 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Pre-Pre-Training Improves Language Model Robustness to Noisy Pre-Training Data
May 11, 2026Large language models (LLMs) rely on web-scale corpora for pre-training. The noise inherent in these datasets tends to obscure meaningful patterns and ultimately degrade model performance. Data curation mitigates but cannot eliminate such noise, so pre-training corpora remain noisy in practice. We therefore study whether a lightweight pre-pre-training (PPT) stage based on synthetic data with learnable temporal structure helps resist noisy data during the pre-training (PT) stage. Across various corruption settings, our method consistently improves robustness to noise during PT, with larger relative gains at higher noise levels. For a 1B-parameter model, a synthetic PPT stage with only 65M tokens achieves the same final loss as the baseline while using up to 49\% fewer natural-text PT tokens across different noise levels. Mechanistic analyses suggest PPT does not immediately suppress attention to noisy tokens. Rather, PPT-initialized models gradually downweight attention between corrupted tokens during noisy PT. This indicates that synthetic PPT inhibits noise self-modeling and shapes the subsequent optimization trajectory. Code is available at https://github.com/guox18/formal-language-prepretraining.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Mousse: Rectifying the Geometry of Muon with Curvature-Aware Preconditioning
Mar 10, 2026Recent advances in spectral optimization, notably Muon, have demonstrated that constraining update steps to the Stiefel manifold can significantly accelerate training and improve generalization. However, Muon implicitly assumes an isotropic optimization landscape, enforcing a uniform spectral update norm across all eigen-directions. We argue that this "egalitarian" constraint is suboptimal for Deep Neural Networks, where the curvature spectrum is known to be highly heavy-tailed and ill-conditioned. In such landscapes, Muon risks amplifying instabilities in high-curvature directions while limiting necessary progress in flat directions. In this work, we propose \textbf{Mousse} (\textbf{M}uon \textbf{O}ptimization \textbf{U}tilizing \textbf{S}hampoo's \textbf{S}tructural \textbf{E}stimation), a novel optimizer that reconciles the structural stability of spectral methods with the geometric adaptivity of second-order preconditioning. Instead of applying Newton-Schulz orthogonalization directly to the momentum matrix, Mousse operates in a whitened coordinate system induced by Kronecker-factored statistics (derived from Shampoo). Mathematically, we formulate Mousse as the solution to a spectral steepest descent problem constrained by an anisotropic trust region, where the optimal update is derived via the polar decomposition of the whitened gradient. Empirical results across language models ranging from 160M to 800M parameters demonstrate that Mousse consistently outperforms Muon, achieving around $\sim$12\% reduction in training steps with negligible computational overhead.
Explicit Multi-head Attention for Inter-head Interaction in Large Language Models
Jan 27, 2026In large language models built upon the Transformer architecture, recent studies have shown that inter-head interaction can enhance attention performance. Motivated by this, we propose Multi-head Explicit Attention (MEA), a simple yet effective attention variant that explicitly models cross-head interaction. MEA consists of two key components: a Head-level Linear Composition (HLC) module that separately applies learnable linear combinations to the key and value vectors across heads, thereby enabling rich inter-head communication; and a head-level Group Normalization layer that aligns the statistical properties of the recombined heads. MEA shows strong robustness in pretraining, which allows the use of larger learning rates that lead to faster convergence, ultimately resulting in lower validation loss and improved performance across a range of tasks. Furthermore, we explore the parameter efficiency of MEA by reducing the number of attention heads and leveraging HLC to reconstruct them using low-rank "virtual heads". This enables a practical key-value cache compression strategy that reduces KV-cache memory usage by 50% with negligible performance loss on knowledge-intensive and scientific reasoning tasks, and only a 3.59% accuracy drop for Olympiad-level mathematical benchmarks.
Which Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Jan 20, 2026Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.
How to Set the Batch Size for Large-Scale Pre-training?
Jan 08, 2026The concept of Critical Batch Size, as pioneered by OpenAI, has long served as a foundational principle for large-scale pre-training. However, with the paradigm shift towards the Warmup-Stable-Decay (WSD) learning rate scheduler, we observe that the original theoretical framework and its underlying mechanisms fail to align with new pre-training dynamics. To bridge this gap between theory and practice, this paper derives a revised E(S) relationship tailored for WSD scheduler, characterizing the trade-off between training data consumption E and steps S during pre-training. Our theoretical analysis reveals two fundamental properties of WSD-based pre-training: 1) B_min, the minimum batch size threshold required to achieve a target loss, and 2) B_opt, the optimal batch size that maximizes data efficiency by minimizing total tokens. Building upon these properties, we propose a dynamic Batch Size Scheduler. Extensive experiments demonstrate that our revised formula precisely captures the dynamics of large-scale pre-training, and the resulting scheduling strategy significantly enhances both training efficiency and final model quality.
