 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoIdeator: Evolving Scientific Ideas through Checklist-Grounded Reinforcement Learning
Mar 23, 2026Scientific idea generation is a cornerstone of autonomous knowledge discovery, yet the iterative evolution required to transform initial concepts into high-quality research proposals remains a formidable challenge for Large Language Models (LLMs). Existing Reinforcement Learning (RL) paradigms often rely on rubric-based scalar rewards that provide global quality scores but lack actionable granularity. Conversely, language-based refinement methods are typically confined to inference-time prompting, targeting models that are not explicitly optimized to internalize such critiques. To bridge this gap, we propose \textbf{EvoIdeator}, a framework that facilitates the evolution of scientific ideas by aligning the RL training objective with \textbf{checklist-grounded feedback}. EvoIdeator leverages a structured judge model to generate two synergistic signals: (1) \emph{lexicographic rewards} for multi-dimensional optimization, and (2) \emph{fine-grained language feedback} that offers span-level critiques regarding grounding, feasibility, and methodological rigor. By integrating these signals into the RL loop, we condition the policy to systematically utilize precise feedback during both optimization and inference. Extensive experiments demonstrate that EvoIdeator, built on Qwen3-4B, significantly outperforms much larger frontier models across key scientific metrics. Crucially, the learned policy exhibits strong generalization to diverse external feedback sources without further fine-tuning, offering a scalable and rigorous path toward self-refining autonomous ideation.
EvoScientist: Towards Multi-Agent Evolving AI Scientists for End-to-End Scientific Discovery
Mar 09, 2026The increasing adoption of Large Language Models (LLMs) has enabled AI scientists to perform complex end-to-end scientific discovery tasks requiring coordination of specialized roles, including idea generation and experimental execution. However, most state-of-the-art AI scientist systems rely on static, hand-designed pipelines and fail to adapt based on accumulated interaction histories. As a result, these systems overlook promising research directions, repeat failed experiments, and pursue infeasible ideas. To address this, we introduce EvoScientist, an evolving multi-agent AI scientist framework that continuously improves research strategies through persistent memory and self-evolution. EvoScientist comprises three specialized agents: a Researcher Agent (RA) for scientific idea generation, an Engineer Agent (EA) for experiment implementation and execution, and an Evolution Manager Agent (EMA) that distills insights from prior interactions into reusable knowledge. EvoScientist contains two persistent memory modules: (i) an ideation memory, which summarizes feasible research directions from top-ranked ideas while recording previously unsuccessful directions; and (ii) an experimentation memory, which captures effective data processing and model training strategies derived from code search trajectories and best-performing implementations. These modules enable the RA and EA to retrieve relevant prior strategies, improving idea quality and code execution success rates over time. Experiments show that EvoScientist outperforms 7 open-source and commercial state-of-the-art systems in scientific idea generation, achieving higher novelty, feasibility, relevance, and clarity via automatic and human evaluation. EvoScientist also substantially improves code execution success rates through multi-agent evolution, demonstrating persistent memory's effectiveness for end-to-end scientific discovery.
