 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWESR: Scaling and Evaluating Word-level Event-Speech Recognition
Jan 08, 2026Speech conveys not only linguistic information but also rich non-verbal vocal events such as laughing and crying. While semantic transcription is well-studied, the precise localization of non-verbal events remains a critical yet under-explored challenge. Current methods suffer from insufficient task definitions with limited category coverage and ambiguous temporal granularity. They also lack standardized evaluation frameworks, hindering the development of downstream applications. To bridge this gap, we first develop a refined taxonomy of 21 vocal events, with a new categorization into discrete (standalone) versus continuous (mixed with speech) types. Based on the refined taxonomy, we introduce WESR-Bench, an expert-annotated evaluation set (900+ utterances) with a novel position-aware protocol that disentangles ASR errors from event detection, enabling precise localization measurement for both discrete and continuous events. We also build a strong baseline by constructing a 1,700+ hour corpus, and train specialized models, surpassing both open-source audio-language models and commercial APIs while preserving ASR quality. We anticipate that WESR will serve as a foundational resource for future research in modeling rich, real-world auditory scenes.
MOSS Transcribe Diarize: Accurate Transcription with Speaker Diarization
Jan 08, 2026Speaker-Attributed, Time-Stamped Transcription (SATS) aims to transcribe what is said and to precisely determine the timing of each speaker, which is particularly valuable for meeting transcription. Existing SATS systems rarely adopt an end-to-end formulation and are further constrained by limited context windows, weak long-range speaker memory, and the inability to output timestamps. To address these limitations, we present MOSS Transcribe Diarize, a unified multimodal large language model that jointly performs Speaker-Attributed, Time-Stamped Transcription in an end-to-end paradigm. Trained on extensive real wild data and equipped with a 128k context window for up to 90-minute inputs, MOSS Transcribe Diarize scales well and generalizes robustly. Across comprehensive evaluations, it outperforms state-of-the-art commercial systems on multiple public and in-house benchmarks.
MOSS-Speech: Towards True Speech-to-Speech Models Without Text Guidance
Oct 02, 2025



Spoken dialogue systems often rely on cascaded pipelines that transcribe, process, and resynthesize speech. While effective, this design discards paralinguistic cues and limits expressivity. Recent end-to-end methods reduce latency and better preserve these cues, yet still rely on text intermediates, creating a fundamental bottleneck. We present MOSS-Speech, a true speech-to-speech large language model that directly understands and generates speech without relying on text guidance. Our approach combines a modality-based layer-splitting architecture with a frozen pre-training strategy, preserving the reasoning and knowledge of pretrained text LLMs while adding native speech capabilities. Experiments show that our model achieves state-of-the-art results in spoken question answering and delivers comparable speech-to-speech performance relative to existing text-guided systems, while still maintaining competitive text performance. By narrowing the gap between text-guided and direct speech generation, our work establishes a new paradigm for expressive and efficient end-to-end speech interaction.
CodecBench: A Comprehensive Benchmark for Acoustic and Semantic Evaluation
Aug 28, 2025



With the rise of multimodal large language models (LLMs), audio codec plays an increasingly vital role in encoding audio into discrete tokens, enabling integration of audio into text-based LLMs. Current audio codec captures two types of information: acoustic and semantic. As audio codec is applied to diverse scenarios in speech language model , it needs to model increasingly complex information and adapt to varied contexts, such as scenarios with multiple speakers, background noise, or richer paralinguistic information. However, existing codec's own evaluation has been limited by simplistic metrics and scenarios, and existing benchmarks for audio codec are not designed for complex application scenarios, which limits the assessment performance on complex datasets for acoustic and semantic capabilities. We introduce CodecBench, a comprehensive evaluation dataset to assess audio codec performance from both acoustic and semantic perspectives across four data domains. Through this benchmark, we aim to identify current limitations, highlight future research directions, and foster advances in the development of audio codec. The codes are available at https://github.com/RayYuki/CodecBench.
Dynamic and Generalizable Process Reward Modeling
Jul 23, 2025Process Reward Models (PRMs) are crucial for guiding Large Language Models (LLMs) in complex scenarios by providing dense reward signals. However, existing PRMs primarily rely on heuristic approaches, which struggle with cross-domain generalization. While LLM-as-judge has been proposed to provide generalized rewards, current research has focused mainly on feedback results, overlooking the meaningful guidance embedded within the text. Additionally, static and coarse-grained evaluation criteria struggle to adapt to complex process supervision. To tackle these challenges, we propose Dynamic and Generalizable Process Reward Modeling (DG-PRM), which features a reward tree to capture and store fine-grained, multi-dimensional reward criteria. DG-PRM dynamically selects reward signals for step-wise reward scoring. To handle multifaceted reward signals, we pioneeringly adopt Pareto dominance estimation to identify discriminative positive and negative pairs. Experimental results show that DG-PRM achieves stunning performance on prevailing benchmarks, significantly boosting model performance across tasks with dense rewards. Further analysis reveals that DG-PRM adapts well to out-of-distribution scenarios, demonstrating exceptional generalizability.
