 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedaVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently
Feb 02, 2026While Large Language Models (LLMs) excel at short-term tasks, scaling them to long-horizon agentic workflows remains challenging. The core bottleneck lies in the scarcity of training data that captures authentic long-dependency structures and cross-stage evolutionary dynamics--existing synthesis methods either confine to single-feature scenarios constrained by model distribution, or incur prohibitive human annotation costs, failing to provide scalable, high-quality supervision. We address this by reconceptualizing data synthesis through the lens of real-world software evolution. Our key insight: Pull Request (PR) sequences naturally embody the supervision signals for long-horizon learning. They decompose complex objectives into verifiable submission units, maintain functional coherence across iterations, and encode authentic refinement patterns through bug-fix histories. Building on this, we propose daVinci-Agency, which systematically mines structured supervision from chain-of-PRs through three interlocking mechanisms: (1) progressive task decomposition via continuous commits, (2) long-term consistency enforcement through unified functional objectives, and (3) verifiable refinement from authentic bug-fix trajectories. Unlike synthetic trajectories that treat each step independently, daVinci-Agency's PR-grounded structure inherently preserves the causal dependencies and iterative refinements essential for teaching persistent goal-directed behavior and enables natural alignment with project-level, full-cycle task modeling. The resulting trajectories are substantial--averaging 85k tokens and 116 tool calls--yet remarkably data-efficient: fine-tuning GLM-4.6 on 239 daVinci-Agency samples yields broad improvements across benchmarks, notably achieving a 47% relative gain on Toolathlon. Beyond benchmark performance, our analysis confirms...
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Jan 16, 2026Large Language Models (LLMs) based autonomous agents demonstrate multifaceted capabilities to contribute substantially to economic production. However, existing benchmarks remain focused on single agentic capability, failing to capture long-horizon real-world scenarios. Moreover, the reliance on human-in-the-loop feedback for realistic tasks creates a scalability bottleneck, hindering automated rollout collection and evaluation. To bridge this gap, we introduce AgencyBench, a comprehensive benchmark derived from daily AI usage, evaluating 6 core agentic capabilities across 32 real-world scenarios, comprising 138 tasks with specific queries, deliverables, and rubrics. These scenarios require an average of 90 tool calls, 1 million tokens, and hours of execution time to resolve. To enable automated evaluation, we employ a user simulation agent to provide iterative feedback, and a Docker sandbox to conduct visual and functional rubric-based assessment. Experiments reveal that closed-source models significantly outperform open-source models (48.4% vs 32.1%). Further analysis reveals significant disparities across models in resource efficiency, feedback-driven self-correction, and specific tool-use preferences. Finally, we investigate the impact of agentic scaffolds, observing that proprietary models demonstrate superior performance within their native ecosystems (e.g., Claude-4.5-Opus via Claude-Agent-SDK), while open-source models exhibit distinct performance peaks, suggesting potential optimization for specific execution frameworks. AgencyBench serves as a critical testbed for next-generation agents, highlighting the necessity of co-optimizing model architecture with agentic frameworks. We believe this work sheds light on the future direction of autonomous agents, and we release the full benchmark and evaluation toolkit at https://github.com/GAIR-NLP/AgencyBench.
AquaGS: Fast Underwater Scene Reconstruction with SfM-Free Gaussian Splatting
May 03, 2025Underwater scene reconstruction is a critical tech-nology for underwater operations, enabling the generation of 3D models from images captured by underwater platforms. However, the quality of underwater images is often degraded due to medium interference, which limits the effectiveness of Structure-from-Motion (SfM) pose estimation, leading to subsequent reconstruction failures. Additionally, SfM methods typically operate at slower speeds, further hindering their applicability in real-time scenarios. In this paper, we introduce AquaGS, an SfM-free underwater scene reconstruction model based on the SeaThru algorithm, which facilitates rapid and accurate separation of scene details and medium features. Our approach initializes Gaussians by integrating state-of-the-art multi-view stereo (MVS) technology, employs implicit Neural Radiance Fields (NeRF) for rendering translucent media and utilizes the latest explicit 3D Gaussian Splatting (3DGS) technique to render object surfaces, which effectively addresses the limitations of traditional methods and accurately simulates underwater optical phenomena. Experimental results on the data set and the robot platform show that our model can complete high-precision reconstruction in 30 seconds with only 3 image inputs, significantly enhancing the practical application of the algorithm in robotic platforms.