Revisiting Language Models in Neural News Recommender Systems
Jan 20, 2025

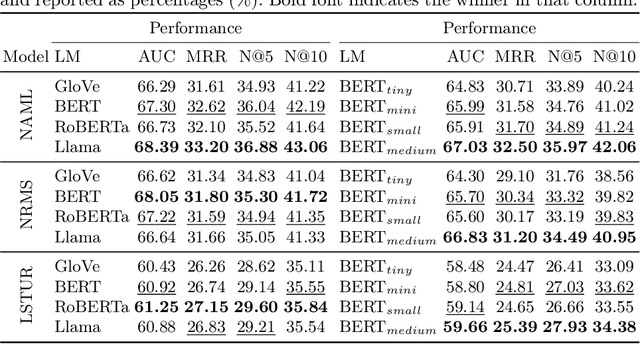

Neural news recommender systems (RSs) have integrated language models (LMs) to encode news articles with rich textual information into representations, thereby improving the recommendation process. Most studies suggest that (i) news RSs achieve better performance with larger pre-trained language models (PLMs) than shallow language models (SLMs), and (ii) that large language models (LLMs) outperform PLMs. However, other studies indicate that PLMs sometimes lead to worse performance than SLMs. Thus, it remains unclear whether using larger LMs consistently improves the performance of news RSs. In this paper, we revisit, unify, and extend these comparisons of the effectiveness of LMs in news RSs using the real-world MIND dataset. We find that (i) larger LMs do not necessarily translate to better performance in news RSs, and (ii) they require stricter fine-tuning hyperparameter selection and greater computational resources to achieve optimal recommendation performance than smaller LMs. On the positive side, our experiments show that larger LMs lead to better recommendation performance for cold-start users: they alleviate dependency on extensive user interaction history and make recommendations more reliant on the news content.
EvoWiki: Evaluating LLMs on Evolving Knowledge
Dec 18, 2024
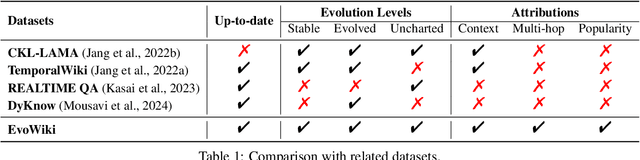
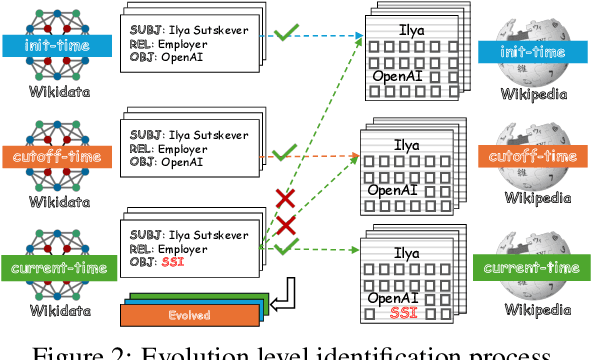
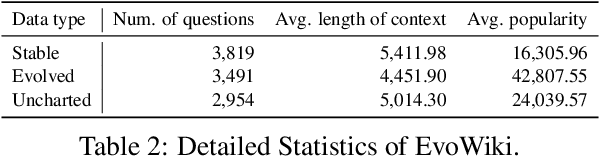
Knowledge utilization is a critical aspect of LLMs, and understanding how they adapt to evolving knowledge is essential for their effective deployment. However, existing benchmarks are predominantly static, failing to capture the evolving nature of LLMs and knowledge, leading to inaccuracies and vulnerabilities such as contamination. In this paper, we introduce EvoWiki, an evolving dataset designed to reflect knowledge evolution by categorizing information into stable, evolved, and uncharted states. EvoWiki is fully auto-updatable, enabling precise evaluation of continuously changing knowledge and newly released LLMs. Through experiments with Retrieval-Augmented Generation (RAG) and Contunual Learning (CL), we evaluate how effectively LLMs adapt to evolving knowledge. Our results indicate that current models often struggle with evolved knowledge, frequently providing outdated or incorrect responses. Moreover, the dataset highlights a synergistic effect between RAG and CL, demonstrating their potential to better adapt to evolving knowledge. EvoWiki provides a robust benchmark for advancing future research on the knowledge evolution capabilities of large language models.
