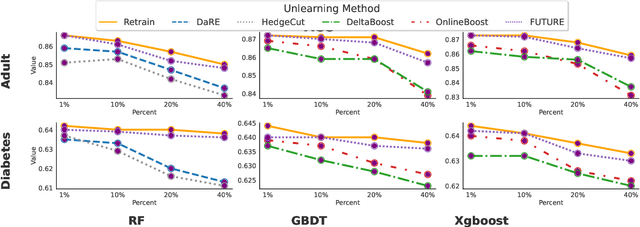
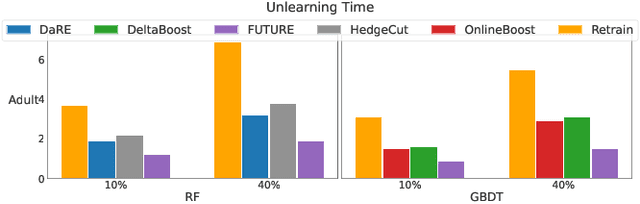
Tree ensembles are widely recognized for their effectiveness in classification tasks, achieving state-of-the-art performance across diverse domains, including bioinformatics, finance, and medical diagnosis. With increasing emphasis on data privacy and the \textit{right to be forgotten}, several unlearning algorithms have been proposed to enable tree ensembles to forget sensitive information. However, existing methods are often tailored to a particular model or rely on the discrete tree structure, making them difficult to generalize to complex ensembles and inefficient for large-scale datasets. To address these limitations, we propose FUTURE, a novel unlearning algorithm for tree ensembles. Specifically, we formulate the problem of forgetting samples as a gradient-based optimization task. In order to accommodate non-differentiability of tree ensembles, we adopt the probabilistic model approximations within the optimization framework. This enables end-to-end unlearning in an effective and efficient manner. Extensive experiments on real-world datasets show that FUTURE yields significant and successful unlearning performance.
J-DDL: Surface Damage Detection and Localization System for Fighter Aircraft
Jun 12, 2025Ensuring the safety and extended operational life of fighter aircraft necessitates frequent and exhaustive inspections. While surface defect detection is feasible for human inspectors, manual methods face critical limitations in scalability, efficiency, and consistency due to the vast surface area, structural complexity, and operational demands of aircraft maintenance. We propose a smart surface damage detection and localization system for fighter aircraft, termed J-DDL. J-DDL integrates 2D images and 3D point clouds of the entire aircraft surface, captured using a combined system of laser scanners and cameras, to achieve precise damage detection and localization. Central to our system is a novel damage detection network built on the YOLO architecture, specifically optimized for identifying surface defects in 2D aircraft images. Key innovations include lightweight Fasternet blocks for efficient feature extraction, an optimized neck architecture incorporating Efficient Multiscale Attention (EMA) modules for superior feature aggregation, and the introduction of a novel loss function, Inner-CIOU, to enhance detection accuracy. After detecting damage in 2D images, the system maps the identified anomalies onto corresponding 3D point clouds, enabling accurate 3D localization of defects across the aircraft surface. Our J-DDL not only streamlines the inspection process but also ensures more comprehensive and detailed coverage of large and complex aircraft exteriors. To facilitate further advancements in this domain, we have developed the first publicly available dataset specifically focused on aircraft damage. Experimental evaluations validate the effectiveness of our framework, underscoring its potential to significantly advance automated aircraft inspection technologies.
Hierarchical Error Assessment of CAD Models for Aircraft Manufacturing-and-Measurement
Jun 12, 2025The most essential feature of aviation equipment is high quality, including high performance, high stability and high reliability. In this paper, we propose a novel hierarchical error assessment framework for aircraft CAD models within a manufacturing-and-measurement platform, termed HEA-MM. HEA-MM employs structured light scanners to obtain comprehensive 3D measurements of manufactured workpieces. The measured point cloud is registered with the reference CAD model, followed by an error analysis conducted at three hierarchical levels: global, part, and feature. At the global level, the error analysis evaluates the overall deviation of the scanned point cloud from the reference CAD model. At the part level, error analysis is performed on these patches underlying the point clouds. We propose a novel optimization-based primitive refinement method to obtain a set of meaningful patches of point clouds. Two basic operations, splitting and merging, are introduced to refine the coarse primitives. At the feature level, error analysis is performed on circular holes, which are commonly found in CAD models. To facilitate it, a two-stage algorithm is introduced for the detection of circular holes. First, edge points are identified using a tensor-voting algorithm. Then, multiple circles are fitted through a hypothesize-and-clusterize framework, ensuring accurate detection and analysis of the circular features. Experimental results on various aircraft CAD models demonstrate the effectiveness of our proposed method.