 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARM: Role-Conditioned Neuron Transplantation for Training-Free Generalist LLM Agent Merging
Jan 12, 2026Interactive large language model agents have advanced rapidly, but most remain specialized to a single environment and fail to adapt robustly to other environments. Model merging offers a training-free alternative by integrating multiple experts into a single model. In this paper, we propose Agent-Role Merging (ARM), an activation-guided, role-conditioned neuron transplantation method for model merging in LLM agents. ARM improves existing merging methods from static natural language tasks to multi-turn agent scenarios, and over the generalization ability across various interactive environments. This is achieved with a well designed 3-step framework: 1) constructing merged backbones, 2) selection based on its role-conditioned activation analysis, and 3) neuron transplantation for fine-grained refinements. Without gradient-based optimization, ARM improves cross-benchmark generalization while enjoying efficiency. Across diverse domains, the model obtained via ARM merging outperforms prior model merging methods and domain-specific expert models, while demonstrating strong out-of-domain generalization.
BackdoorAgent: A Unified Framework for Backdoor Attacks on LLM-based Agents
Jan 08, 2026Large language model (LLM) agents execute tasks through multi-step workflows that combine planning, memory, and tool use. While this design enables autonomy, it also expands the attack surface for backdoor threats. Backdoor triggers injected into specific stages of an agent workflow can persist through multiple intermediate states and adversely influence downstream outputs. However, existing studies remain fragmented and typically analyze individual attack vectors in isolation, leaving the cross-stage interaction and propagation of backdoor triggers poorly understood from an agent-centric perspective. To fill this gap, we propose \textbf{BackdoorAgent}, a modular and stage-aware framework that provides a unified, agent-centric view of backdoor threats in LLM agents. BackdoorAgent structures the attack surface into three functional stages of agentic workflows, including \textbf{planning attacks}, \textbf{memory attacks}, and \textbf{tool-use attacks}, and instruments agent execution to enable systematic analysis of trigger activation and propagation across different stages. Building on this framework, we construct a standardized benchmark spanning four representative agent applications: \textbf{Agent QA}, \textbf{Agent Code}, \textbf{Agent Web}, and \textbf{Agent Drive}, covering both language-only and multimodal settings. Our empirical analysis shows that \textit{triggers implanted at a single stage can persist across multiple steps and propagate through intermediate states.} For instance, when using a GPT-based backbone, we observe trigger persistence in 43.58\% of planning attacks, 77.97\% of memory attacks, and 60.28\% of tool-stage attacks, highlighting the vulnerabilities of the agentic workflow itself to backdoor threats. To facilitate reproducibility and future research, our code and benchmark are publicly available at GitHub.
HumanoidGen: Data Generation for Bimanual Dexterous Manipulation via LLM Reasoning
Jul 01, 2025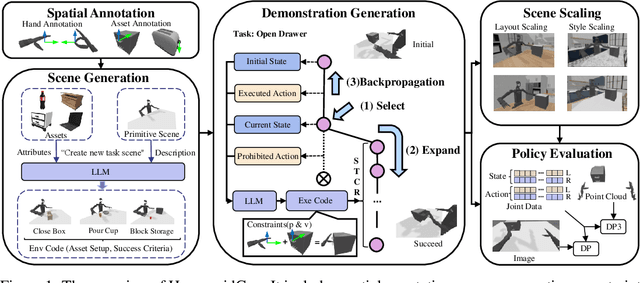
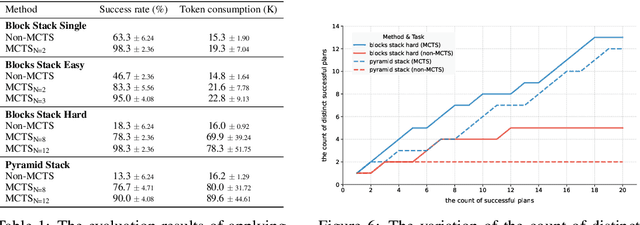
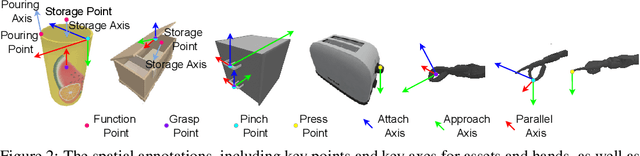
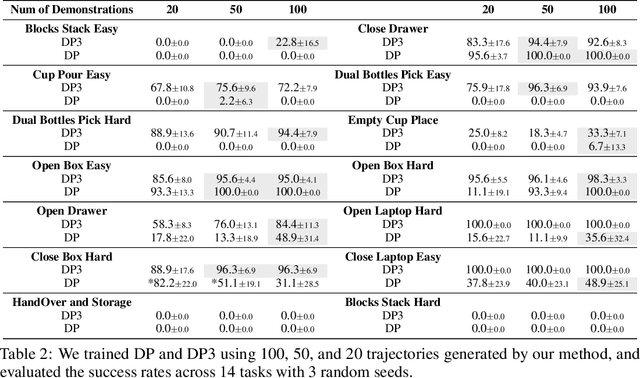
For robotic manipulation, existing robotics datasets and simulation benchmarks predominantly cater to robot-arm platforms. However, for humanoid robots equipped with dual arms and dexterous hands, simulation tasks and high-quality demonstrations are notably lacking. Bimanual dexterous manipulation is inherently more complex, as it requires coordinated arm movements and hand operations, making autonomous data collection challenging. This paper presents HumanoidGen, an automated task creation and demonstration collection framework that leverages atomic dexterous operations and LLM reasoning to generate relational constraints. Specifically, we provide spatial annotations for both assets and dexterous hands based on the atomic operations, and perform an LLM planner to generate a chain of actionable spatial constraints for arm movements based on object affordances and scenes. To further improve planning ability, we employ a variant of Monte Carlo tree search to enhance LLM reasoning for long-horizon tasks and insufficient annotation. In experiments, we create a novel benchmark with augmented scenarios to evaluate the quality of the collected data. The results show that the performance of the 2D and 3D diffusion policies can scale with the generated dataset. Project page is https://openhumanoidgen.github.io.
