 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemaClaw: A Step Towards General-Purpose Personal AI Agents through Harness Engineering
Apr 13, 2026The rise of OpenClaw in early 2026 marks the moment when millions of users began deploying personal AI agents into their daily lives, delegating tasks ranging from travel planning to multi-step research. This scale of adoption signals that two parallel arcs of development have reached an inflection point. First is a paradigm shift in AI engineering, evolving from prompt and context engineering to harness engineering-designing the complete infrastructure necessary to transform unconstrained agents into controllable, auditable, and production-reliable systems. As model capabilities converge, this harness layer is becoming the primary site of architectural differentiation. Second is the evolution of human-agent interaction from discrete tasks toward a persistent, contextually aware collaborative relationship, which demands open, trustworthy and extensible harness infrastructure. We present SemaClaw, an open-source multi-agent application framework that addresses these shifts by taking a step towards general-purpose personal AI agents through harness engineering. Our primary contributions include a DAG-based two-phase hybrid agent team orchestration method, a PermissionBridge behavioral safety system, a three-tier context management architecture, and an agentic wiki skill for automated personal knowledge base construction.
ECHO: Efficient Chest X-ray Report Generation with One-step Block Diffusion
Apr 10, 2026Chest X-ray report generation (CXR-RG) has the potential to substantially alleviate radiologists' workload. However, conventional autoregressive vision--language models (VLMs) suffer from high inference latency due to sequential token decoding. Diffusion-based models offer a promising alternative through parallel generation, but they still require multiple denoising iterations. Compressing multi-step denoising to a single step could further reduce latency, but often degrades textual coherence due to the mean-field bias introduced by token-factorized denoisers. To address this challenge, we propose \textbf{ECHO}, an efficient diffusion-based VLM (dVLM) for chest X-ray report generation. ECHO enables stable one-step-per-block inference via a novel Direct Conditional Distillation (DCD) framework, which mitigates the mean-field limitation by constructing unfactorized supervision from on-policy diffusion trajectories to encode joint token dependencies. In addition, we introduce a Response-Asymmetric Diffusion (RAD) training strategy that further improves training efficiency while maintaining model effectiveness. Extensive experiments demonstrate that ECHO surpasses state-of-the-art autoregressive methods, improving RaTE and SemScore by \textbf{64.33\%} and \textbf{60.58\%} respectively, while achieving an \textbf{$8\times$} inference speedup without compromising clinical accuracy.
End-to-End Direction-Aware Keyword Spotting with Spatial Priors in Noisy Environments
Mar 10, 2026Keyword spotting (KWS) is crucial for many speech-driven applications, but robust KWS in noisy environments remains challenging. Conventional systems often rely on single-channel inputs and a cascaded pipeline separating front-end enhancement from KWS. This precludes joint optimization, inherently limiting performance. We present an end-to-end multi-channel KWS framework that exploits spatial cues to improve noise robustness. A spatial encoder learns inter-channel features, while a spatial embedding injects directional priors; the fused representation is processed by a streaming backbone. Experiments in simulated noisy conditions across multiple signal-to-noise ratios (SNRs) show that spatial modeling and directional priors each yield clear gains over baselines, with their combination achieving the best results. These findings validate end-to-end multi-channel spatial modeling, indicating strong potential for the target-speaker-aware detection in complex acoustic scenarios.
Adaptive Speaker Embedding Self-Augmentation for Personal Voice Activity Detection with Short Enrollment Speech
Jan 19, 2026Personal Voice Activity Detection (PVAD) is crucial for identifying target speaker segments in the mixture, yet its performance heavily depends on the quality of speaker embeddings. A key practical limitation is the short enrollment speech--such as a wake-up word--which provides limited cues. This paper proposes a novel adaptive speaker embedding self-augmentation strategy that enhances PVAD performance by augmenting the original enrollment embeddings through additive fusion of keyframe embeddings extracted from mixed speech. Furthermore, we introduce a long-term adaptation strategy to iteratively refine embeddings during detection, mitigating speaker temporal variability. Experiments show significant gains in recall, precision, and F1-score under short enrollment conditions, matching full-length enrollment performance after five iterative updates. The source code is available at https://anonymous.4open.science/r/ASE-PVAD-E5D6 .
