 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Language Models in Neural News Recommender Systems
Paper and Code


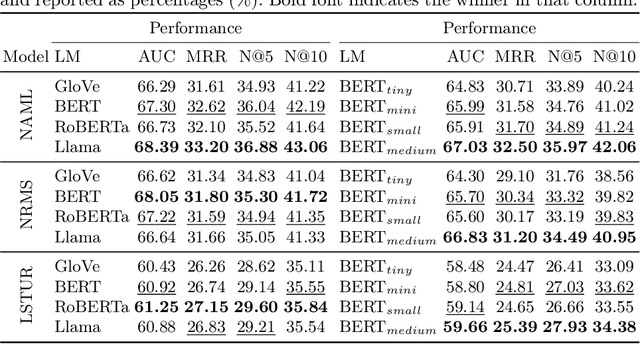

Neural news recommender systems (RSs) have integrated language models (LMs) to encode news articles with rich textual information into representations, thereby improving the recommendation process. Most studies suggest that (i) news RSs achieve better performance with larger pre-trained language models (PLMs) than shallow language models (SLMs), and (ii) that large language models (LLMs) outperform PLMs. However, other studies indicate that PLMs sometimes lead to worse performance than SLMs. Thus, it remains unclear whether using larger LMs consistently improves the performance of news RSs. In this paper, we revisit, unify, and extend these comparisons of the effectiveness of LMs in news RSs using the real-world MIND dataset. We find that (i) larger LMs do not necessarily translate to better performance in news RSs, and (ii) they require stricter fine-tuning hyperparameter selection and greater computational resources to achieve optimal recommendation performance than smaller LMs. On the positive side, our experiments show that larger LMs lead to better recommendation performance for cold-start users: they alleviate dependency on extensive user interaction history and make recommendations more reliant on the news content.