A + B: A General Generator-Reader Framework for Optimizing LLMs to Unleash Synergy Potential
Jun 06, 2024



Retrieval-Augmented Generation (RAG) is an effective solution to supplement necessary knowledge to large language models (LLMs). Targeting its bottleneck of retriever performance, "generate-then-read" pipeline is proposed to replace the retrieval stage with generation from the LLM itself. Although promising, this research direction is underexplored and still cannot work in the scenario when source knowledge is given. In this paper, we formalize a general "A + B" framework with varying combinations of foundation models and types for systematic investigation. We explore the efficacy of the base and chat versions of LLMs and found their different functionalities suitable for generator A and reader B, respectively. Their combinations consistently outperform single models, especially in complex scenarios. Furthermore, we extend the application of the "A + B" framework to scenarios involving source documents through continuous learning, enabling the direct integration of external knowledge into LLMs. This approach not only facilitates effective acquisition of new knowledge but also addresses the challenges of safety and helpfulness post-adaptation. The paper underscores the versatility of the "A + B" framework, demonstrating its potential to enhance the practical application of LLMs across various domains.
Let Me Do It For You: Towards LLM Empowered Recommendation via Tool Learning
May 24, 2024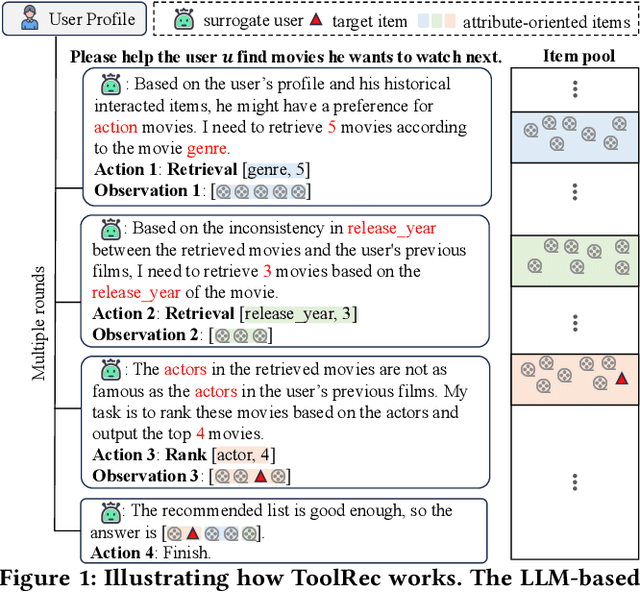
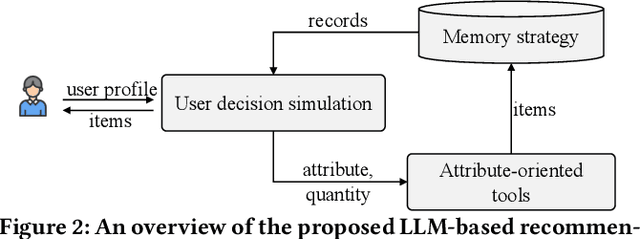
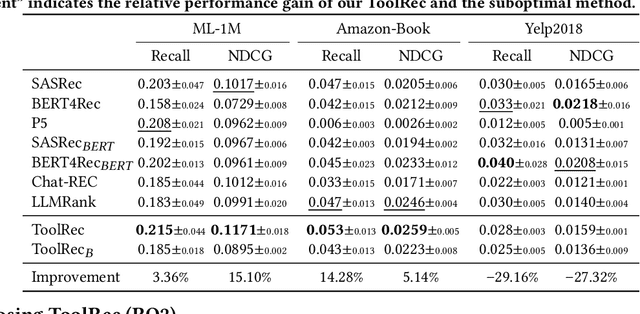
Conventional recommender systems (RSs) face challenges in precisely capturing users' fine-grained preferences. Large language models (LLMs) have shown capabilities in commonsense reasoning and leveraging external tools that may help address these challenges. However, existing LLM-based RSs suffer from hallucinations, misalignment between the semantic space of items and the behavior space of users, or overly simplistic control strategies (e.g., whether to rank or directly present existing results). To bridge these gap, we introduce ToolRec, a framework for LLM-empowered recommendations via tool learning that uses LLMs as surrogate users, thereby guiding the recommendation process and invoking external tools to generate a recommendation list that aligns closely with users' nuanced preferences. We formulate the recommendation process as a process aimed at exploring user interests in attribute granularity. The process factors in the nuances of the context and user preferences. The LLM then invokes external tools based on a user's attribute instructions and probes different segments of the item pool. We consider two types of attribute-oriented tools: rank tools and retrieval tools. Through the integration of LLMs, ToolRec enables conventional recommender systems to become external tools with a natural language interface. Extensive experiments verify the effectiveness of ToolRec, particularly in scenarios that are rich in semantic content.