Revisiting LLM Evaluation through Mechanism Interpretability: a New Metric and Model Utility Law
Apr 10, 2025Large Language Models (LLMs) have become indispensable across academia, industry, and daily applications, yet current evaluation methods struggle to keep pace with their rapid development. In this paper, we analyze the core limitations of traditional evaluation pipelines and propose a novel metric, the Model Utilization Index (MUI), which introduces mechanism interpretability techniques to complement traditional performance metrics. MUI quantifies the extent to which a model leverages its capabilities to complete tasks. The core idea is that to assess an LLM's overall ability, we must evaluate not only its task performance but also the effort expended to achieve the outcome. Our extensive experiments reveal an inverse relationship between MUI and performance, from which we deduce a common trend observed in popular LLMs, which we term the Utility Law. Based on this, we derive four corollaries that address key challenges, including training judgement, the issue of data contamination, fairness in model comparison, and data diversity. We hope that our survey, novel metric, and utility law will foster mutual advancement in both evaluation and mechanism interpretability. Our code can be found at https://github.com/ALEX-nlp/MUI-Eva.
EvoWiki: Evaluating LLMs on Evolving Knowledge
Dec 18, 2024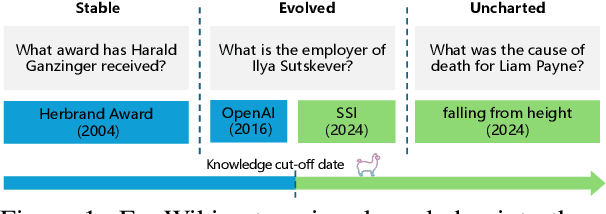
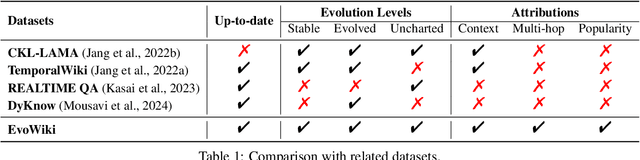
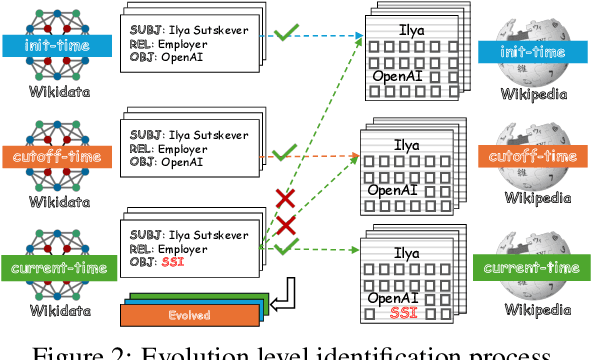
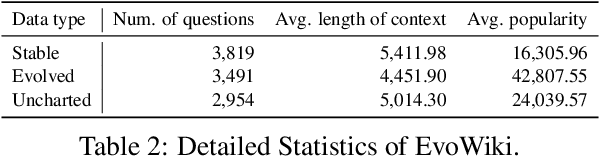
Knowledge utilization is a critical aspect of LLMs, and understanding how they adapt to evolving knowledge is essential for their effective deployment. However, existing benchmarks are predominantly static, failing to capture the evolving nature of LLMs and knowledge, leading to inaccuracies and vulnerabilities such as contamination. In this paper, we introduce EvoWiki, an evolving dataset designed to reflect knowledge evolution by categorizing information into stable, evolved, and uncharted states. EvoWiki is fully auto-updatable, enabling precise evaluation of continuously changing knowledge and newly released LLMs. Through experiments with Retrieval-Augmented Generation (RAG) and Contunual Learning (CL), we evaluate how effectively LLMs adapt to evolving knowledge. Our results indicate that current models often struggle with evolved knowledge, frequently providing outdated or incorrect responses. Moreover, the dataset highlights a synergistic effect between RAG and CL, demonstrating their potential to better adapt to evolving knowledge. EvoWiki provides a robust benchmark for advancing future research on the knowledge evolution capabilities of large language models.