R3-RAG: Learning Step-by-Step Reasoning and Retrieval for LLMs via Reinforcement Learning
May 26, 2025



Retrieval-Augmented Generation (RAG) integrates external knowledge with Large Language Models (LLMs) to enhance factual correctness and mitigate hallucination. However, dense retrievers often become the bottleneck of RAG systems due to their limited parameters compared to LLMs and their inability to perform step-by-step reasoning. While prompt-based iterative RAG attempts to address these limitations, it is constrained by human-designed workflows. To address these limitations, we propose $\textbf{R3-RAG}$, which uses $\textbf{R}$einforcement learning to make the LLM learn how to $\textbf{R}$eason and $\textbf{R}$etrieve step by step, thus retrieving comprehensive external knowledge and leading to correct answers. R3-RAG is divided into two stages. We first use cold start to make the model learn the manner of iteratively interleaving reasoning and retrieval. Then we use reinforcement learning to further harness its ability to better explore the external retrieval environment. Specifically, we propose two rewards for R3-RAG: 1) answer correctness for outcome reward, which judges whether the trajectory leads to a correct answer; 2) relevance-based document verification for process reward, encouraging the model to retrieve documents that are relevant to the user question, through which we can let the model learn how to iteratively reason and retrieve relevant documents to get the correct answer. Experimental results show that R3-RAG significantly outperforms baselines and can transfer well to different retrievers. We release R3-RAG at https://github.com/Yuan-Li-FNLP/R3-RAG.
VisuoThink: Empowering LVLM Reasoning with Multimodal Tree Search
Apr 12, 2025Recent advancements in Large Vision-Language Models have showcased remarkable capabilities. However, they often falter when confronted with complex reasoning tasks that humans typically address through visual aids and deliberate, step-by-step thinking. While existing methods have explored text-based slow thinking or rudimentary visual assistance, they fall short of capturing the intricate, interleaved nature of human visual-verbal reasoning processes. To overcome these limitations and inspired by the mechanisms of slow thinking in human cognition, we introduce VisuoThink, a novel framework that seamlessly integrates visuospatial and linguistic domains. VisuoThink facilitates multimodal slow thinking by enabling progressive visual-textual reasoning and incorporates test-time scaling through look-ahead tree search. Extensive experiments demonstrate that VisuoThink significantly enhances reasoning capabilities via inference-time scaling, even without fine-tuning, achieving state-of-the-art performance in tasks involving geometry and spatial reasoning.
World Modeling Makes a Better Planner: Dual Preference Optimization for Embodied Task Planning
Mar 13, 2025Recent advances in large vision-language models (LVLMs) have shown promise for embodied task planning, yet they struggle with fundamental challenges like dependency constraints and efficiency. Existing approaches either solely optimize action selection or leverage world models during inference, overlooking the benefits of learning to model the world as a way to enhance planning capabilities. We propose Dual Preference Optimization (D$^2$PO), a new learning framework that jointly optimizes state prediction and action selection through preference learning, enabling LVLMs to understand environment dynamics for better planning. To automatically collect trajectories and stepwise preference data without human annotation, we introduce a tree search mechanism for extensive exploration via trial-and-error. Extensive experiments on VoTa-Bench demonstrate that our D$^2$PO-based method significantly outperforms existing methods and GPT-4o when applied to Qwen2-VL (7B), LLaVA-1.6 (7B), and LLaMA-3.2 (11B), achieving superior task success rates with more efficient execution paths.
How to Mitigate Overfitting in Weak-to-strong Generalization?