UniRel: Unified Representation and Interaction for Joint Relational Triple Extraction
Nov 16, 2022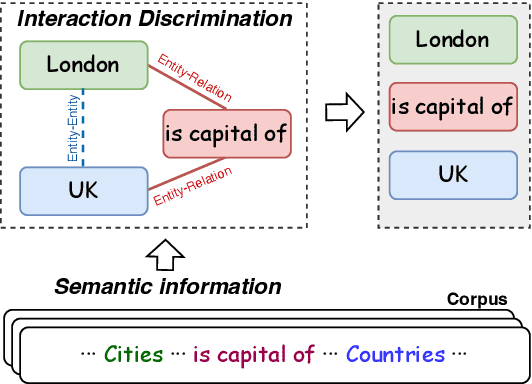
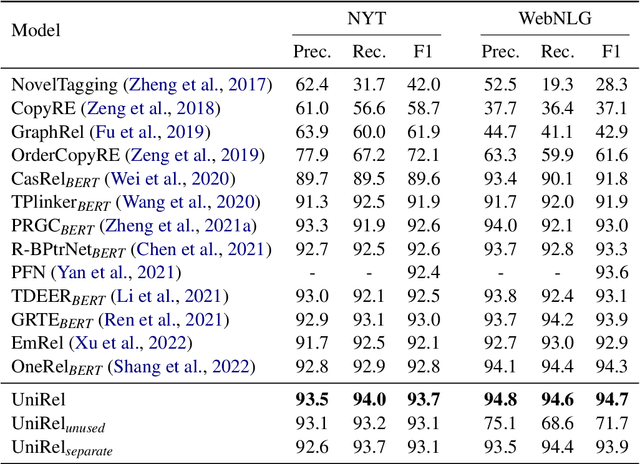
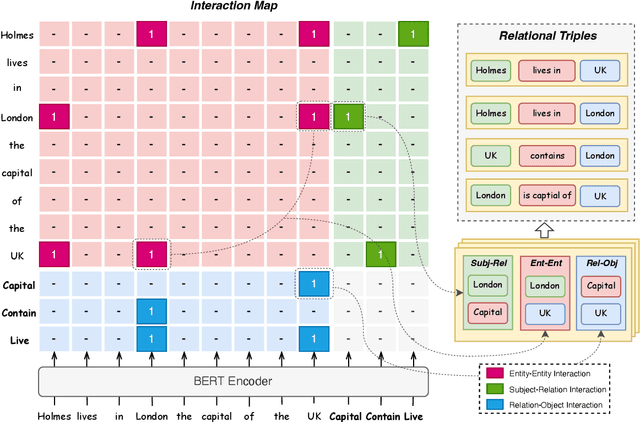
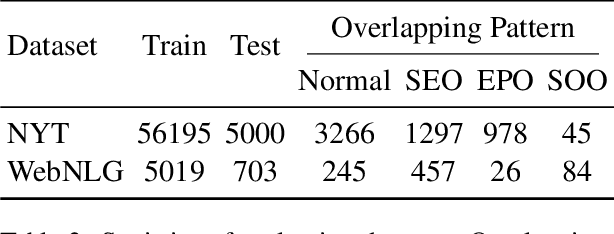
Relational triple extraction is challenging for its difficulty in capturing rich correlations between entities and relations. Existing works suffer from 1) heterogeneous representations of entities and relations, and 2) heterogeneous modeling of entity-entity interactions and entity-relation interactions. Therefore, the rich correlations are not fully exploited by existing works. In this paper, we propose UniRel to address these challenges. Specifically, we unify the representations of entities and relations by jointly encoding them within a concatenated natural language sequence, and unify the modeling of interactions with a proposed Interaction Map, which is built upon the off-the-shelf self-attention mechanism within any Transformer block. With comprehensive experiments on two popular relational triple extraction datasets, we demonstrate that UniRel is more effective and computationally efficient. The source code is available at https://github.com/wtangdev/UniRel.