Aggregation of Reasoning: A Hierarchical Framework for Enhancing Answer Selection in Large Language Models
May 21, 2024

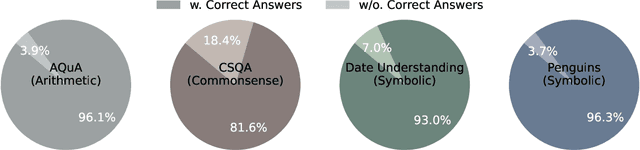
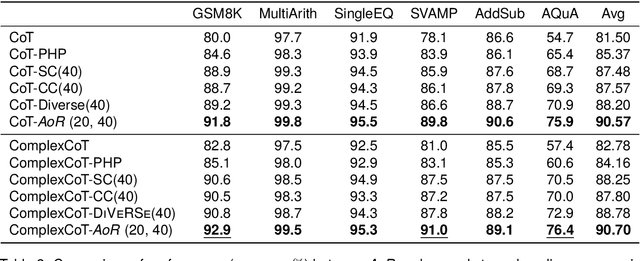
Recent advancements in Chain-of-Thought prompting have facilitated significant breakthroughs for Large Language Models (LLMs) in complex reasoning tasks. Current research enhances the reasoning performance of LLMs by sampling multiple reasoning chains and ensembling based on the answer frequency. However, this approach fails in scenarios where the correct answers are in the minority. We identify this as a primary factor constraining the reasoning capabilities of LLMs, a limitation that cannot be resolved solely based on the predicted answers. To address this shortcoming, we introduce a hierarchical reasoning aggregation framework AoR (Aggregation of Reasoning), which selects answers based on the evaluation of reasoning chains. Additionally, AoR incorporates dynamic sampling, adjusting the number of reasoning chains in accordance with the complexity of the task. Experimental results on a series of complex reasoning tasks show that AoR outperforms prominent ensemble methods. Further analysis reveals that AoR not only adapts various LLMs but also achieves a superior performance ceiling when compared to current methods.
Retrieval-Augmented Embodied Agents
Apr 17, 2024



Embodied agents operating in complex and uncertain environments face considerable challenges. While some advanced agents handle complex manipulation tasks with proficiency, their success often hinges on extensive training data to develop their capabilities. In contrast, humans typically rely on recalling past experiences and analogous situations to solve new problems. Aiming to emulate this human approach in robotics, we introduce the Retrieval-Augmented Embodied Agent (RAEA). This innovative system equips robots with a form of shared memory, significantly enhancing their performance. Our approach integrates a policy retriever, allowing robots to access relevant strategies from an external policy memory bank based on multi-modal inputs. Additionally, a policy generator is employed to assimilate these strategies into the learning process, enabling robots to formulate effective responses to tasks. Extensive testing of RAEA in both simulated and real-world scenarios demonstrates its superior performance over traditional methods, representing a major leap forward in robotic technology.