How to Set the Learning Rate for Large-Scale Pre-training?
Jan 08, 2026Optimal configuration of the learning rate (LR) is a fundamental yet formidable challenge in large-scale pre-training. Given the stringent trade-off between training costs and model performance, the pivotal question is whether the optimal LR can be accurately extrapolated from low-cost experiments. In this paper, we formalize this investigation into two distinct research paradigms: Fitting and Transfer. Within the Fitting Paradigm, we innovatively introduce a Scaling Law for search factor, effectively reducing the search complexity from O(n^3) to O(n*C_D*C_η) via predictive modeling. Within the Transfer Paradigm, we extend the principles of $μ$Transfer to the Mixture of Experts (MoE) architecture, broadening its applicability to encompass model depth, weight decay, and token horizons. By pushing the boundaries of existing hyperparameter research in terms of scale, we conduct a comprehensive comparison between these two paradigms. Our empirical results challenge the scalability of the widely adopted $μ$ Transfer in large-scale pre-training scenarios. Furthermore, we provide a rigorous analysis through the dual lenses of training stability and feature learning to elucidate the underlying reasons why module-wise parameter tuning underperforms in large-scale settings. This work offers systematic practical guidelines and a fresh theoretical perspective for optimizing industrial-level pre-training.
Capability Salience Vector: Fine-grained Alignment of Loss and Capabilities for Downstream Task Scaling Law
Jun 16, 2025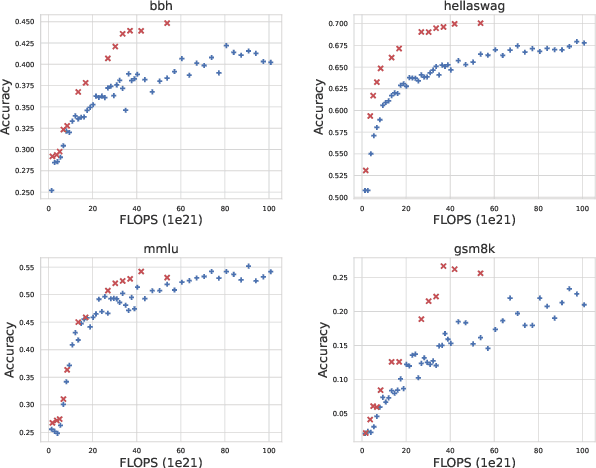
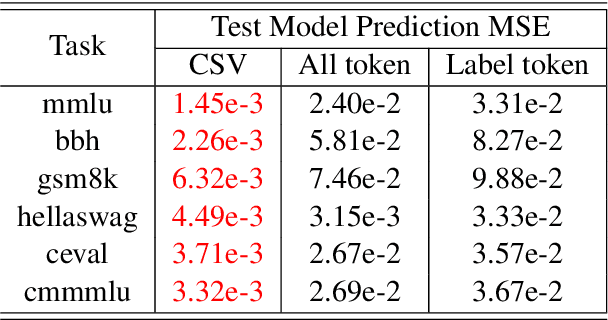
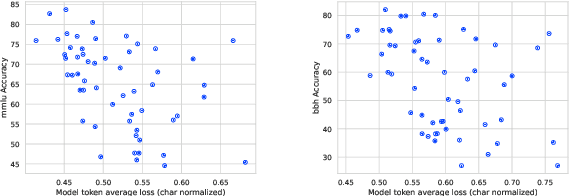
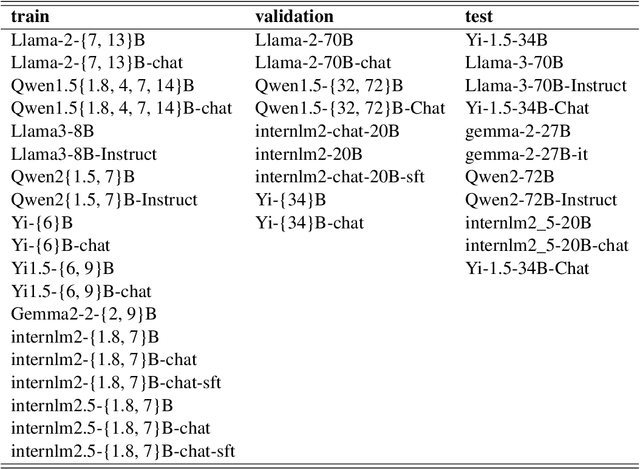
Scaling law builds the relationship between training computation and validation loss, enabling researchers to effectively predict the loss trending of models across different levels of computation. However, a gap still remains between validation loss and the model's downstream capabilities, making it untrivial to apply scaling law to direct performance prediction for downstream tasks. The loss typically represents a cumulative penalty for predicted tokens, which are implicitly considered to have equal importance. Nevertheless, our studies have shown evidence that when considering different training data distributions, we cannot directly model the relationship between downstream capability and computation or token loss. To bridge the gap between validation loss and downstream task capabilities, in this work, we introduce Capability Salience Vector, which decomposes the overall loss and assigns different importance weights to tokens to assess a specific meta-capability, aligning the validation loss with downstream task performance in terms of the model's capabilities. Experiments on various popular benchmarks demonstrate that our proposed Capability Salience Vector could significantly improve the predictability of language model performance on downstream tasks.