Time-aware Path Reasoning on Knowledge Graph for Recommendation
Aug 05, 2021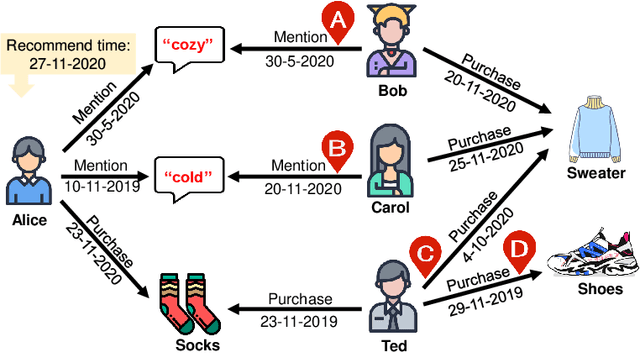
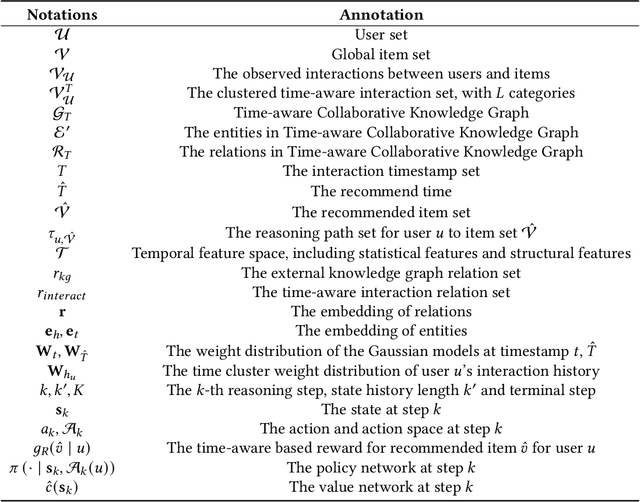
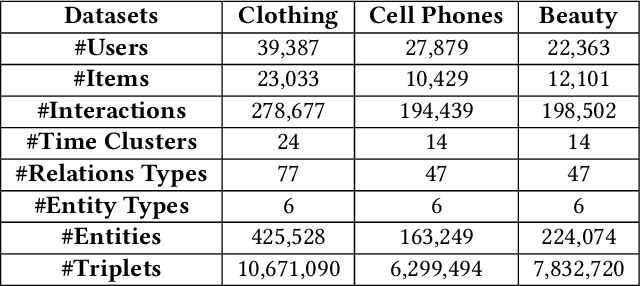
Reasoning on knowledge graph (KG) has been studied for explainable recommendation due to it's ability of providing explicit explanations. However, current KG-based explainable recommendation methods unfortunately ignore the temporal information (such as purchase time, recommend time, etc.), which may result in unsuitable explanations. In this work, we propose a novel Time-aware Path reasoning for Recommendation (TPRec for short) method, which leverages the potential of temporal information to offer better recommendation with plausible explanations. First, we present an efficient time-aware interaction relation extraction component to construct collaborative knowledge graph with time-aware interactions (TCKG for short), and then introduce a novel time-aware path reasoning method for recommendation. We conduct extensive experiments on three real-world datasets. The results demonstrate that the proposed TPRec could successfully employ TCKG to achieve substantial gains and improve the quality of explainable recommendation.