2023 Low-Power Computer Vision Challenge (LPCVC) Summary
Mar 11, 2024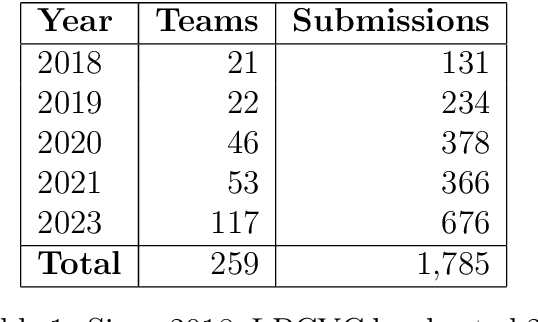

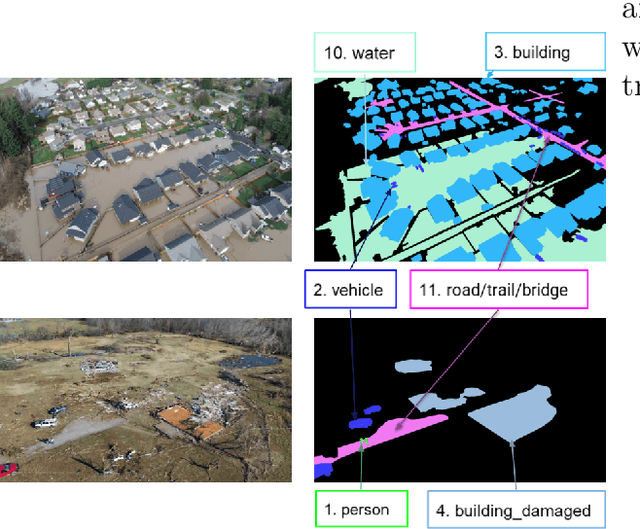
This article describes the 2023 IEEE Low-Power Computer Vision Challenge (LPCVC). Since 2015, LPCVC has been an international competition devoted to tackling the challenge of computer vision (CV) on edge devices. Most CV researchers focus on improving accuracy, at the expense of ever-growing sizes of machine models. LPCVC balances accuracy with resource requirements. Winners must achieve high accuracy with short execution time when their CV solutions run on an embedded device, such as Raspberry PI or Nvidia Jetson Nano. The vision problem for 2023 LPCVC is segmentation of images acquired by Unmanned Aerial Vehicles (UAVs, also called drones) after disasters. The 2023 LPCVC attracted 60 international teams that submitted 676 solutions during the submission window of one month. This article explains the setup of the competition and highlights the winners' methods that improve accuracy and shorten execution time.
EPSD: Early Pruning with Self-Distillation for Efficient Model Compression
Jan 31, 2024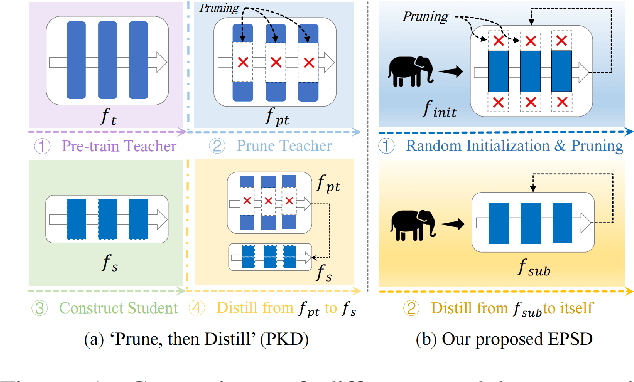
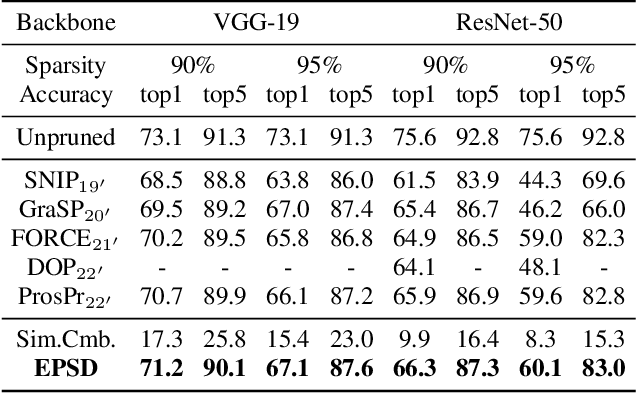
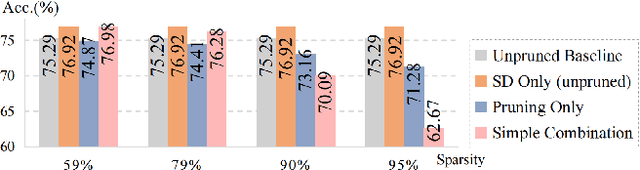
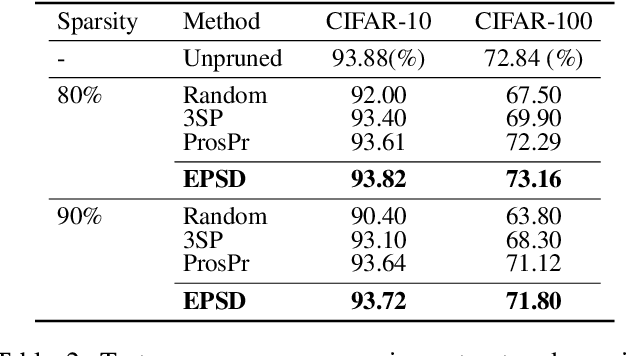
Neural network compression techniques, such as knowledge distillation (KD) and network pruning, have received increasing attention. Recent work `Prune, then Distill' reveals that a pruned student-friendly teacher network can benefit the performance of KD. However, the conventional teacher-student pipeline, which entails cumbersome pre-training of the teacher and complicated compression steps, makes pruning with KD less efficient. In addition to compressing models, recent compression techniques also emphasize the aspect of efficiency. Early pruning demands significantly less computational cost in comparison to the conventional pruning methods as it does not require a large pre-trained model. Likewise, a special case of KD, known as self-distillation (SD), is more efficient since it requires no pre-training or student-teacher pair selection. This inspires us to collaborate early pruning with SD for efficient model compression. In this work, we propose the framework named Early Pruning with Self-Distillation (EPSD), which identifies and preserves distillable weights in early pruning for a given SD task. EPSD efficiently combines early pruning and self-distillation in a two-step process, maintaining the pruned network's trainability for compression. Instead of a simple combination of pruning and SD, EPSD enables the pruned network to favor SD by keeping more distillable weights before training to ensure better distillation of the pruned network. We demonstrated that EPSD improves the training of pruned networks, supported by visual and quantitative analyses. Our evaluation covered diverse benchmarks (CIFAR-10/100, Tiny-ImageNet, full ImageNet, CUB-200-2011, and Pascal VOC), with EPSD outperforming advanced pruning and SD techniques.
