 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding the Nature of Attention with Low-Rank Sparse Decomposition
Apr 29, 2025We propose Low-Rank Sparse Attention (Lorsa), a sparse replacement model of Transformer attention layers to disentangle original Multi Head Self Attention (MHSA) into individually comprehensible components. Lorsa is designed to address the challenge of attention superposition to understand attention-mediated interaction between features in different token positions. We show that Lorsa heads find cleaner and finer-grained versions of previously discovered MHSA behaviors like induction heads, successor heads and attention sink behavior (i.e., heavily attending to the first token). Lorsa and Sparse Autoencoder (SAE) are both sparse dictionary learning methods applied to different Transformer components, and lead to consistent findings in many ways. For instance, we discover a comprehensive family of arithmetic-specific Lorsa heads, each corresponding to an atomic operation in Llama-3.1-8B. Automated interpretability analysis indicates that Lorsa achieves parity with SAE in interpretability while Lorsa exhibits superior circuit discovery properties, especially for features computed collectively by multiple MHSA heads. We also conduct extensive experiments on architectural design ablation, Lorsa scaling law and error analysis.
Towards Universality: Studying Mechanistic Similarity Across Language Model Architectures
Oct 10, 2024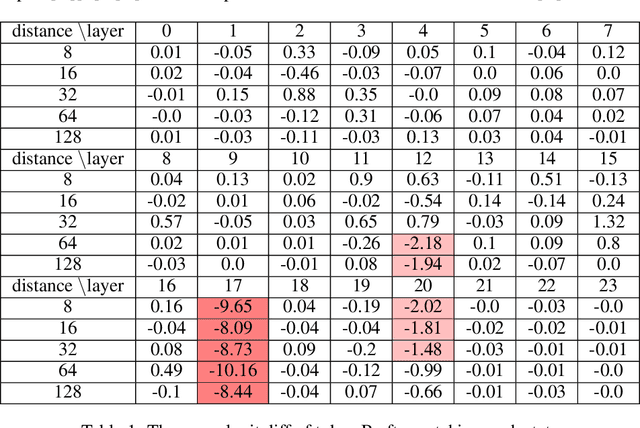
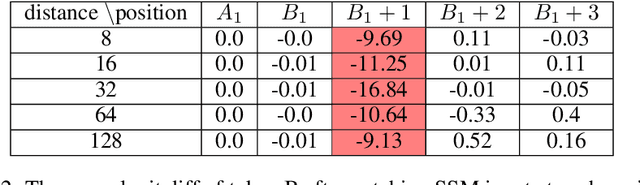

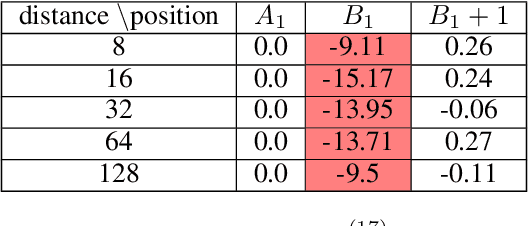
The hypothesis of Universality in interpretability suggests that different neural networks may converge to implement similar algorithms on similar tasks. In this work, we investigate two mainstream architectures for language modeling, namely Transformers and Mambas, to explore the extent of their mechanistic similarity. We propose to use Sparse Autoencoders (SAEs) to isolate interpretable features from these models and show that most features are similar in these two models. We also validate the correlation between feature similarity and Universality. We then delve into the circuit-level analysis of Mamba models and find that the induction circuits in Mamba are structurally analogous to those in Transformers. We also identify a nuanced difference we call \emph{Off-by-One motif}: The information of one token is written into the SSM state in its next position. Whilst interaction between tokens in Transformers does not exhibit such trend.