Revisiting the Test-Time Scaling of o1-like Models: Do they Truly Possess Test-Time Scaling Capabilities?
Feb 17, 2025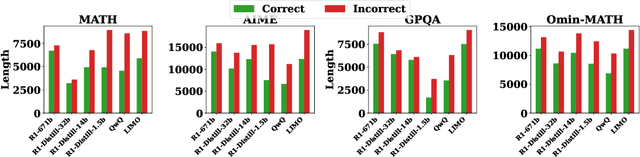

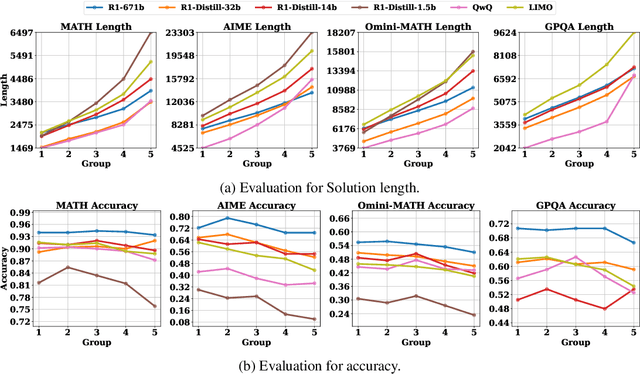
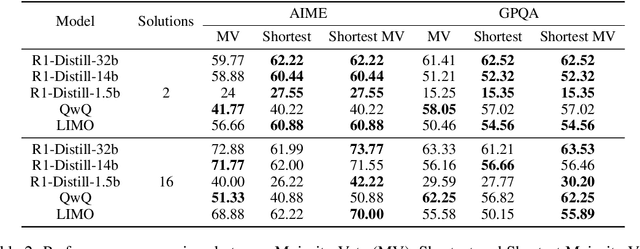
The advent of test-time scaling in large language models (LLMs), exemplified by OpenAI's o1 series, has advanced reasoning capabilities by scaling computational resource allocation during inference. While successors like QwQ, Deepseek-R1 (R1) and LIMO replicate these advancements, whether these models truly possess test-time scaling capabilities remains underexplored. This study found that longer CoTs of these o1-like models do not consistently enhance accuracy; in fact, correct solutions are often shorter than incorrect ones for the same questions. Further investigation shows this phenomenon is closely related to models' self-revision capabilities - longer CoTs contain more self-revisions, which often lead to performance degradation. We then compare sequential and parallel scaling strategies on QwQ, R1 and LIMO, finding that parallel scaling achieves better coverage and scalability. Based on these insights, we propose Shortest Majority Vote, a method that combines parallel scaling strategies with CoT length characteristics, significantly improving models' test-time scalability compared to conventional majority voting approaches.
Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective
Dec 18, 2024



OpenAI o1 represents a significant milestone in Artificial Inteiligence, which achieves expert-level performances on many challanging tasks that require strong reasoning ability.OpenAI has claimed that the main techinique behinds o1 is the reinforcement learining. Recent works use alternative approaches like knowledge distillation to imitate o1's reasoning style, but their effectiveness is limited by the capability ceiling of the teacher model. Therefore, this paper analyzes the roadmap to achieving o1 from the perspective of reinforcement learning, focusing on four key components: policy initialization, reward design, search, and learning. Policy initialization enables models to develop human-like reasoning behaviors, equipping them with the ability to effectively explore solution spaces for complex problems. Reward design provides dense and effective signals via reward shaping or reward modeling, which is the guidance for both search and learning. Search plays a crucial role in generating high-quality solutions during both training and testing phases, which can produce better solutions with more computation. Learning utilizes the data generated by search for improving policy, which can achieve the better performance with more parameters and more searched data. Existing open-source projects that attempt to reproduce o1 can be seem as a part or a variant of our roadmap. Collectively, these components underscore how learning and search drive o1's advancement, making meaningful contributions to the development of LLM.