LLaVA-Phi: Efficient Multi-Modal Assistant with Small Language Model
Jan 15, 2024In this paper, we introduce LLaVA-$\phi$ (LLaVA-Phi), an efficient multi-modal assistant that harnesses the power of the recently advanced small language model, Phi-2, to facilitate multi-modal dialogues. LLaVA-Phi marks a notable advancement in the realm of compact multi-modal models. It demonstrates that even smaller language models, with as few as 2.7B parameters, can effectively engage in intricate dialogues that integrate both textual and visual elements, provided they are trained with high-quality corpora. Our model delivers commendable performance on publicly available benchmarks that encompass visual comprehension, reasoning, and knowledge-based perception. Beyond its remarkable performance in multi-modal dialogue tasks, our model opens new avenues for applications in time-sensitive environments and systems that require real-time interaction, such as embodied agents. It highlights the potential of smaller language models to achieve sophisticated levels of understanding and interaction, while maintaining greater resource efficiency.The project is available at {https://github.com/zhuyiche/llava-phi}.
Is MultiWOZ a Solved Task? An Interactive TOD Evaluation Framework with User Simulator
Oct 26, 2022Task-Oriented Dialogue (TOD) systems are drawing more and more attention in recent studies. Current methods focus on constructing pre-trained models or fine-tuning strategies while the evaluation of TOD is limited by a policy mismatch problem. That is, during evaluation, the user utterances are from the annotated dataset while these utterances should interact with previous responses which can have many alternatives besides annotated texts. Therefore, in this work, we propose an interactive evaluation framework for TOD. We first build a goal-oriented user simulator based on pre-trained models and then use the user simulator to interact with the dialogue system to generate dialogues. Besides, we introduce a sentence-level and a session-level score to measure the sentence fluency and session coherence in the interactive evaluation. Experimental results show that RL-based TOD systems trained by our proposed user simulator can achieve nearly 98% inform and success rates in the interactive evaluation of MultiWOZ dataset and the proposed scores measure the response quality besides the inform and success rates. We are hoping that our work will encourage simulator-based interactive evaluations in the TOD task.