RoDE: Linear Rectified Mixture of Diverse Experts for Food Large Multi-Modal Models
Jul 17, 2024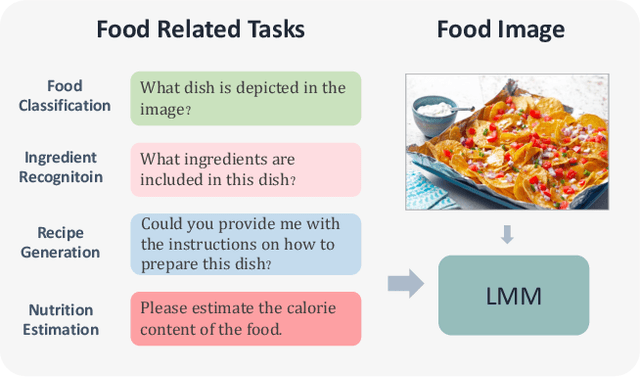



Large Multi-modal Models (LMMs) have significantly advanced a variety of vision-language tasks. The scalability and availability of high-quality training data play a pivotal role in the success of LMMs. In the realm of food, while comprehensive food datasets such as Recipe1M offer an abundance of ingredient and recipe information, they often fall short of providing ample data for nutritional analysis. The Recipe1M+ dataset, despite offering a subset for nutritional evaluation, is limited in the scale and accuracy of nutrition information. To bridge this gap, we introduce Uni-Food, a unified food dataset that comprises over 100,000 images with various food labels, including categories, ingredients, recipes, and ingredient-level nutritional information. Uni-Food is designed to provide a more holistic approach to food data analysis, thereby enhancing the performance and capabilities of LMMs in this domain. To mitigate the conflicts arising from multi-task supervision during fine-tuning of LMMs, we introduce a novel Linear Rectification Mixture of Diverse Experts (RoDE) approach. RoDE utilizes a diverse array of experts to address tasks of varying complexity, thereby facilitating the coordination of trainable parameters, i.e., it allocates more parameters for more complex tasks and, conversely, fewer parameters for simpler tasks. RoDE implements linear rectification union to refine the router's functionality, thereby enhancing the efficiency of sparse task allocation. These design choices endow RoDE with features that ensure GPU memory efficiency and ease of optimization. Our experimental results validate the effectiveness of our proposed approach in addressing the inherent challenges of food-related multitasking.
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Feb 26, 2024



We introduce AnyGPT, an any-to-any multimodal language model that utilizes discrete representations for the unified processing of various modalities, including speech, text, images, and music. AnyGPT can be trained stably without any alterations to the current large language model (LLM) architecture or training paradigms. Instead, it relies exclusively on data-level preprocessing, facilitating the seamless integration of new modalities into LLMs, akin to the incorporation of new languages. We build a multimodal text-centric dataset for multimodal alignment pre-training. Utilizing generative models, we synthesize the first large-scale any-to-any multimodal instruction dataset. It consists of 108k samples of multi-turn conversations that intricately interweave various modalities, thus equipping the model to handle arbitrary combinations of multimodal inputs and outputs. Experimental results demonstrate that AnyGPT is capable of facilitating any-to-any multimodal conversation while achieving performance comparable to specialized models across all modalities, proving that discrete representations can effectively and conveniently unify multiple modalities within a language model. Demos are shown in https://junzhan2000.github.io/AnyGPT.github.io/
Unlearnable Clusters: Towards Label-agnostic Unlearnable Examples
Dec 31, 2022There is a growing interest in developing unlearnable examples (UEs) against visual privacy leaks on the Internet. UEs are training samples added with invisible but unlearnable noise, which have been found can prevent unauthorized training of machine learning models. UEs typically are generated via a bilevel optimization framework with a surrogate model to remove (minimize) errors from the original samples, and then applied to protect the data against unknown target models. However, existing UE generation methods all rely on an ideal assumption called label-consistency, where the hackers and protectors are assumed to hold the same label for a given sample. In this work, we propose and promote a more practical label-agnostic setting, where the hackers may exploit the protected data quite differently from the protectors. E.g., a m-class unlearnable dataset held by the protector may be exploited by the hacker as a n-class dataset. Existing UE generation methods are rendered ineffective in this challenging setting. To tackle this challenge, we present a novel technique called Unlearnable Clusters (UCs) to generate label-agnostic unlearnable examples with cluster-wise perturbations. Furthermore, we propose to leverage VisionandLanguage Pre-trained Models (VLPMs) like CLIP as the surrogate model to improve the transferability of the crafted UCs to diverse domains. We empirically verify the effectiveness of our proposed approach under a variety of settings with different datasets, target models, and even commercial platforms Microsoft Azure and Baidu PaddlePaddle.