How to Mitigate Overfitting in Weak-to-strong Generalization?
Mar 06, 2025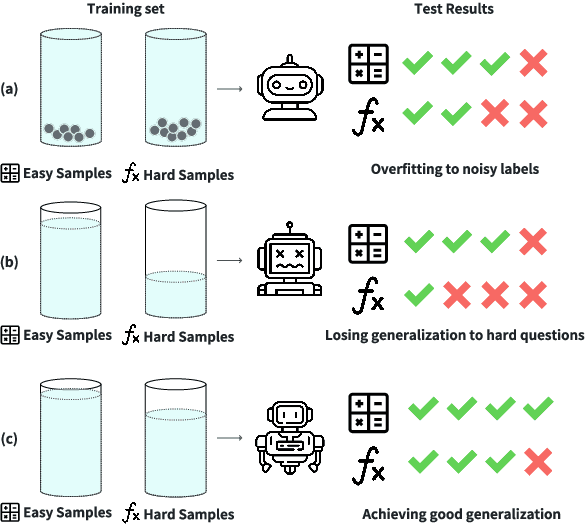
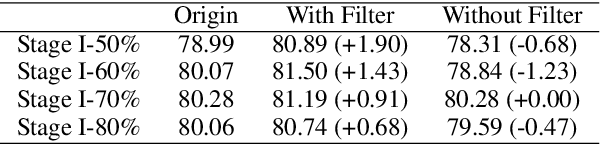
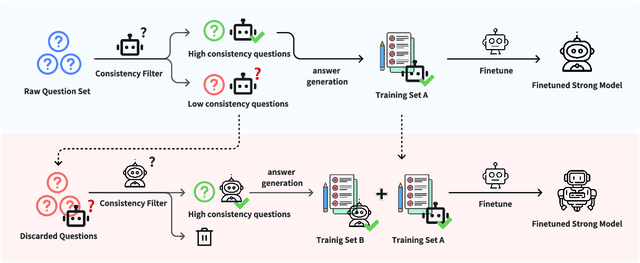
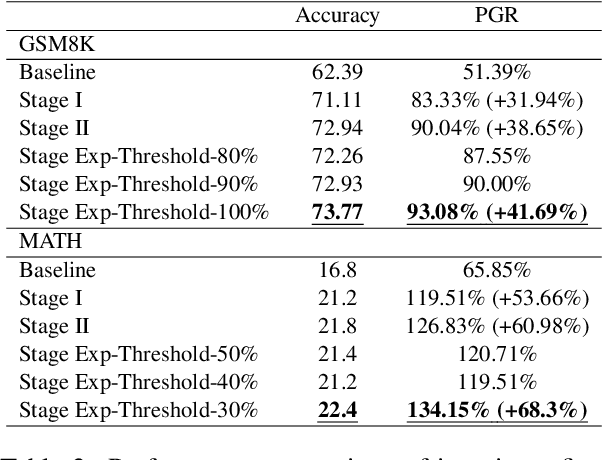
Aligning powerful AI models on tasks that surpass human evaluation capabilities is the central problem of \textbf{superalignment}. To address this problem, weak-to-strong generalization aims to elicit the capabilities of strong models through weak supervisors and ensure that the behavior of strong models aligns with the intentions of weak supervisors without unsafe behaviors such as deception. Although weak-to-strong generalization exhibiting certain generalization capabilities, strong models exhibit significant overfitting in weak-to-strong generalization: Due to the strong fit ability of strong models, erroneous labels from weak supervisors may lead to overfitting in strong models. In addition, simply filtering out incorrect labels may lead to a degeneration in question quality, resulting in a weak generalization ability of strong models on hard questions. To mitigate overfitting in weak-to-strong generalization, we propose a two-stage framework that simultaneously improves the quality of supervision signals and the quality of input questions. Experimental results in three series of large language models and two mathematical benchmarks demonstrate that our framework significantly improves PGR compared to naive weak-to-strong generalization, even achieving up to 100\% PGR on some models.