Dictionary Learning Improves Patch-Free Circuit Discovery in Mechanistic Interpretability: A Case Study on Othello-GPT
Feb 19, 2024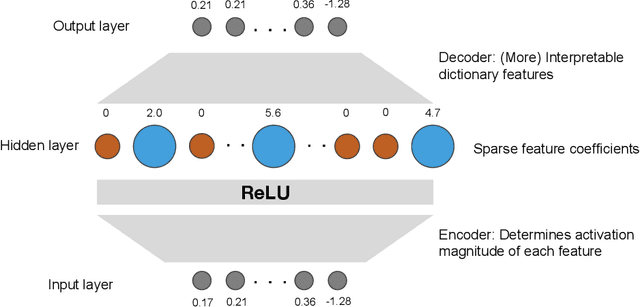

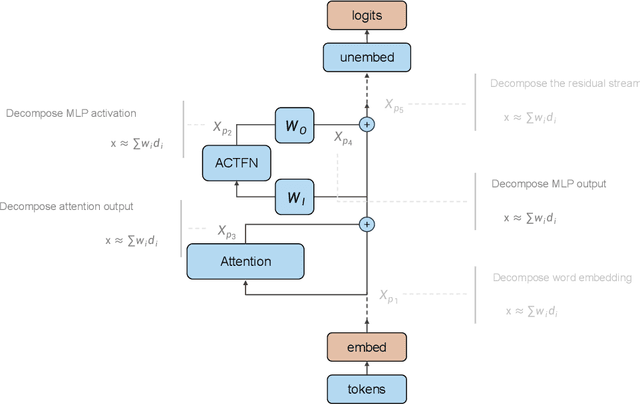
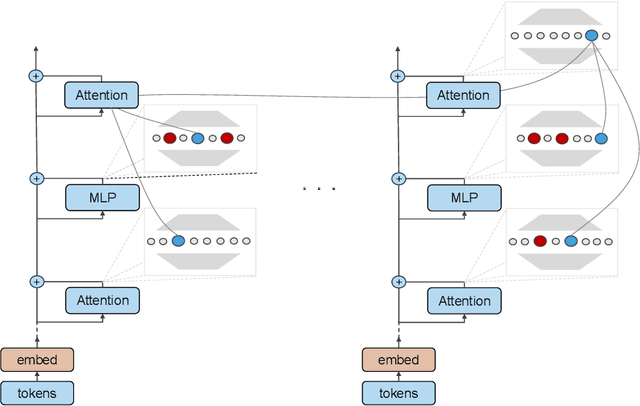
Sparse dictionary learning has been a rapidly growing technique in mechanistic interpretability to attack superposition and extract more human-understandable features from model activations. We ask a further question based on the extracted more monosemantic features: How do we recognize circuits connecting the enormous amount of dictionary features? We propose a circuit discovery framework alternative to activation patching. Our framework suffers less from out-of-distribution and proves to be more efficient in terms of asymptotic complexity. The basic unit in our framework is dictionary features decomposed from all modules writing to the residual stream, including embedding, attention output and MLP output. Starting from any logit, dictionary feature or attention score, we manage to trace down to lower-level dictionary features of all tokens and compute their contribution to these more interpretable and local model behaviors. We dig in a small transformer trained on a synthetic task named Othello and find a number of human-understandable fine-grained circuits inside of it.
CodeIE: Large Code Generation Models are Better Few-Shot Information Extractors
May 11, 2023Large language models (LLMs) pre-trained on massive corpora have demonstrated impressive few-shot learning ability on many NLP tasks. A common practice is to recast the task into a text-to-text format such that generative LLMs of natural language (NL-LLMs) like GPT-3 can be prompted to solve it. However, it is nontrivial to perform information extraction (IE) tasks with NL-LLMs since the output of the IE task is usually structured and therefore is hard to be converted into plain text. In this paper, we propose to recast the structured output in the form of code instead of natural language and utilize generative LLMs of code (Code-LLMs) such as Codex to perform IE tasks, in particular, named entity recognition and relation extraction. In contrast to NL-LLMs, we show that Code-LLMs can be well-aligned with these IE tasks by designing code-style prompts and formulating these IE tasks as code generation tasks. Experiment results on seven benchmarks show that our method consistently outperforms fine-tuning moderate-size pre-trained models specially designed for IE tasks (e.g., UIE) and prompting NL-LLMs under few-shot settings. We further conduct a series of in-depth analyses to demonstrate the merits of leveraging Code-LLMs for IE tasks.