Mar 06, 2025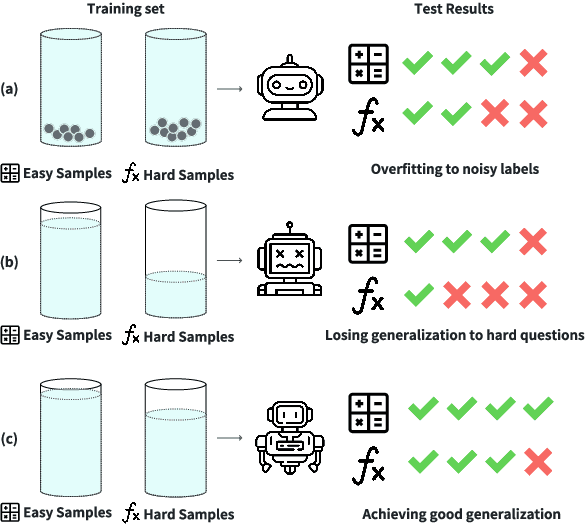
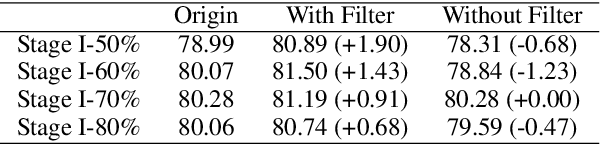
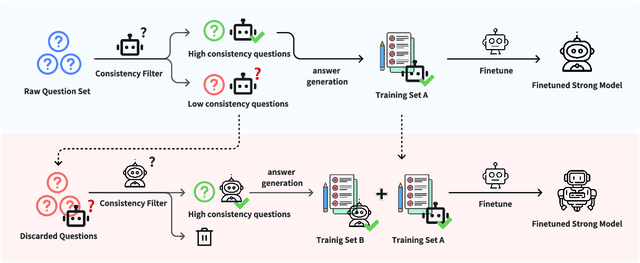
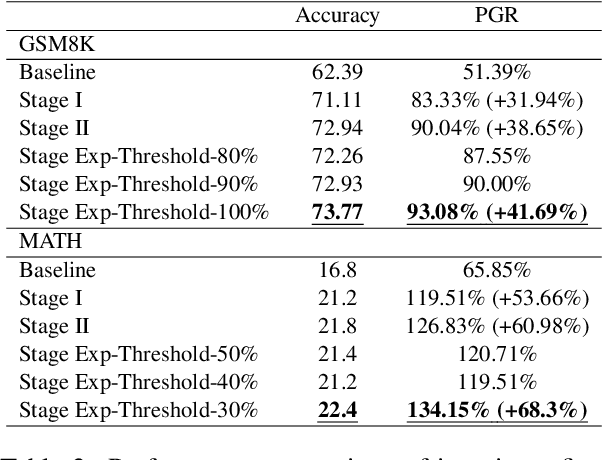
Aligning powerful AI models on tasks that surpass human evaluation capabilities is the central problem of \textbf{superalignment}. To address this problem, weak-to-strong generalization aims to elicit the capabilities of strong models through weak supervisors and ensure that the behavior of strong models aligns with the intentions of weak supervisors without unsafe behaviors such as deception. Although weak-to-strong generalization exhibiting certain generalization capabilities, strong models exhibit significant overfitting in weak-to-strong generalization: Due to the strong fit ability of strong models, erroneous labels from weak supervisors may lead to overfitting in strong models. In addition, simply filtering out incorrect labels may lead to a degeneration in question quality, resulting in a weak generalization ability of strong models on hard questions. To mitigate overfitting in weak-to-strong generalization, we propose a two-stage framework that simultaneously improves the quality of supervision signals and the quality of input questions. Experimental results in three series of large language models and two mathematical benchmarks demonstrate that our framework significantly improves PGR compared to naive weak-to-strong generalization, even achieving up to 100\% PGR on some models.
AutoLogi: Automated Generation of Logic Puzzles for Evaluating Reasoning Abilities of Large Language Models
Feb 24, 2025



While logical reasoning evaluation of Large Language Models (LLMs) has attracted significant attention, existing benchmarks predominantly rely on multiple-choice formats that are vulnerable to random guessing, leading to overestimated performance and substantial performance fluctuations. To obtain more accurate assessments of models' reasoning capabilities, we propose an automated method for synthesizing open-ended logic puzzles, and use it to develop a bilingual benchmark, AutoLogi. Our approach features program-based verification and controllable difficulty levels, enabling more reliable evaluation that better distinguishes models' reasoning abilities. Extensive evaluation of eight modern LLMs shows that AutoLogi can better reflect true model capabilities, with performance scores spanning from 35% to 73% compared to the narrower range of 21% to 37% on the source multiple-choice dataset. Beyond benchmark creation, this synthesis method can generate high-quality training data by incorporating program verifiers into the rejection sampling process, enabling systematic enhancement of LLMs' reasoning capabilities across diverse datasets.